评价指标的计算:accuracy、precision、recall、F1-score等
记正样本为P,负样本为N,下表比较完整地总结了准确率accuracy、精度precision、召回率recall、F1-score等评价指标的计算方式:

(右键点击在新页面打开,可查看清晰图像)
简单版:
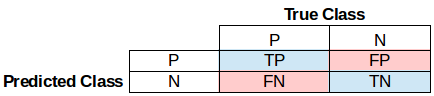
precision = TP / (TP + FP) # 预测为正的样本中实际正样本的比例
recall = TP / (TP + FN) # 实际正样本中预测为正的比例
accuracy = (TP + TN) / (P + N)
F1-score = / [( / precision) + ( / recall)]
from sklearn.metrics import accuracy_score, precision_score, recall_score def cul_accuracy_precision_recall(y_true, y_pred, pos_label=1):
return {"accuracy": float("%.5f" % accuracy_score(y_true=y_true, y_pred=y_pred)),
"precision": float("%.5f" % precision_score(y_true=y_true, y_pred=y_pred, pos_label=pos_label)),
"recall": float("%.5f" % recall_score(y_true=y_true, y_pred=y_pred, pos_label=pos_label))}
***********************************************************************************************************************************
(下面写的内容纯属个人推导,如有错误,望指正)
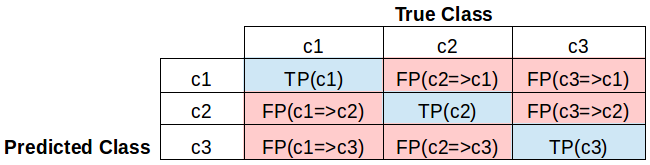
一般来说,精度和召回率是针对具体类别来计算的,例如:
precision(c1) = TP(c1) / Pred(c1) = TP(c1) / [TP(c1) + FP(c2=>c1) + FP(c3=>c1)]
recall(c1) = TP(c1) / True(c1) = TP(c1) / [TP(c1) + FP(c1=>c2) + FP(c1=>c3)]
有时需要衡量模型的整体性能,有:
total_precision = sum[TP(ci)] / sum[Pred(ci)] = [TP(c1) + TP(c2) + TP(c3)] / len(Pred)
total_recall = sum[TP(ci)] / sum[True(ci)] = [TP(c1) + TP(c2) + TP(c3)] / len(True)
total_accuracy = sum[TP(ci)] / total_num = [TP(c1) + TP(c2) + TP(c3)] / total_num
其中i取值自[1,2,...,n]
到这里很惊讶地发现,针对整体而言,一般有 len(Pred) == len(True) == total_num
也就是说, total_precision == total_recall == total_accuracy ,所以衡量模型整体性能用其中一个就可以了
针对概率输出型的的模型,很多时候会通过设置阈值梯度,得到映射关系 F(threshold) ==> (precision, recall)
在卡阈值的情况下,除了total_precision,还可以计算一个广义召回率:
generalized_recall = sum[TP(ci)] / sum[True(ci)] = [TP(c1) + TP(c2) + TP(c3)] / [len(True) + OutOfThreshold]
其中OutOfThreshold表示因低于指定阈值而被筛选去掉的样本数。
参考:
https://en.wikipedia.org/wiki/Receiver_operating_characteristic
https://www.cnblogs.com/shixiangwan/p/7215926.html?utm_source=itdadao&utm_medium=referral
评价指标的计算:accuracy、precision、recall、F1-score等的更多相关文章
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- Precision,Recall,F1的计算
Precision又叫查准率,Recall又叫查全率.这两个指标共同衡量才能评价模型输出结果. TP: 预测为1(Positive),实际也为1(Truth-预测对了) TN: 预测为0(Negati ...
- 机器学习基础梳理—(accuracy,precision,recall浅谈)
一.TP TN FP FN TP:标签为正例,预测为正例(P),即预测正确(T) TN:标签为负例,预测为负例(N),即预测正确(T) FP:标签为负例,预测为正例(P),即预测错误(F) FN:标签 ...
- BERT模型在多类别文本分类时的precision, recall, f1值的计算
BERT预训练模型在诸多NLP任务中都取得最优的结果.在处理文本分类问题时,即可以直接用BERT模型作为文本分类的模型,也可以将BERT模型的最后层输出的结果作为word embedding导入到我们 ...
- 目标检测的评价标准mAP, Precision, Recall, Accuracy
目录 metrics 评价方法 TP , FP , TN , FN 概念 计算流程 Accuracy , Precision ,Recall Average Precision PR曲线 AP计算 A ...
- Classification week6: precision & recall 笔记
华盛顿大学 machine learning :classification 笔记 第6周 precision & recall 1.accuracy 局限性 我们习惯用 accuracy ...
- 机器学习中的 precision、recall、accuracy、F1 Score
1. 四个概念定义:TP.FP.TN.FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False ...
- 【tf.keras】实现 F1 score、precision、recall 等 metric
tf.keras.metric 里面竟然没有实现 F1 score.recall.precision 等指标,一开始觉得真不可思议.但这是有原因的,这些指标在 batch-wise 上计算都没有意义, ...
- 评价指标整理:Precision, Recall, F-score, TPR, FPR, TNR, FNR, AUC, Accuracy
针对二分类的结果,对模型进行评估,通常有以下几种方法: Precision.Recall.F-score(F1-measure)TPR.FPR.TNR.FNR.AUCAccuracy 真实结果 1 ...
随机推荐
- git如何回退单个文件到某一个commit
答:操作步骤如下: 1. git log "filename" (如:git log README) 2. git reset "commit-id" &quo ...
- Linq to SQL - 撤销所有未提交的改动
在某些情况下我们需要撤销/丢弃所有未提交的改动,包括Update, Delete和Insert.context中GetChangeSet()方法可以返回当前所有未提交的改动,而我们的目标是清空Chan ...
- winlog
下载 https://www.elastic.co/downloads/beats/winlogbeat PS C:\Users\Administrator> cd 'C:\Program Fi ...
- 通过window(Navicat)访问linux中的mysql数据库
Centos安装Mysql数据库 查看我们的操作系统上是否已经安装了mysql数据库 [root@centos~]# rpm -qa | grep mysql // 这个命令就会查看该操作系统上是否已 ...
- 安迪的第一本字典 - set--sstream
#include <iostream> #include <string> #include <set> #include <sstream> usin ...
- python2.7.10 VS2015编译方法
打开 Python-2.7.10\PCbuild目录 然后设置只编译python和pythoncore: 好了,编译试一试. 出现了好几个错误.由于 VS2015 取消了 timezone 的定义,改 ...
- Kettle 数据抽取
1.创建数据库连接 2.建立转换 3.指定源数据库和目标数据库的字段映射 一定要在「输出」中勾选「指定字段」,然后点按钮「Get All fields」,再「Enter mapping」,在弹出窗口映 ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- 初学Selenium遇到的那些坑
一.遇到一个下拉选择框,可以点击继续选择: 所以click两次就可以了: 二.国际话问题 bdId.selectByIndex(index);//index位下拉框内容的下标,从0开始, 数组形式[ ...
- 网页上播放音频、视频Mp3,Mp4
昨天在处理网页上播放音频mp3,视频mp4上用了一天的时间来比较各种方案,最终还是选择了HTML5的 标签,谷歌浏览器.IE浏览器对标签的支持都很好,火狐上需要安装quicktime插件,效果比较差. ...