sklearn机器学习算法--K近邻
K近邻
构建模型只需要保存训练数据集即可。想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”。
1、K近邻分类
#第三步导入K近邻模型并实例化KN对象
from sklearn.neighbors import KNeighborsClassifier
#其中n_neighbors为近邻数量
clf = KNeighborsClassifier(n_neighbors=3)
#第四步对训练集进行训练
clf.fit(X_train,y_train)
#查看训练集和测试集的精确度
clf.score(X_train,y_train)
#建立一个有一行三列组成的图组,每个图的大小是10×3
fig, axes = plt.subplots(1,3,figsize=(10,3))
for n_neighbors,ax in zip([1,3,9],axes):
#实例化模型对象并对数据进行训练
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X,y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax)
ax.set_title("{} neighbor(s)".format(n_neighbors))
ax.set_xlabel("feature 0")
ax.set_ylabel("feature 1")
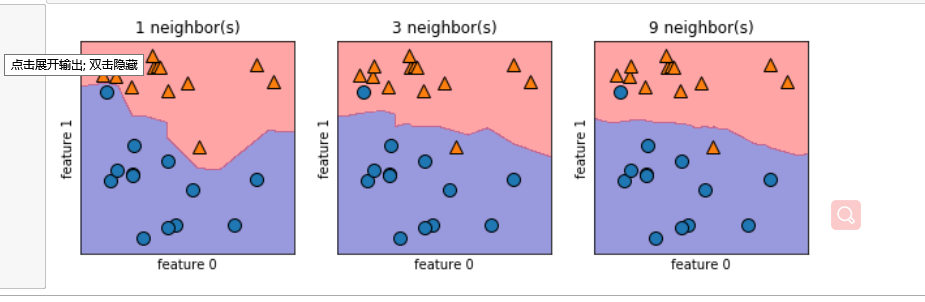
针对乳腺癌数据进行不同近邻的精确度分析
#加载乳腺癌数据
from sklearn.datasets import load_breast_cancer
#提取数据
cancer = load_breast_cancer()
#第一步将数据分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(cancer.data,cancer.target,random_state = 0)
#实例化不同近邻的KN对象
neighbors_settings = range(1,11)
training_accuracy = []
test_accuracy = []
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X_train,y_train)
training_accuracy.append(clf.score(X_train,y_train))
test_accuracy.append(clf.score(X_test,y_test))
plt.plot(neighbors_settings,training_accuracy,label='training accuracy')
plt.plot(neighbors_settings,test_accuracy,label='test accuracy')
plt.legend()
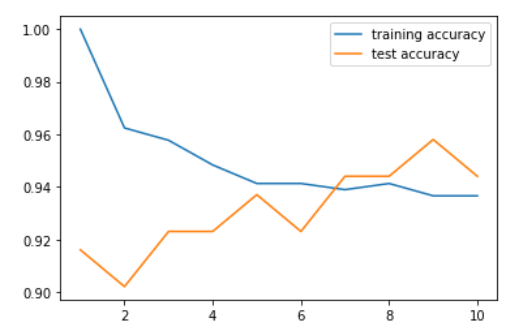
2、K近邻回归
针对wave数据进行K近邻回归演示
#导入wave数据
X,y = mglearn.datasets.make_wave()
#将数据分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y, random_state = 0)
#导入KN模型
from sklearn.neighbors import KNeighborsRegressor
#实例化KN模型
reg = KNeighborsRegressor(n_neighbors=3)
#对训练集进行训练
reg.fit(X_train,y_train)
#查看模型的精度
reg.score(X_test,y_test)
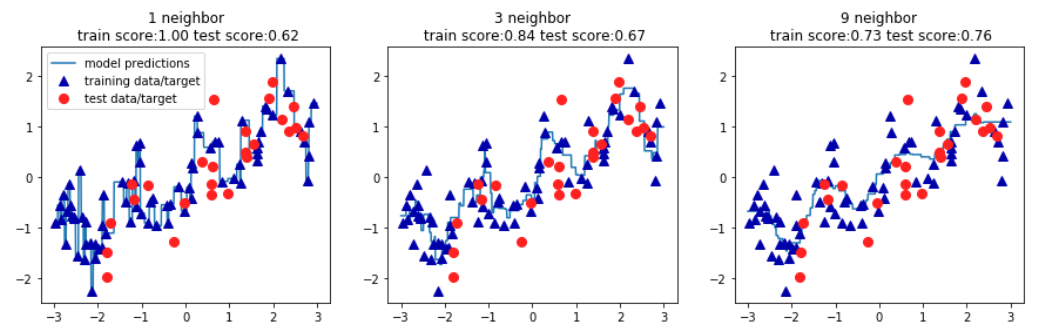
#创建一个有一行三列组成的图组,每个图的大小为15×4
fig, axes = plt.subplots(1,3,figsize=(15,4))
#创建1000个数据点,分布在-3和3之间
lines=np.linspace(-3,3,1000).reshape(-1,1)
for n_neighbors, ax in zip([1,3,9],axes):
