chapter02 K近邻分类器对Iris数据进行分类预测
寻找与待分类的样本在特征空间中距离最近的K个已知样本作为参考,来帮助进行分类决策。
与其他模型最大的不同在于:该模型没有参数训练过程。无参模型,高计算复杂度和内存消耗。
#coding=utf8 # 从sklearn.datasets 导入 iris数据加载器。 from sklearn.datasets import load_iris # 从sklearn.model_selection中导入train_test_split用于数据分割。 from sklearn.model_selection import train_test_split # 从sklearn.preprocessing里选择导入数据标准化模块。 from sklearn.preprocessing import StandardScaler # 从sklearn.neighbors里选择导入KNeighborsClassifier,即K近邻分类器。 from sklearn.neighbors import KNeighborsClassifier # 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。 from sklearn.metrics import classification_report iris = load_iris() # 从使用train_test_split,利用随机种子random_state采样25%的数据作为测试集。 X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=33) # 对训练和测试的特征数据进行标准化。 ss = StandardScaler() X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test) # 使用K近邻分类器对测试数据进行类别预测,预测结果储存在变量y_predict中。 knc = KNeighborsClassifier() knc.fit(X_train, y_train) y_predict = knc.predict(X_test) # 使用模型自带的评估函数进行准确性测评。 print 'The accuracy of K-Nearest Neighbor Classifier is', knc.score(X_test, y_test) print classification_report(y_test, y_predict, target_names=iris.target_names)
结果:
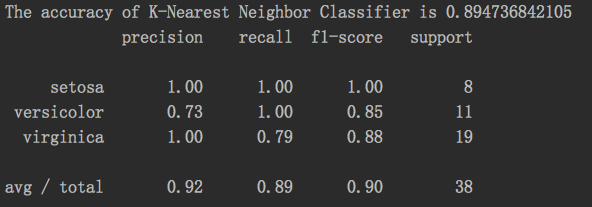
chapter02 K近邻分类器对Iris数据进行分类预测的更多相关文章
- 机器学习之路: python k近邻分类器 KNeighborsClassifier 鸢尾花分类预测
使用python语言 学习k近邻分类器的api 欢迎来到我的git查看源代码: https://github.com/linyi0604/MachineLearning from sklearn.da ...
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- 最近邻分类器,K近邻分类器,线性分类器
转自:https://blog.csdn.net/oldmao_2001/article/details/90665515 最近邻分类器: 通俗来讲,计算测试样本与所有样本的距离,将测试样本归为距离最 ...
- sklearn.neighbors.KNeighborsClassifier(k近邻分类器)
KNeighborsClassifier参数说明KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', lea ...
- Python机器学习(基础篇---监督学习(k近邻))
K近邻 假设我们有一些携带分类标记的训练样本,分布于特征空间中,对于一个待分类的测试样本点,未知其类别,按照‘近朱者赤近墨者黑’,我们需要寻找与这个待分类的样本在特征空间中距离最近的k个已标记样本作为 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- sklearn机器学习算法--K近邻
K近邻 构建模型只需要保存训练数据集即可.想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”. 1.K近邻分类 #第三步导入K近邻模型并实例化KN对象 from skl ...
- 1. cs231n k近邻和线性分类器 Image Classification
第一节课大部分都是废话.第二节课的前面也都是废话. First classifier: Nearest Neighbor Classifier 在一定时间,我记住了输入的所有的图片.在再次输入一个图片 ...
随机推荐
- 卡内基梅隆大学软件工程研究所先后制定用于评价软件系统成熟度的模型CMM和CMMI
SEI(美国卡内基梅隆大学软件工程研究所(Software Engineering Institute, SEI))开发的CMM模型有: 用于软件的(SW-CMM;SW代表'software即软件') ...
- 基于Socket的Android手机视频实时传输
首先,简单介绍一下原理.主要是在手机客户端 (Android)通过实现Camera.PreviewCallback接口,在其onPreviewFrame重载函数里面获取摄像头当前图像数据, 然后通过S ...
- English trip V1 - 1.How Do You Feel Now? Teacher:Lamb Key:形容词(Adjectives)
In this lesson you will learn to describe people, things, and feelings.在本课中,您将学习如何描述人,事和感受. STARTER ...
- android--------ListView和ExpandableListView的侧滑删除操作
本案例主要实现了ListView和ExpandableListView的侧滑删除操作功能 效果图: ListView的Adapter类 private class SlideAdapter exten ...
- boruvka算法
算法正确性证明: 1.最优性:最小边一定包含在生成树中. 2.合法性:一定不会构成环.如果存在环说明一个点的最小连边有两个,显然矛盾. 算法时间复杂度证明: 每执行一次算法,所有联通块的大小都至少为2 ...
- Homebrew cask
在MacOS中用Homebrew安装软件很方便, 但用 brew install 安装的软件并不会在Launchpad中创建快捷方式, 这很不方便. 所以, 可以用 brew cask install ...
- 最全面的mac下的android studio快捷键
Action Mac OSX Win/Linux 注释代码(//) Cmd + / Ctrl + / 注释代码(/**/) Cmd + Option + / Ctrl + Alt + / 格式化代码 ...
- 自定义实现spark的分区函数
有时自己的业务需要自己实现spark的分区函数 以下代码是实现一个自定义spark分区的demo 实现的功能是根据key值的最后一位数字,写到不同的文件 例如: 10写入到part-00000 11写 ...
- 铺音out1
1◆ 单个 c k s tʃ g gg g dʒ 2◆ 多个 si dʒ su wr w wh sc s ph f gh ck ʃ ch sh tc ...
- sql server2008 如何获取上月、上周、昨天、今天、本周、本月的查询周期(通过存储过程)
我这边有一个需求要统计订单数据,需要统计订单的上传日期,统计的模块大概是 那么上月.上周.昨天.今天.本周.本月应该是怎样呢? 1.数据分析 因为今天是动态数据,我要查月份(上月.本月),应该是一个日 ...