MapReduce计算模型二
之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍mapreduce计算模型能用于解决什么问题及有什么巧妙优化。
MapReduce到底解决什么问题?
MapReduce准确的说,它不是一个产品,而是一种解决问题的思路,能够用分治策略来解决问题。例如:网页抓取、日志处理、索引倒排、查询请求汇总等等问题。通过分治法,将一个大规模的问题,分解成多个小规模的问题(分),多个小规模问题解决,再统筹小问题的解(合),就能够解决大规模的问题。最早在单机的体系下计算,当输入数据量巨大的时候,处理很慢。如何能够在短时间内完成处理,很容易想到的思路是,将这些计算分布在成百上千的主机上,但此时,会遇到各种复杂的问题,例如:并发计算、数据分发、错误处理、数据分布、负载均衡、集群管理与通信等,将这些问题综合起来将是比较复杂的问题了,而Google为了方便用户使用系统,提供给了用户很少的接口,去解决复杂的问题。
(1) Map函数接口:处理一个基于key/value(后简称k/v)的数据对(pair)数据集合,同时也输出基于k/v的数据集合。
(2) Reduce函数接口:用来合并Map输出的k/v数据集合
假设我们要统计大量文档中单词出现的次数。
Map
输入K/V:pair(文档名称,文档内容)
输出K/V:pair(单词,1)
Reduce
输入K/V:pair(单词,1)
输出K/V:pair(单词,总计数)
Map伪代码:
Map(list<pair($docName, $docContent)>){//如果有多个Map进程,输入可以是一个pair,不是一个list
foreach(pair in list)
foreach($word in $docContent)
print pair($word, 1); // 输出list<k,v>
}
Reduce伪代码:
Reduce(list<pair($word, $count)>){//大量(word,1)(即使有多个Reduce进程,输入也是list<pair>,因为它的输入是Map的输出)
map<string,int> result;
foreach(pair in list)
if result.isExist($word)
result[$word] += $count;
else
result[$word] = 1;
foreach($keyin result)
print pair($key, result[$key]); //输出list<k,v>
}
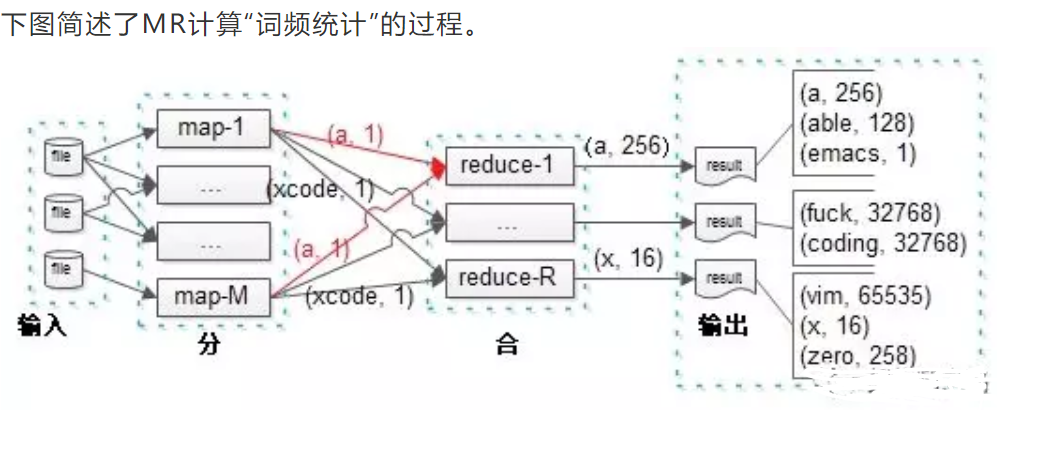
可以看到,R个reduce实例并发进行处理,直接输出最后的计数结果。需要理解的是,由于这是业务计算的最终结果,一个单词的计数不会出现在两个实例里。即:如果(a, 256)出现在了实例1的输出里,就一定不会出现在其他实例的输出里,否则的话,还需要合并,就不是最终结果。
再看中间步骤,map到reduce的过程,M个map实例的输出,会作为R个reduce实例的输入。
问题一:每个map都有可能输出(a, 1),而最终结果(a, 256)必须由一个reduce输出,那如何保证每个map输出的同一个key,落到同一个reduce上去呢?
这就是“分区函数”的作用。分区函数是使用MapReduce的用户按所需实现的,决定map输出的每一个key应当落到哪个reduce上的函数。如果用户没有实现,会使用默认分区函数。为了保证每一个reduce实例都能够差不多时间结束工作任务,分区函数的实现要点是:尽量负载均衡,即数据均匀分摊,防止数据倾斜造成部分reduce节点数据饥饿。如果数据不是负载均衡的,那么有些reduce实例处理的单词多,有些reduce处理的单词少,这样就可能出现所有reduce实例都处理结束,最后等待一个需要长时间处理的reduce情况。
问题二:每个map都有可能输出多个(a, 1),这样就增大了网络带宽资源以及reduce的计算资源,怎么办?
