【分类模型评判指标 一】混淆矩阵(Confusion Matrix)
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839 略有改动,仅供个人学习使用
简介
混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。
一句话解释版本:混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。
数据分析与挖掘体系位置
混淆矩阵是评判模型结果的指标,属于模型评估的一部分。此外,混淆矩阵多用于判断分类器(Classifier)的优劣,适用于分类型的数据模型,如分类树(Classification Tree)、逻辑回归(Logistic Regression)、线性判别分析(Linear Discriminant Analysis)等方法。
在分类型模型评判的指标中,常见的方法有如下三种:
混淆矩阵(也称误差矩阵,Confusion Matrix)
ROC曲线
AUC面积 本文主要介绍第一种方法,即混淆矩阵,也称误差矩阵。
此方法在整个数据分析与挖掘体系中的位置如下图所示。

混淆矩阵的定义
混淆矩阵(Confusion Matrix),它的本质远没有它的名字听上去那么拉风。矩阵,可以理解为就是一张表格,混淆矩阵其实就是一张表格而已。
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。
我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是positive,哪些结果是negative。同时,我们通过用样本数据跑出分类型模型的结果,也可以知道模型认为这些数据哪些是positive,哪些是negative。
因此,我们就能得到这样四个基础指标,我称他们是一级指标(最底层的):
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第一类错误(Type I Error)
真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第二类错误(Type II Error)
真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
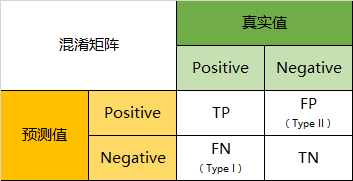
混淆矩阵的指标
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。所以当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三四象限对应位置出现的观测值肯定是越少越好。
二级指标
但是,混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又延伸了如下4个指标,我称他们是二级指标(通过最底层指标加减乘除得到的):
准确率(Accuracy)—— 针对整个模型
精确率(Precision)
灵敏度(Sensitivity):就是召回率(Recall)
特异度(Specificity)
我用表格的方式将这四种指标的定义、计算、理解进行了汇总:
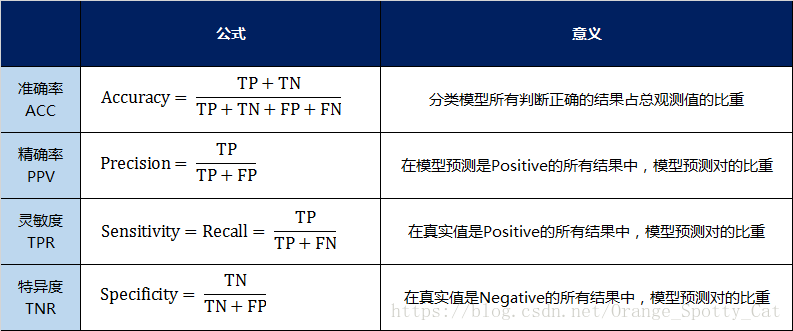
通过上面的四个二级指标,可以将混淆矩阵中数量的结果转化为0-1之间的比率。便于进行标准化的衡量。
在这四个指标的基础上在进行拓展,会产令另外一个三级指标
三级指标
这个指标叫做F1 Score。他的计算公式是:
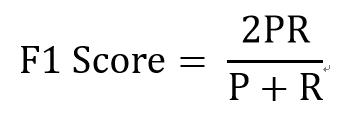
其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
混淆矩阵的实例
当分类问题是二分问题是,混淆矩阵可以用上面的方法计算。当分类的结果多于两种的时候,混淆矩阵同时适用。
下面的混淆矩阵为例,我们的模型目的是为了预测样本是什么动物,这是我们的结果:
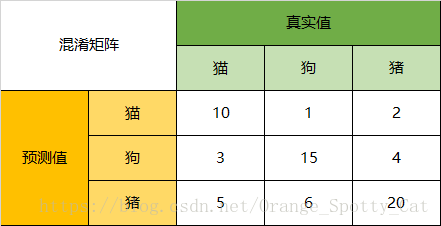
通过混淆矩阵,我们可以得到如下结论:
Accuracy
在总共66个动物中,我们一共预测对了10 + 15 + 20=45个样本,所以准确率(Accuracy)=45/66 = 68.2%。
以猫为例,我们可以将上面的图合并为二分问题:

Precision
所以,以猫为例,模型的结果告诉我们,66只动物里有13只是猫,但是其实这13只猫只有10只预测对了。模型认为是猫的13只动物里,有1条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall
以猫为例,在总共18只真猫中,我们的模型认为里面只有10只是猫,剩下的3只是狗,5只都是猪。这5只八成是橘猫,能理解。所以,Recall(猫)= 10/18 = 55.6%
Specificity
以猫为例,在总共48只不是猫的动物中,模型认为有45只不是猫。所以,Specificity(猫)= 45/48 = 93.8%。
虽然在45只动物里,模型依然认为错判了6只狗与4只猫,但是从猫的角度而言,模型的判断是没有错的。
(这里是参见了Wikipedia,Confusion Matrix的解释,https://en.wikipedia.org/wiki/Confusion_matrix)
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556) = 64.54%
同样,我们也可以分别计算猪与狗各自的二级指标与三级指标值。
【分类模型评判指标 一】混淆矩阵(Confusion Matrix)的更多相关文章
- 【分类模型评判指标 二】ROC曲线与AUC面积
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031 略有改动,仅供个人学习使用 简介 ROC曲线与AUC面积均是用来 ...
