Learn ZYNQ(10) – zybo cluster word count
1.配置环境说明
spark:5台zybo板,192.168.1.1master,其它4台为slave
hadoop:192.168.1.1(外接SanDisk )
2.单节点hadoop测试:
如果出现内存不足情况如下:
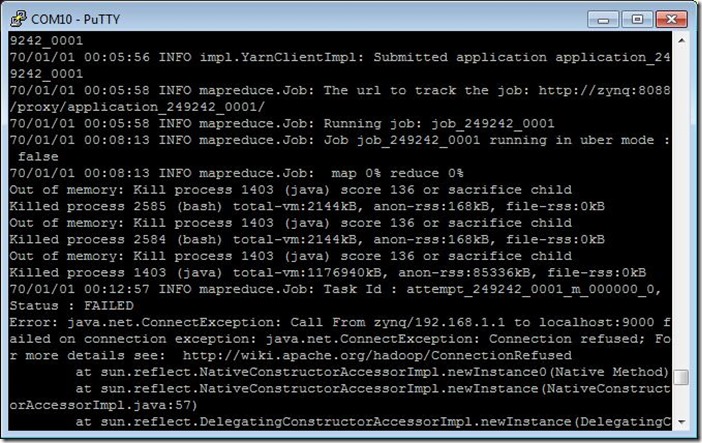
查看当前虚拟内存容量:
free -m
cd /mnt
mkdir swap
cd swap/
创建一个swap文件
dd if=/dev/zero of=swapfile bs=1024 count=1000000
把生成的文件转换成swap文件
mkswap swapfile
激活swap文件
swapon swapfile
free -m
通过测试:


3.spark + hadoop 测试
SPARK_MASTER_IP=192.168.1.1 ./sbin/start-all.sh

MASTER=spark://192.168.1.1:7077 ./bin/pyspark
file = sc.textFile("hdfs://192.168.1.1:9000/in/file")
counts = file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://192.168.1.1:9000/out/mycount")
counts.saveAsTextFile("/mnt/mycount")
counts.collect()

counts.collect()

