【Spark】Spark核心之弹性分布式数据集RDD
1. RDD概述
1.1 什么是RDD
(1) RDD(Resilient Distributed Dataset)弹性分布式数据集,它是Spark的基本数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
(2) 具有数据流模型的特点:自动容错、位置感知性调度、可伸缩性。
(3) 查询速度快:在执行多个查询时,可以显示的将工作集缓存到内存中,后续的查询能够重用缓存的工作集。
1.2 RDD的属性
打开Spark源代码,源码的注释中对RDD的描述如下图。
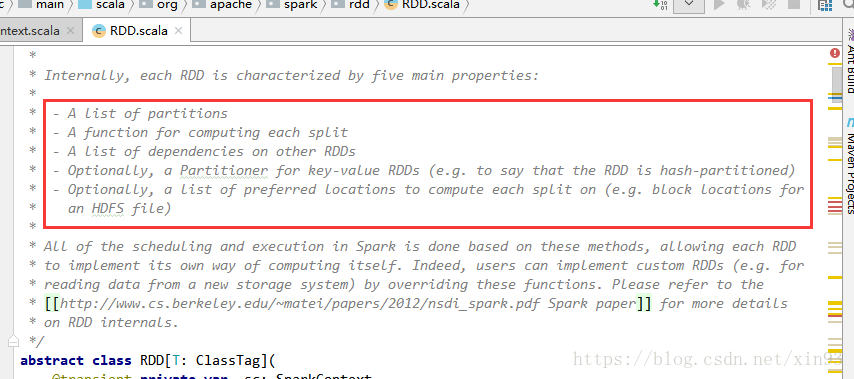
(1) A list of partitions
一系列的分区
(2) A function for computing each split
每个函数作用于一个分区
(3) A list of dependencies on other RDDs
RDD与RDD之间有依赖关系(宽依赖、窄依赖)
(4) Optionally, a Partitioner for key-value RDDs(e.g. to say that the RDD is hash-partitioned)
如果RDD是key-value形式的,会有一个分区器(Partioner)作用在这个RDD,分区器会决定该RDD的数据放在哪个子RDD的分区上
(5) Optionally, a list of preferred locations to compute each splite on (e.g. block locations for an HDFS file)
在计算每一个分区时,会有一个优先的位置,一个列表存储每个Partition的优先位置
2. RDD编程API
2.1 RDD的算子有两种类型,
(1) Transformation: 不会马上计算结果,只会记住每个应用到基础数据集上的转换操作,只有发生一个需要返回结果给Driver的动作时,才会真正触发计算。即:RDD中所有的转换操作都是延迟加载的,能让Spark更有效率的运行。
(2) Action:会立即触发运算
2.2 常用的算子
对算子的更详细使用解释请参考我的另一篇博文:
博文地址:https://blog.csdn.net/xin93/article/details/80546765
2.2.1 Transformation
|
转换 |
含义 |
|
map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
|
mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Iterator[T]) => Iterator[U] |
|
sample(withReplacement, fraction, seed) |
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
|
union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
|
intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
|
distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
|
groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
|
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
|
|
sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
|
cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
|
cartesian(otherDataset) |
笛卡尔积 |
|
pipe(command, [envVars]) |
|
|
coalesce(numPartitions) |
|
|
repartition(numPartitions) |
|
|
repartitionAndSortWithinPartitions(partitioner) |
2.2.2 常用的Action算子
|
动作 |
含义 |
|
reduce(func) |
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
|
collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
|
count() |
返回RDD的元素个数 |
|
first() |
返回RDD的第一个元素(类似于take(1)) |
|
take(n) |
返回一个由数据集的前n个元素组成的数组 |
|
takeSample(withReplacement,num, [seed]) |
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
|
takeOrdered(n, [ordering]) |
takeOrdered和top类似,只不过以和top相反的顺序返回元素 |
|
saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
|
saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
|
saveAsObjectFile(path) |
|
|
countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
|
foreach(func) |
在数据集的每一个元素上,运行函数func进行更新。 |
3. RDD的依赖关系
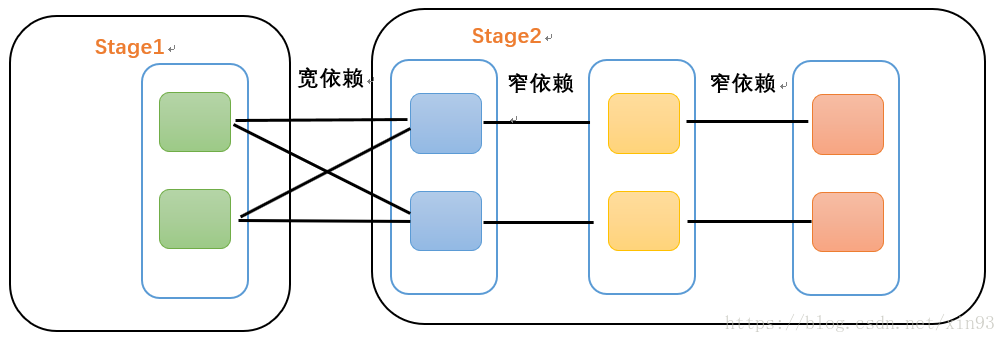
3.1 窄依赖
每个父RDD的Partition最多被子RDD的一个Partition使用,即:独生子女
3.2 宽依赖
宽依赖是Spark划分Stage的依据。每个父RDD的Partition被子RDD的多个Partition使用,即:有多个子女
关于Spark源码中是如何切分Stage的,请参考我的另一篇博文:
