DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control
1 前言
Deep Reinforcement Learning可以说是当前深度学习领域最前沿的研究方向,研究的目标即让机器人具备决策及运动控制能力。话说人类创造的机器灵活性还远远低于某些低等生物,比如蜜蜂。。DRL就是要干这个事,而是关键是使用神经网络来进行决策控制。
因此,考虑了一下,决定推出DRL前沿系列,第一时间推送了解到的DRL前沿,主要是介绍最新的研究成果,不讲解具体方法(考虑到博主本人也没办法那么快搞懂)。也因此,本文对于完全不了解这个领域,或者对这个领域感兴趣的童鞋都适合阅读。
下面进入正题。
2 Benchmarking Deep Reinforcement Learning for Continuous Control
文章出处:http://arxiv.org/abs/1604.06778
时间:2016年4月25日
开源软件地址:https://github.com/rllab/rllab
这篇文章不是什么创新算法的文章,但却是极其重要的一篇文章,看到文章的第一眼就能看出来。这篇文章针对DRL在连续控制领域的问题弄了一个Benchmark,而且,关键是作者把程序开源了,按照作者的原话就是
To encourage adoption by other researchers!
在这篇文章中,或者说这个开源软件包中,作者将主流及前沿的几个用于连续控制领域的算法都用python复现了,然后将算法应用在31种不同难度的连续控制问题上。
那么一共分了四类任务:
1)简单任务:让倒立摆保持平衡之类
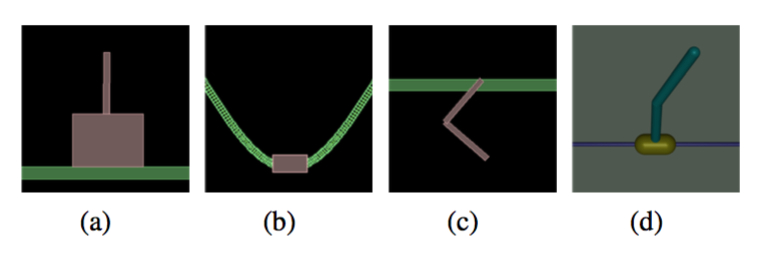
2)运动任务:让里面的虚拟生物往前跑,越快越好!
3)不完全可观察任务:即虚拟生物只能得到有限的感知信息,比如只知道每个关节的位置但不知道速度
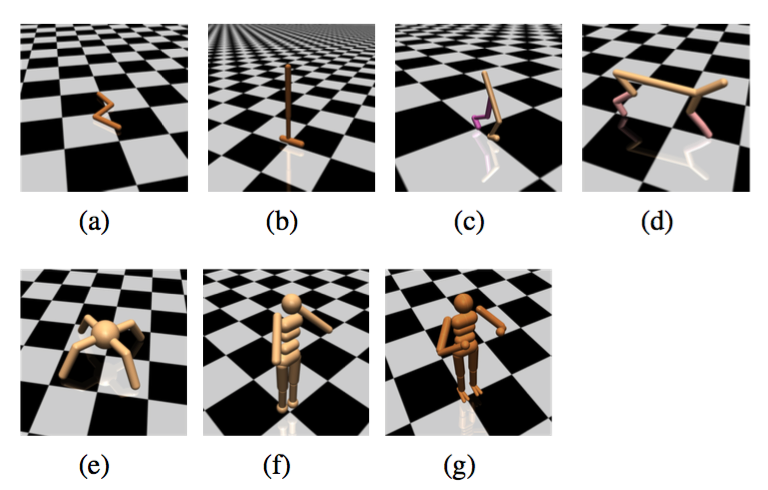
4)层次化任务:包含顶层决策+底层控制。比如下面的让虚拟蚂蚁找食物或者让虚拟蛇走迷宫。这种难度就很大了。

那么有了同样的测试环境,就可以对不同的算法进行对比。
对比出来的结果就是:
- TNPG和TRPO这两个方法(UC Berkerley的Schulman提出,现在属于OpenAI)最好,DDPG(DeepMind的David Silver团队提出的)次之。
- 层次任务目前没有一个算法能够完成,催生新的algorithm。
然后文章并没有对DeepMind的A3C算法http://arxiv.org/pdf/1602.01783进行测试,而这个是目前按DeepMind的文章最好的算法.
3 小结
UC Berkerley这次的开源相信对于学术界来说具有重要影响,很多研究者将受益于他们对于复现算法的公开。之后的研究恐怕也会在此Benchmark上进行测试。
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control的更多相关文章
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- Deep Reinforcement Learning
Reinforcement-Learning-Introduction-Adaptive-Computation http://incompleteideas.net/book/bookdraft20 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
随机推荐
- Android manifest 获取源代码
/********************************************************************************* * Android manifes ...
- Android Studio - 安卓开发工具 打开后报错集合、修复指南
安卓开发工具错误修复 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- 心分享.心创新 ...
- Struts2访问ServletAPI的三种方式
web应用中需要访问的ServletAPI,通常只有HttpServletRequest,HttpSession,ServletContext三个,这三个接口分别代表jsp内置对象中的request, ...
- BZOJ3551: [ONTAK2010]Peaks加强版【Kruskal重构树】【主席树】
重要的事情说三遍 不保证图联通 不保证图联通 不保证图联通 那些和我一样认为重构树是点数的童鞋是要GG Description [题目描述]同3545 Input 第一行三个数N,M,Q. 第二行N个 ...
- 【java规则引擎】《Drools7.0.0.Final规则引擎教程》第4章 4.2 lock-on-active
转载至:https://blog.csdn.net/wo541075754/article/details/75208955 lock-on-active 当在规则上使用ruleflow-group属 ...
- 获取js 文件传递的参数并使用json2进行json数据转换
主要的技术就不用详细进行介绍了,就是使用js文件进行参数的传递,用途有一下几个: 1,进行js的版本控制. 2,获取参数并,进行一些额外功能的添加(比如使用js 进行用户验证,设计开发API (一些开 ...
- Cocos2d-x 2.2.3 使用NDK配置编译环境
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/wwj_748/article/details/30072379 Cocos2d-x 2.2.3 使用 ...
- 【转】每天一个linux命令(26):用SecureCRT来上传和下载文件
原文网址:http://www.cnblogs.com/peida/archive/2012/11/28/2793181.html 用SSH管理linux服务器时经常需要远程与本地之间交互文件.而直接 ...
- vue-cli 打包报错:Unexpected token: punc (()
vue-cli 打包报错: ERROR in static/js/vendor.ed7d2353f79d28a69f3d.js from UglifyJs Unexpected token: punc ...
- shell获取目录下所有文件夹的名称并输出
获取指定目录/usr/下所有文件夹的名称并输出: shell代码: #!/bin/bash #方法一 dir=$(ls -l /usr/ |awk '/^d/ {print $NF}') for i ...