这就是“合并函数”的作用。有时,map产生的中间key的重复数据比重很大,可以提供给用户一个自定义函数,在一个map实例完成工作后,本地就做一次合并,这样将大大节约网络传输与reduce计算资源。合并函数在每个map任务结束前都会执行一次,一般来说,合并函数与reduce函数是一样的,区别是:合并函数是执行map实例本地数据合并,而reduce函数是执行最终的合并,会收集多个map实例的数据。对于词频统计应用,合并函数可以将:一个map实例的多个(a, 1)合并成一个(a, count)输出。
问题三:如何确定文件到map的输入呢?
随意即可,只要负载均衡,均匀切分输入文件大小就行,不用管分到哪个map实例都能正确处理。
问题四:map和reduce可能会产生很多磁盘io,将更适用于离线计算,完成离线作业。
MapReduce计算模型二的更多相关文章
- MapReduce计算模型的优化
MapReduce 计算模型的优化涉及了方方面面的内容,但是主要集中在两个方面:一是计算性能方面的优化:二是I/O操作方面的优化.这其中,又包含六个方面的内容. 1.任务调度 任务调度是Hadoop中 ...
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- MapReduce 计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- 第四篇:MapReduce计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- 【MapReduce】二、MapReduce编程模型
通过前面的实例,可以基本了解MapReduce对于少量输入数据是如何工作的,但是MapReduce主要用于面向大规模数据集的并行计算.所以,还需要重点了解MapReduce的并行编程模型和运行机制 ...
- 【MapReduce】经常使用计算模型具体解释
前一阵子參加炼数成金的MapReduce培训,培训中的作业样例比較有代表性,用于解释问题再好只是了. 有一本国外的有关MR的教材,比較有用.点此下载. 一.MapReduce应用场景 MR能解决什么问 ...
- 第二步:将LAD结果的属性值二(多)值化,投入计算模型
一文详解LDA主题模型 - 达观数据 - SegmentFault 思否 https://segmentfault.com/a/1190000012215533 SELECT COUNT(1) FRO ...
- 重要 | Spark和MapReduce的对比,不仅仅是计算模型?
[前言:笔者将分上下篇文章进行阐述Spark和MapReduce的对比,首篇侧重于"宏观"上的对比,更多的是笔者总结的针对"相对于MapReduce我们为什么选择Spar ...
随机推荐
- 【UOJ#77】A+B Problem
传送门 题目描述 略 Sol 看到选择黑白收益不同,然后还可能有代价. 我们想到用网络流解决,并且这应该是用总可能收益-最小割得到答案. 考虑初步建图,发现那个限制可以直接 \(n^2\) 解决. 我 ...
- 风控MIS那些事
信贷风险管理应基于数据进行决策,MIS则是通过对数据的加工与展示,给决策者提供参考. 管理信息系统(ManagementInformation System,MIS)是进行信息的 收集.传输.加工.储 ...
- 故障检测、性能调优与Java类加载机制
故障检测.性能调优与Java类加载机制 故障检测.性能调优 用什么工具可以查出内存泄露 (1)MerroyAnalyzer:一个功能丰富的java堆转储文件分析工具,可以帮助你发现内存漏洞和减少内存消 ...
- vue-cli3.0的配置
转自 https://www.cnblogs.com/sangzs/p/9543242.html module.exports = { // 基本路径 baseUrl: '/', // 输出文件目录 ...
- Python 函数Ⅲ
默认参数 调用函数时,默认参数的值如果没有传入,则被认为是默认值.下例会打印默认的age,如果age没有被传入: 以上实例输出结果: 不定长参数 你可能需要一个函数能处理比当初声明时更多的参数.这些参 ...
- Python抽象类(abc模块)
1.抽象类概念 抽象类是一个特殊的类,只能被继承,不能实例化 2.为什么要有抽象类 其实在未接触抽象类概念时,我们可以构造香蕉.苹果.梨之类的类,然后让它们继承水果这个基类,水果的基类包含一个eat函 ...
- mysql ALTER TABLE语句 语法
mysql ALTER TABLE语句 语法 作用:用于在已有的表中添加.修改或删除列.无铁芯直线电机 语法:添加列:ALTER TABLE table_name ADD column_name da ...
- python 输出一个随机数
题目:输出一个随机数. 程序分析:使用 random 模块. #!/user/bin/env python #coding:utf-8 import random print random.rando ...
- 目标检测Object Detection概述(Tensorflow&Pytorch实现)
1999:SIFT 2001:Cascades 2003:Bag of Words 2005:HOG 2006:SPM/SURF/Region Covariance 2007:PASCAL VOC 2 ...
- http三次握手,四次挥手
本文经过借鉴书籍资料.他人博客总结出的知识点,欢迎提问 序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生:给字节编上序号后 ...