【Spark】Spark核心之弹性分布式数据集RDD
1. RDD概述
1.1 什么是RDD
(1) RDD(Resilient Distributed Dataset)弹性分布式数据集,它是Spark的基本数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
(2) 具有数据流模型的特点:自动容错、位置感知性调度、可伸缩性。
(3) 查询速度快:在执行多个查询时,可以显示的将工作集缓存到内存中,后续的查询能够重用缓存的工作集。
1.2 RDD的属性
打开Spark源代码,源码的注释中对RDD的描述如下图。
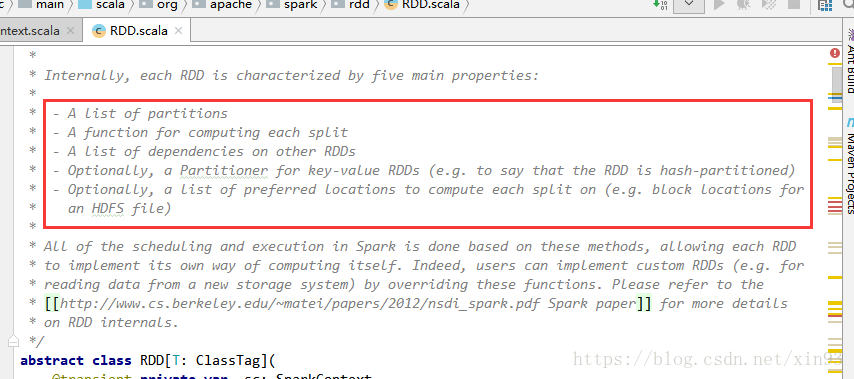
(1) A list of partitions
一系列的分区
(2) A function for computing each split
每个函数作用于一个分区
(3) A list of dependencies on other RDDs
RDD与RDD之间有依赖关系(宽依赖、窄依赖)
(4) Optionally, a Partitioner for key-value RDDs(e.g. to say that the RDD is hash-partitioned)
如果RDD是key-value形式的,会有一个分区器(Partioner)作用在这个RDD,分区器会决定该RDD的数据放在哪个子RDD的分区上
(5) Optionally, a list of preferred locations to compute each splite on (e.g. block locations for an HDFS file)
在计算每一个分区时,会有一个优先的位置,一个列表存储每个Partition的优先位置
2. RDD编程API
2.1 RDD的算子有两种类型,
(1) Transformation: 不会马上计算结果,只会记住每个应用到基础数据集上的转换操作,只有发生一个需要返回结果给Driver的动作时,才会真正触发计算。即:RDD中所有的转换操作都是延迟加载的,能让Spark更有效率的运行。
(2) Action:会立即触发运算
2.2 常用的算子
对算子的更详细使用解释请参考我的另一篇博文:
博文地址:https://blog.csdn.net/xin93/article/details/80546765
2.2.1 Transformation
|
转换 |
含义 |
|
map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
|
mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Iterator[T]) => Iterator[U] |
|
sample(withReplacement, fraction, seed) |
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
|
union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
|
intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
|
distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
|
groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
|
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
|
|
sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
|
cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
|
cartesian(otherDataset) |
笛卡尔积 |
|
pipe(command, [envVars]) |
|
|
coalesce(numPartitions) |
|
|
repartition(numPartitions) |
|
|
repartitionAndSortWithinPartitions(partitioner) |
2.2.2 常用的Action算子
|
动作 |
含义 |
|
reduce(func) |
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
|
collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
|
count() |
返回RDD的元素个数 |
|
first() |
返回RDD的第一个元素(类似于take(1)) |
|
take(n) |
返回一个由数据集的前n个元素组成的数组 |
|
takeSample(withReplacement,num, [seed]) |
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
|
takeOrdered(n, [ordering]) |
takeOrdered和top类似,只不过以和top相反的顺序返回元素 |
|
saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
|
saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
|
saveAsObjectFile(path) |
|
|
countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
|
foreach(func) |
在数据集的每一个元素上,运行函数func进行更新。 |