- 【机器学习】--模型评估指标之混淆矩阵,ROC曲线和AUC面积
一.前述 怎么样对训练出来的模型进行评估是有一定指标的,本文就相关指标做一个总结. 二.具体 1.混淆矩阵 混淆矩阵如图: 第一个参数true,false是指预测的正确性. 第二个参数true,p ...
- ML01 机器学习后利用混淆矩阵Confusion matrix 进行结果分析
目标: 快速理解什么是混淆矩阵, 混淆矩阵是用来干嘛的. 首先理解什么是confusion matrix 看定义,在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是 ...
- 混淆矩阵(Confusion matrix)的原理及使用(scikit-learn 和 tensorflow)
原理 在机器学习中, 混淆矩阵是一个误差矩阵, 常用来可视化地评估监督学习算法的性能. 混淆矩阵大小为 (n_classes, n_classes) 的方阵, 其中 n_classes 表示类的数量. ...
- python画混淆矩阵(confusion matrix)
混淆矩阵(Confusion Matrix),是一种在深度学习中常用的辅助工具,可以让你直观地了解你的模型在哪一类样本里面表现得不是很好. 如上图,我们就可以看到,有一个样本原本是0的,却被预测成了1 ...
- [机器学习]-分类问题常用评价指标、混淆矩阵及ROC曲线绘制方法
分类问题 分类问题是人工智能领域中最常见的一类问题之一,掌握合适的评价指标,对模型进行恰当的评价,是至关重要的. 同样地,分割问题是像素级别的分类,除了mAcc.mIoU之外,也可以采用分类问题的一些 ...
- 分类问题(三)混淆矩阵,Precision与Recall
混淆矩阵 衡量一个分类器性能的更好的办法是混淆矩阵.它基于的思想是:计算类别A被分类为类别B的次数.例如在查看分类器将图片5分类成图片3时,我们会看混淆矩阵的第5行以及第3列. 为了计算一个混淆矩阵, ...
- 分类模型的性能评价指标(Classification Model Performance Evaluation Metric)
二分类模型的预测结果分为四种情况(正类为1,反类为0): TP(True Positive):预测为正类,且预测正确(真实为1,预测也为1) FP(False Positive):预测为正类,但预测错 ...
- WEKA “Detailed Accuracy By Class”和“Confusion Matrix”含义
原文 === Summary ===(总结) Correctly Classified Instances(正确分类的实例) 45 90 % I ...
随机推荐
- [http]HTTP请求过程
我们在浏览器输入http://www.baidu.com想要进入百度首页,但是这是个域名,没法准确定位到服务器的位置,所以需要通过域名解析,把域名解析成对应的ip地址,然后通过ip地址查找目的主机.整 ...
- spring——aop详细总结1
AOP(Aspect-Oriented Programming, 面向切面编程): 是一种新的方法论, 是对传统 OOP(Object-Oriented Programming, 面向对象编程) 的补 ...
- C#基础知识 (转)
https://www.cnblogs.com/zhouzhou-aspnet/articles/2591596.html(原文地址) 本文是一个菜鸟所写,本文面向的人群就是像我这样的小菜鸟,工作一年 ...
- uni-app的H5版使用注意事项
使用方式 打开uni-app项目下的vue文件 点击菜单 运行->运行到浏览器->Chrome 在Chrome內打开调试模式(右键->检查)开启设备模拟,模拟移动设备(如果UI变形刷 ...
- JavaScript基本使用
基本使用 1.JavaScript组成 ECMAScript+BOM+DOM BOM的思想(重点) DOM的思想(重点) 2.使用<script></script>标签 doc ...
- js同步和异步
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事. JavaScript的单线程,与它的用途有关.作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作 ...
- vue cli创建脚手架
1.用vscode打开一个文件夹.在菜单栏 点击 查看-集成终端.这里可以用其他的方法比如cmd命令符调开这个界面,但是要用cd 切到要放文件的文件夹下. 2.安装好node.js 和淘宝镜像 3. ...
- 【Git】六、分支管理&冲突解决
上一节讲了如何和远端的仓库协同工作,这一节介绍一下分支 ---------------------------- 提要 //创建一个分支dev $ git branch dev //切换到dev分支 ...
- yum list报一些error的组件
1 删除那些无效的参数配置,就不再报错了
- kotlin字符串模板&条件控制
字符串模版: 小时候都有要求记日记的习惯,下面是一小学生记的日记: 很漂亮的流水账,那细分析一下这些文件其实大体都类似,只有几个不同点: 其实就是地点变了,那对于这种有规律的文字可以采用kotlin的 ...