错误1:
java.net.ConnectException: Call From zynq/192.168.1.1 to spark1:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
这是由于我们用root启动hadoop,而spark要远程操作hadoop系统,没有权限引起的
解决:如果是测试环境,可以取消hadoop hdfs的用户权限检查。打开etc/hadoop/hdfs-site.xml,找到dfs.permissions属性修改为false(默认为true)OK了。
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
4.附:我的配置文件
go.sh:
#! /bin/sh - mount /dev/sda1 /mnt/
cd /mnt/swap/
swapon swapfile
free -m cd /root/hadoop-2.4.0/
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start secondarynamenode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver jps
while [ `netstat -ntlp | grep 9000` -eq `echo` ]
do
sleep 1
done
netstat -ntlp
echo hadoop start successfully cd /root/spark-0.9.1-bin-hadoop2
SPARK_MASTER_IP=192.168.1.1 ./sbin/start-all.sh
jps
while [ `netstat -ntlp | grep 7077` -eq `echo` ]
do
sleep 1
done
netstat -ntlp
echo spark start successfully
/etc/hosts
#127.0.0.1 localhost zynq
192.168.1.1 spark1 localhost zynq
#192.168.1.1 spark1
192.168.1.2 spark2
192.168.1.3 spark3
192.168.1.4 spark4
192.168.1.5 spark5
192.168.1.100 sparkMaster
#::1 localhost ip6-localhost ip6-loopback
/etc/profile
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:$PATH
export JAVA_HOME=/usr/lib/jdk1.7.0_55
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/root/hadoop-2.4.0 export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop ifconfig eth2 hw ether 00:0a:35:00:01:01
ifconfig eth2 192.168.1.1/24 up
HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property> </configuration>
HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/mnt/hadoop/tmp</value>
</property>
</configuration>
HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property> <property>
<name>dfs.namenode.rpc-address</name>
<value>192.168.1.1:9000</value>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/namenode</value>
</property>
</configuration>
done
Learn ZYNQ(10) – zybo cluster word count的更多相关文章
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
- Learn ZYNQ (9)
创建zybo cluster的spark集群(计算层面): 1.每个节点都是同样的filesystem,mac地址冲突,故: vi ./etc/profile export PATH=/usr/loc ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- Word Count作业
Word Count作业 一.个人Gitee地址:https://gitee.com/Changyu-Guo 二.项目简介 该项目主要是模拟Linux上面的wc命令,基本要求如下: 命令格式: wc. ...
- Word Count
Word Count 一.个人Gitee地址:https://gitee.com/godcoder979/(该项目完整代码在这里) 二.项目简介: 该项目是一个统计文件字符.单词.行数等数目的应用程序 ...
- Want to write a book? Use word count to stay on track
http://paloalto.patch.com/groups/maria-murnanes-blog/p/bp--want-to-write-a-book-use-word-count-to-st ...
- Hadoop AWS Word Count 样例
在AWS里用Elastic Map Reduce 开一个Cluster 然后登陆master node并编译下面程序: import java.io.IOException; import java. ...
- Hadoop Word Count程序
Hadoop Word Count程序 pom.xml文件: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns ...
- 课堂练习 Word count
1. 团队介绍 团队成员:席梦寒,胡琦 2. 项目计划 我们选第一.二个功能点进行编程. 具体计划: (1).首先爬取网站内容及网页长度: (2).对爬取的文件内容进行word count操作: 3. ...
随机推荐
- ZOJ 3703 Happy Programming Contest
偏方记录背包里的物品.....每个背包的价值+0.01 Happy Programming Contest Time Limit: 2 Seconds Memory Limit: 65536 ...
- jQuery入门(4)jQuery中的Ajax应用
jQuery入门(1)jQuery中万能的选择器 jQuery入门(2)使用jQuery操作元素的属性与样式 jQuery入门(3)事件与事件对象 jQuery入门(4)jQuery中的Ajax()应 ...
- ajax请求webservice的过程中遇到的问题总结
前台用ajax的post方法,无法请求到webservice中的方法的时候,需要在配置文件中添加 web.config文件中的 <system.web> 节点下加入:<webServ ...
- java基础知识(四)java内存机制
Java内存管理:深入Java内存区域 上面的文章对于java的内存管理机制讲的非常细致,在这里我们只是为了便于后面内容的理解,对java内存机制做一个简单的梳理. 程序计数器:当前线程所执行的字节码 ...
- DAY6 使用ping钥匙临时开启SSH:22端口,实现远程安全SSH登录管理就这么简单
设置防火墙策略时,关于SSH:22访问权限,我们常常会设置服务器只接受某个固定IP(如公司IP)访问,但是当我们出差或在家情况需要登录服务器怎么办呢? 常用两种解决方案:1.通过VPN操作登录主机: ...
- Maven 入门 (1)—— 安装
Maven 入门 (1)—— 安装 http://blog.csdn.net/kakashi8841/article/details/17371837 1.下载maven安装包 http://mave ...
- C#转义字符(Z)
所有的ASCII码都可以用“\”加数字(一般是8进制数字)来表示.而C中定义了一些字母前加"\"来表示常见的那些不能显示的ASCII字符,如\0,\t,\n等,就称为转义字符,因为 ...
- Unity 3D学习之《Unity 3D 手机游戏开发》1
P10: 设置断点步骤02,在Project窗口右键(是在下图中的红色区域,点右键)选择[Sync Mono Develop Project],打开MonoDevelop编辑器 P11: " ...
- js中选定元素slice()
选定元素slice() slice() 方法可从已有的数组中返回选定的元素. 语法 arrayObject.slice(start,end) 参数说明: 1.返回一个新的数组,包含从 start 到 ...
- oracle 11g安装过程中问题:找不到WFMLRSVCApp.ear
网上的方法是将两个压缩包解压到同一个目录中,我的方法是不再此解压,麻烦,直接将解压出的内容剪切过去,方便省事,原理也是相同的. 解决方法: 将win64_11gR2_database_2of2解压 ...