利用Nodejs & Cheerio & Request抓取Lofter美女图片
还是参考了这篇文章:
http://cnodejs.org/topic/54bdaac4514ea9146862abee
另外有上面文章 nodejs抓取网易公开课的一些经验。
代码如下,注意其中用到了 http获取网页结果,request进行http请求,cheerio进行解析,mkdirp创建目录,fs创建文件,iconv-lite进行格式转换(此例非必须)。
curl.js:
/**
* Created by baidu on 16/10/17.
*/
var http = require("http"); function download(url, callback) {
var chunks = [];
http.get(url, function(res) {
res.on('data', function(chunk) {
chunks.push(chunk);
});
res.on('end', function () {
callback(chunks);
});
}).on('error', function () {
callback(chunks);
})
} exports.download = download;
saveimage.js
/**
* Created by baidu on 16/10/17.
*/ var fs = require('fs');
var request = require('request'); var saveImage = function(url, filename) {
console.log('Image=>' + url);
request(url).pipe(fs.createWriteStream(filename));
console.log('Save=>' + filename);
} exports.saveImage = saveImage;
HelloWorld.js
/**
* Created by baidu on 16/10/17.
*/ console.log("Hello World"); var cheerio = require('cheerio');
var curl = require('./curl');
var iconv = require('iconv-lite');
var mkdirp = require('mkdirp');
var saveimage = require('./saveimage'); //var url = 'http://open.163.com/special/opencourse/englishs1.html';
var url = 'http://loftermeirenzhi.lofter.com/tag/%E4%BA%BA%E5%83%8F?page='; var dir = './images'; mkdirp(dir, function(err) {
if (err) {
console.log(err);
}
}); curl.download(url, function (chunks) {
if (chunks) {
var data = iconv.decode(Buffer.concat(chunks), 'gbk');
var $ = cheerio.load(data);
$('a.img').each(function (i, e) {
var item = $(e).children('img').last().attr('src');
saveimage.saveImage(item, dir + '/' + item.substr(item.indexOf('.jpg')-10, 14));
});
console.log('done');
}
else {
console.log('error');
}
});
运行之后,发现基本上下载的图片文件都是空。
看了例子,将saveimage.js中的request部分做了一些修改,如下:
/**
* Created by baidu on 16/10/17.
*/ var fs = require('fs');
var request = require('request'); var saveImage = function(url, filename) {
console.log('Image=>' + url);
request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
});
console.log('Save=>' + filename);
} exports.saveImage = saveImage;
然后运行,成功,打印:
/usr/local/bin/node /Users/baidu/Documents/Data/Work/Code/Self/nodejs/helloworld/HelloWorld.js
Hello World
Image=>http://imgsize.ph.126.net/?imgurl=http://img2.ph.126.net/CiL5IULFm0TtZBjxnhcfQQ==/52072870709354180.jpg_110x110x0x90.jpg
Save=>./images/0709354180.jpg
Image=>http://imglf1.nosdn.127.net/img/SzZqcDg4Rk01VGo5cW81TEorTU5zL2dCbjBLbktBODlCSkFGSXlIdEw5dEFvSDlGaTNjZmJ3PT0.jpg?imageView&thumbnail=500x0&quality=96&stripmeta=0&type=jpg
Save=>./images/TNjZmJ3PT0.jpg
......