reg = KNeighborsRegressor(n_neighbors=n_neighbors).fit(X_train,y_train)
ax.plot(lines,reg.predict(lines))
ax.plot(X_train,y_train,'^',c=mglearn.cm2(0),markersize=8)
ax.plot(X_test,y_test,'o',c=mglearn.cm2(1),markersize=8)
ax.set_title('{} neighbor\n train score:{:.2f} test score:{:.2f}'.format(n_neighbors,reg.score(X_train,y_train),
reg.score(X_test,y_test)))
axes[0].legend(['model predictions','training data/target','test data/target'])
sklearn机器学习算法--K近邻的更多相关文章
- 每日一个机器学习算法——k近邻分类
K近邻很简单. 简而言之,对于未知类的样本,按照某种计算距离找出它在训练集中的k个最近邻,如果k个近邻中多数样本属于哪个类别,就将它判决为那一个类别. 由于采用k投票机制,所以能够减小噪声的影响. 由 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
随机推荐
- nginx学习资料整理一
一.安装运行 1.1.安装环境支撑 1.gcc 环境,一般情况linux 系统自带该环境,也可自行下载安装使用新版本: 2.pcre 环境,一般需自行安装,其是一个perl库,包含正则表达式等功能,h ...
- 是时候扔掉cmder, 换上Windows Terminal
作为一个Windows的长期用户,一直没有给款好用的终端,知道遇到了 cmder,它拯救一个习惯用Windows敲shell命令的人. 不用跟我安利macOS真香!公司上班一直用macOS,一方面确实 ...
- Rocket - diplomacy - BaseNode
https://mp.weixin.qq.com/s/eOgNLi_MJ8HJOpepGaaW8Q 简单介绍BaseNode的实现. 1. You cannot create a n ...
- Rocket - decode - SimplifyDC
https://mp.weixin.qq.com/s/4uWqBRrMVG6FlnBKmw8U-w 介绍SimplifyDC如何简化解码逻辑. 1. 使用 简化从mint和m ...
- (Java实现) 组合的输出
问题 B: [递归入门]组合的输出 时间限制: 1 Sec 内存限制: 128 MB 题目描述 排列与组合是常用的数学方法,其中组合就是从n个元素中抽出r个元素(不分顺序且r < = n),我们 ...
- Java实现 蓝桥杯 算法训练 最大最小公倍数
算法训练 最大最小公倍数 时间限制:1.0s 内存限制:256.0MB 问题描述 已知一个正整数N,问从1~N中任选出三个数,他们的最小公倍数最大可以为多少. 输入格式 输入一个正整数N. 输出格式 ...
- Java实现 蓝桥杯 算法提高 判断名次
算法提高 判断名次 时间限制:1.0s 内存限制:256.0MB 问题描述 某场比赛过后,你想要知道A~E五个人的排名是什么,于是要求他们每个人说了一句话.(经典的开头---_-!)得了第1名的人23 ...
- Java实现 LeetCode 477 汉明距离总和
477. 汉明距离总和 两个整数的 汉明距离 指的是这两个数字的二进制数对应位不同的数量. 计算一个数组中,任意两个数之间汉明距离的总和. 示例: 输入: 4, 14, 2 输出: 6 解释: 在二进 ...
- Java实现 洛谷 P1090 合并果子
import java.io.BufferedInputStream; import java.util.Arrays; import java.util.Scanner; public class ...
- Java实现 蓝桥杯 算法提高最小方差生成树
1 问题描述 给定带权无向图,求出一颗方差最小的生成树. 输入格式 输入多组测试数据.第一行为N,M,依次是点数和边数.接下来M行,每行三个整数U,V,W,代表连接U,V的边,和权值W.保证图连通.n ...