3. RDD的依赖关系
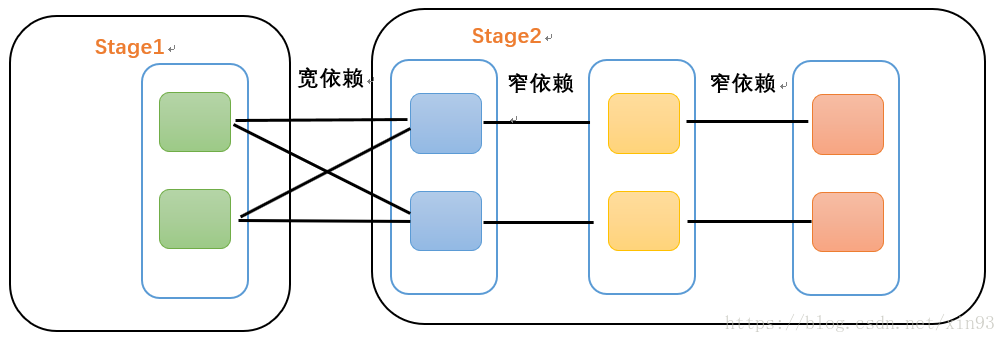
3.1 窄依赖
每个父RDD的Partition最多被子RDD的一个Partition使用,即:独生子女
3.2 宽依赖
宽依赖是Spark划分Stage的依据。每个父RDD的Partition被子RDD的多个Partition使用,即:有多个子女
关于Spark源码中是如何切分Stage的,请参考我的另一篇博文:
博文地址:https://blog.csdn.net/xin93/article/details/80674497
3. RDD的缓存
RDD提供两种方法进行缓存 persist( ) 和 cache( ),这两种方法不会立即进行缓存,而是在后面触发了action计算时才会将RDD真正缓存在计算节点的内存中供后面使用。
通过查看Spark源代码,详细如下图:

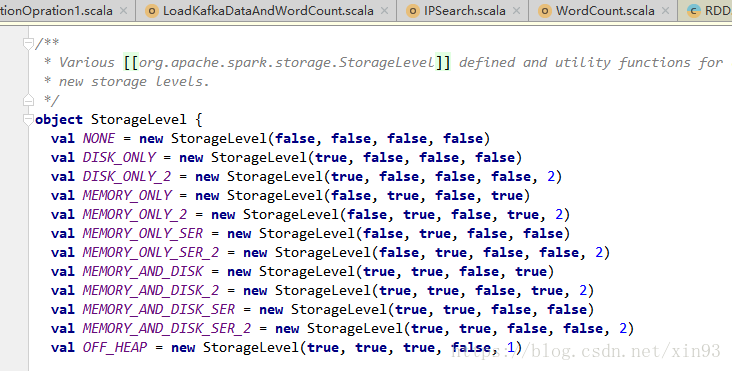
可以看到,cache( )方法实际上也是调用persist( )方法实现的缓存功能。而默认的存储级别是StorageLevel.MEMORY_ONLY,也就是只在内存中存储一份。
在源码中还提供了如下种类的缓存方式可供用户使用。
【Spark】Spark核心之弹性分布式数据集RDD的更多相关文章
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark弹性分布式数据集RDD
RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现.RDD是Spark最核心 ...
- 弹性分布式数据集RDD概述
[Spark]弹性分布式数据集RDD概述 弹性分布数据集RDD RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作 ...
- [Berkeley]弹性分布式数据集RDD的介绍(RDD: A Fault-Tolerant Abstraction for In-Memory Cluster Computing 论文翻译)
摘要: 本文提出了分布式内存抽象的概念--弹性分布式数据集(RDD,Resilient Distributed Datasets).它同意开发者在大型集群上运行基于内存的计算.RDD适用于两种 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- Spark - RDD(弹性分布式数据集)
org.apache.spark.rddRDDabstract class RDD[T] extends Serializable with Logging A Resilient Distribut ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
随机推荐
- Newtonsoft.Json code
序列化 Product product = new Product(); product.ExpiryDate = new DateTime(2008, 12, 28); JsonSerializer ...
- 【Leetcode】【Medium】Binary Tree Inorder Traversal
Given a binary tree, return the inorder traversal of its nodes' values. For example:Given binary tre ...
- windows10 如何关闭快速关机功能电源选项
点击右下角的电池 -> power and sleep setting -> choose what the power buttons do -> change settings ...
- January 27 2017 Week 4 Friday
Procrastination is the thief of time. 拖延是时光之贼. Procrastination is the thief of time, besides, it is ...
- libevent使用event_new和不使用的两种方法
写两个简单的demo,对照一下各自的方法 #include <sys/types.h> #include <event2/event-config.h> #include &l ...
- SOJ4480 Easy Problem IV (并查集)
Time Limit: 3000 MS Memory Limit: 131072 K Description 据说 你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任 ...
- Join Resig's “Simple JavaScript Inheritance ”
======================Enein翻译========================= John Resig 写了一篇关于 JavaScript 里类似其它语 ...
- Mybatis——实体类属性名和数据库字段名不同时的解决方案
数据库的字段: 对应的实体类: 方案一: 在XML映射文件中使用的resultMap,优点:可以被重复使用. <resultMap id="BaseResultMap" ty ...
- Qgis里的查询过滤
查询过虑实现方式 通过给getFeatures()传递 QgsFeatureRequest对象,实现数据的过虑,下边是一个查询的例子: request = QgsFeatureRequest() re ...
- Spring 通过XML配置装配Bean
使用XML装配Bean需要定义对于的XML,需要引入对应的XML模式(XSD)文件,这些文件会定义配置Spring Bean的一些元素,简单的配置如下: <?xml version=" ...