done
然后项目目录中,生成了images目录,其中有美女图片:
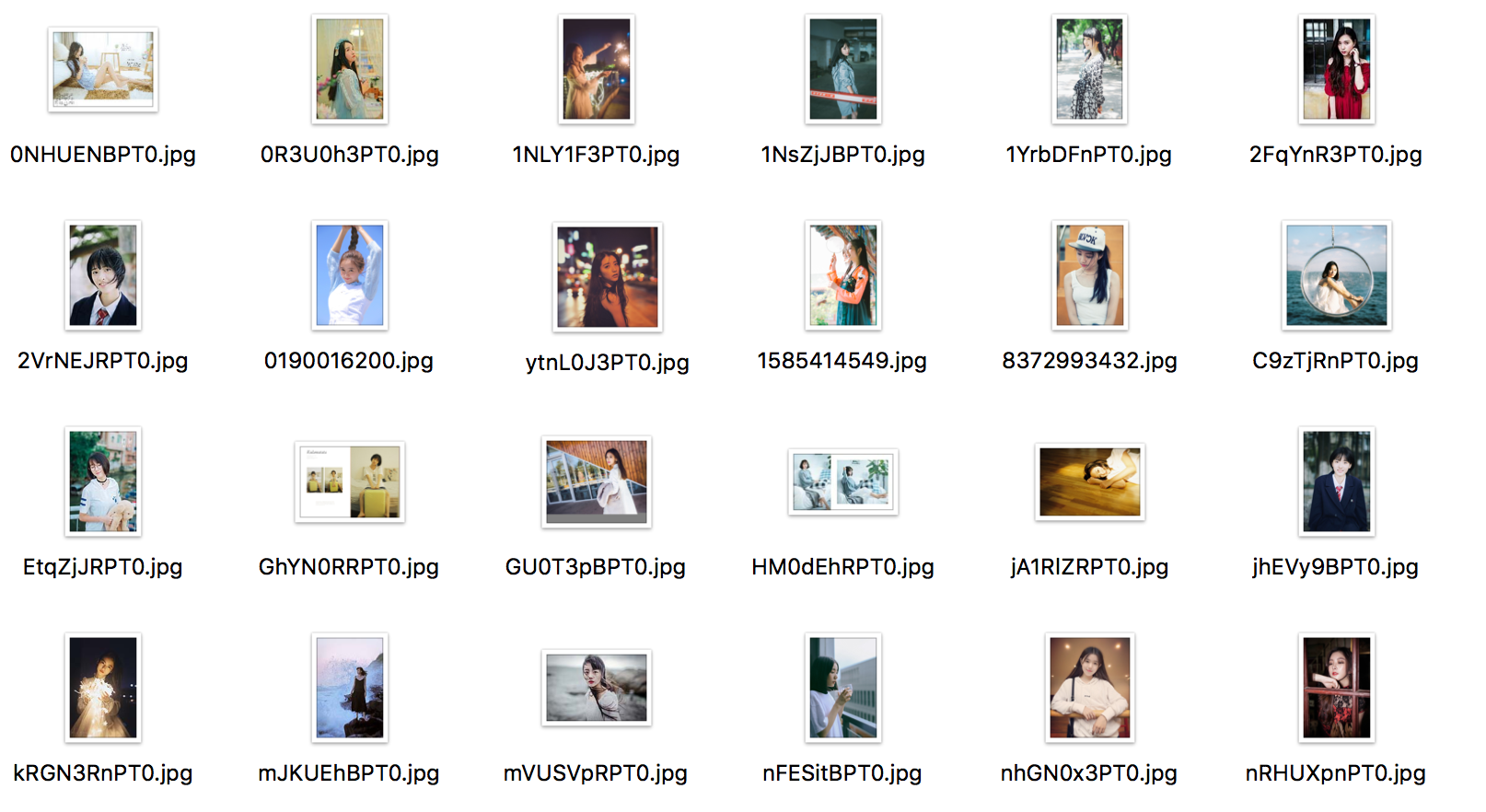
对上面这个改动能起到效果,还不是特别明白。(head一般用来判断url是否有效。)
加了head成功,也有可能是因为第一次图片虽然没下载成功,但是已经启动下载,做了缓存。实验了一下,在成功一次之后,把head命令去掉:
//request.head(url, function(err, res, body) {
request(url).pipe(fs.createWriteStream(filename));
//});
发现还是能够成功。所以有很大可能是图片加载延迟造成。
有时间的时候,要看一下,怎样避免图片下载超时导致下载失败的问题,有没有设置超时的地方。
好像在request初始化的时候,可以设置:
request({
url: jurl,
gzip: true,
timeout: xxx
})
后面再学习 Javascript Request 以及 渲染的一些内容。尤其是 phantomjs 渲染动态网页的方式。
利用Nodejs & Cheerio & Request抓取Lofter美女图片的更多相关文章
- 【Python爬虫程序】抓取MM131美女图片,并将这些图片下载到本地指定文件夹。
一.项目名称 抓取MM131美女写真图片,并将这些图片下载到本地指定文件夹. 共有6种类型的美女图片: 性感美女 清纯美眉 美女校花 性感车模 旗袍美女 明星写真 抓取后的效果图如下,每个图集是一个独 ...