博文地址:https://blog.csdn.net/xin93/article/details/80674497
3. RDD的缓存
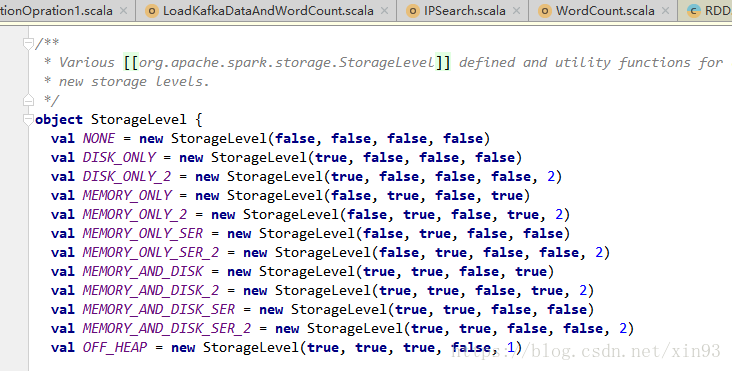
RDD提供两种方法进行缓存 persist( ) 和 cache( ),这两种方法不会立即进行缓存,而是在后面触发了action计算时才会将RDD真正缓存在计算节点的内存中供后面使用。
通过查看Spark源代码,详细如下图:

可以看到,cache( )方法实际上也是调用persist( )方法实现的缓存功能。而默认的存储级别是StorageLevel.MEMORY_ONLY,也就是只在内存中存储一份。
在源码中还提供了如下种类的缓存方式可供用户使用。
【Spark】Spark核心之弹性分布式数据集RDD的更多相关文章
- Spark核心类:弹性分布式数据集RDD及其转换和操作pyspark.RDD
http://blog.csdn.net/pipisorry/article/details/53257188 弹性分布式数据集RDD(Resilient Distributed Dataset) 术 ...
- spark系列-2、Spark 核心数据结构:弹性分布式数据集 RDD
一.RDD(弹性分布式数据集) RDD 是 Spark 最核心的数据结构,RDD(Resilient Distributed Dataset)全称为弹性分布式数据集,是 Spark 对数据的核心抽象, ...
- Spark弹性分布式数据集RDD
RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现.RDD是Spark最核心 ...
- 弹性分布式数据集RDD概述
[Spark]弹性分布式数据集RDD概述 弹性分布数据集RDD RDD(Resilient Distributed Dataset)是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作 ...
- [Berkeley]弹性分布式数据集RDD的介绍(RDD: A Fault-Tolerant Abstraction for In-Memory Cluster Computing 论文翻译)
摘要: 本文提出了分布式内存抽象的概念--弹性分布式数据集(RDD,Resilient Distributed Datasets).它同意开发者在大型集群上运行基于内存的计算.RDD适用于两种 ...
- RDD内存迭代原理(Resilient Distributed Datasets)---弹性分布式数据集
Spark的核心RDD Resilient Distributed Datasets(弹性分布式数据集) Spark运行原理与RDD理论 Spark与MapReduce对比,MapReduce的计 ...
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
Spark的核心RDD (Resilient Distributed Datasets弹性分布式数据集) 原文链接:http://www.cnblogs.com/yjd_hycf_space/p/7 ...
- Spark - RDD(弹性分布式数据集)
org.apache.spark.rddRDDabstract class RDD[T] extends Serializable with Logging A Resilient Distribut ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
随机推荐
- 使用cocostudio 需要在Android.mk文件的配置
直接贴上Android.mk文件吧. 对了,是cocos2d3.0的,不知道2.x是否一样. LOCAL_PATH := $(call my-dir) include $(CLEAR_VARS) LO ...
- LeetCode总结 -- 一维动态规划篇
这篇文章的主题是动态规划, 主要介绍LeetCode中一维动态规划的题目, 列表如下: Climbing StairsDecode WaysUnique Binary Search TreesMaxi ...
- 纯CSS画的基本图形
图形包括基本的矩形.圆形.椭圆.三角形.多边形,也包括稍微复杂一点的爱心.钻石.阴阳八卦等.当然有一些需要用到CSS3的属性,所以在你打开这篇文章的时候,我希望你用的是firefox或者chrome, ...
- Oracle 12C pluggable database自启动
实验环境创建了两个PDB,本实验实现在开启数据库时,实现pluggable database PDB2自启动: 原始环境: SQL> shu immediateDatabase closed.D ...
- July 21st 2017 Week 29th Friday
If you want to fly too high in relation to the horizon forget. 要想飞得高,就该把地平线忘掉. Always keep our eyes ...
- C++中类与结构体的区别
相信有一点专业知识的人都知道,C语言是一种结构化语言.它层次清晰,便于按模块化方式组织程序,易于调试和维护.在很大程度上,标准C++是标准C的超集.实际上,所有C程序也是C++程序,然而,两者之间有少 ...
- day13 面向对象练习
//1 public class Area_interface { public static void main(String[] args) { Rect r = new Rect(15, 12) ...
- 解决SpringMVC拦截器拦截静态资源的问题。
在使用SpringMVC进行开发的时候,遇到了以下代码不能执行的情况.而且我已经正确导入了JQuery框架. <script type="text/javascript"&g ...
- FRP-Functional Reactive Programming-函数响应式编程
响应式编程是一种面向数据流和变化传播的编程范式: 响应式编程和函数式编程的融合: 响应式编程为内核:函数式编程为工具: 流的概念先天适合函数式编程. Some quotes from the arti ...
- UVa 1349 - Optimal Bus Route Design(二分图最佳完美匹配)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...