- 使用nodejs+http(s)+events+cheerio+iconv-lite爬取2717网站图片数据到本地文件夹
源代码如下: //(node:9240) Warning: Setting the NODE_TLS_REJECT_UNAUTHORIZED environment variable to '0' ...
- Phantomjs+Nodejs+Mysql数据抓取(2.抓取图片)
概要 这篇博客是在上一篇博客Phantomjs+Nodejs+Mysql数据抓取(1.抓取数据) http://blog.csdn.net/jokerkon/article/details/50868 ...
- python抓取性感尤物美女图
由于是只用标准库,装了python3运行本代码就能下载到多多的美女图... 写出代码前面部分的时候,我意识到自己的函数设计错了,强忍继续把代码写完. 测试发现速度一般,200K左右的下载速度,也没有很 ...
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- (转)利用Beautiful Soup去抓取p标签下class=jstest的内容
1.利用Beautiful Soup去抓取p标签下class=jstest的内容 import io import sys import bs4 as bs import urllib.request ...
- Android利用tcpdump和wireshark抓取网络数据包
Android利用tcpdump和wireshark抓取网络数据包 主要介绍如何利用tcpdump抓取andorid手机上网络数据请求,利用Wireshark可以清晰的查看到网络请求的各个过程包括三次 ...
- Python爬虫【三】利用requests和正则抓取猫眼电影网上排名前100的电影
#利用requests和正则抓取猫眼电影网上排名前100的电影 import requests from requests.exceptions import RequestException imp ...
随机推荐
- 4:django url
一个干净的,优雅的URL 方案是一个高质量Web 应用程序的重要细节. 这节我们来看看django是如何做到干净优雅的url的 1:Django如何处理一个请求 通过ROOT_URLCONF决定根UR ...
- Codeforces 873B - Balanced Substring(思维)
题目链接:http://codeforces.com/problemset/problem/873/B 题目大意:一个字符串全部由‘0’和‘1’组成,当一段区间[l,r]内的‘0’和‘1’个数相等,则 ...
- 多路复用I/O模型epoll() 模型 代码实现
epoll模型 int epoll_create(int maxevent) //创建一个epoll的句柄 然后maxevent表示监听的数目的大小int epoll_ctl(int epollfd, ...
- angularJS的MVC的用法
1.前端MVC: M:Model,数据库 V:HTML页面 C:Control控制器 比较很有名的前端MVC框架:ExtJs 2.angularJS的MVC框架搭建 index.html代码如下: & ...
- AC日记——[Sdoi2010]粟粟的书架 bzoj 1926
1926 思路: 主席树+二分水题: 代码: #include <bits/stdc++.h> using namespace std; #define maxn 500005 #defi ...
- Python基础系列----语法、数据类型、变量、编码
1.基本语法 Python ...
- javascript实现与后端相同的枚举Enum对象
; (function (global, undefined) { global.Enum = function (namesToValues) { var enumeration = functio ...
- 7.spark Streaming 技术内幕 : 从DSteam到RDD全过程解析
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 上篇博客讨论了Spark Streaming 程序动态生成Job的过程,并留下一个疑问: ...
- phpstorm中Xdebug的使用
目 录 1.Xdebug简介 2.Xdebug的安装.操作 2.1环境搭建 2.2配置php.ini 2.3配置PhpStorm 2.4配置PHP Debug 2.5进行调试 1.Xdebug简介 ...
- 【SQL】将特定的元素按照自己所需的位置排序
Oracle中,平时我们排序常用“Order by 列名” 的方式来排序,但是有的时候我们希望这个列中的某些元素排在前面或者后面或者中间的某个位置. 这时我们可以使用Order by case whe ...