DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control
1 前言
Deep Reinforcement Learning可以说是当前深度学习领域最前沿的研究方向,研究的目标即让机器人具备决策及运动控制能力。话说人类创造的机器灵活性还远远低于某些低等生物,比如蜜蜂。。DRL就是要干这个事,而是关键是使用神经网络来进行决策控制。
因此,考虑了一下,决定推出DRL前沿系列,第一时间推送了解到的DRL前沿,主要是介绍最新的研究成果,不讲解具体方法(考虑到博主本人也没办法那么快搞懂)。也因此,本文对于完全不了解这个领域,或者对这个领域感兴趣的童鞋都适合阅读。
下面进入正题。
2 Benchmarking Deep Reinforcement Learning for Continuous Control
文章出处:http://arxiv.org/abs/1604.06778
时间:2016年4月25日
开源软件地址:https://github.com/rllab/rllab
这篇文章不是什么创新算法的文章,但却是极其重要的一篇文章,看到文章的第一眼就能看出来。这篇文章针对DRL在连续控制领域的问题弄了一个Benchmark,而且,关键是作者把程序开源了,按照作者的原话就是
To encourage adoption by other researchers!
在这篇文章中,或者说这个开源软件包中,作者将主流及前沿的几个用于连续控制领域的算法都用python复现了,然后将算法应用在31种不同难度的连续控制问题上。
那么一共分了四类任务:
1)简单任务:让倒立摆保持平衡之类
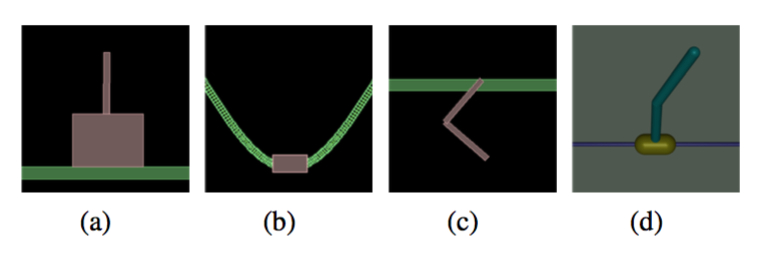
2)运动任务:让里面的虚拟生物往前跑,越快越好!
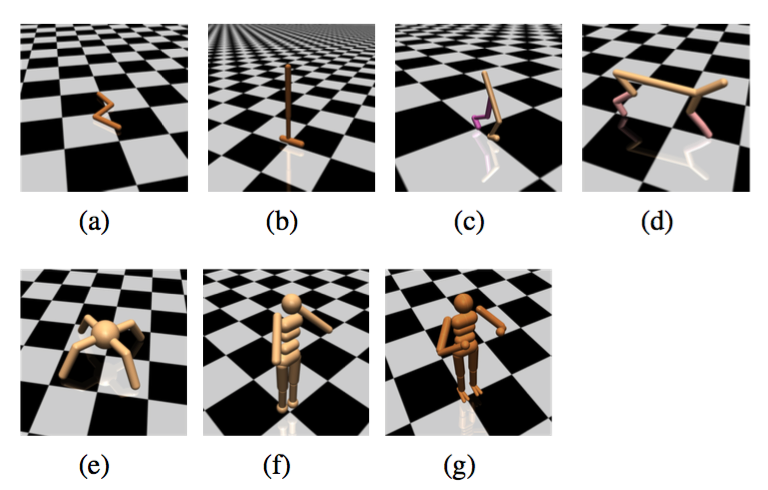
3)不完全可观察任务:即虚拟生物只能得到有限的感知信息,比如只知道每个关节的位置但不知道速度
4)层次化任务:包含顶层决策+底层控制。比如下面的让虚拟蚂蚁找食物或者让虚拟蛇走迷宫。这种难度就很大了。

那么有了同样的测试环境,就可以对不同的算法进行对比。
对比出来的结果就是:
- TNPG和TRPO这两个方法(UC Berkerley的Schulman提出,现在属于OpenAI)最好,DDPG(DeepMind的David Silver团队提出的)次之。
- 层次任务目前没有一个算法能够完成,催生新的algorithm。
然后文章并没有对DeepMind的A3C算法http://arxiv.org/pdf/1602.01783进行测试,而这个是目前按DeepMind的文章最好的算法.
3 小结
UC Berkerley这次的开源相信对于学术界来说具有重要影响,很多研究者将受益于他们对于复现算法的公开。之后的研究恐怕也会在此Benchmark上进行测试。
DRL前沿之:Benchmarking Deep Reinforcement Learning for Continuous Control的更多相关文章
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- Deep Reinforcement Learning
Reinforcement-Learning-Introduction-Adaptive-Computation http://incompleteideas.net/book/bookdraft20 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
随机推荐
- ROS功能包- rrt_exploration
一种基于RRT实现的多机器人地图探测算法的ROS软件包. 它还具有使用图像处理提取边界点.基于图像的边界检测等功能. 适用版本:indigo.jade.kinetic.lunar. 注意事项:官网文档 ...
- 推荐两个Magento做的中文网站 GAP和佰草集
Magento这两年发展很快,可以算是现阶段最有前途的开源电子商务系统,国外用的人很多,相对应的,国内也已经有很多人在用Magento建站了,可惜的是这其中绝大多数还是英文站,大多是国内外贸商建的外贸 ...
- magento -- 给Magento提速之缓存上的探索
依然在为Magento提速做努力,除了自带的缓存和编译,之前的所作的很多努力都是从减少JS,Css,图片等载入时间入手,而对页面载入耗时最早有时也是最大的一部分--获取页面数据没有做太多处理,以gap ...
- Jenkins自动化部署代码
通过jenkins自动化部署项目代码可以大幅度节省打包上传部署的时间,提高开发测试的工作效率 ========== 完美的分割线 =========== 1.Jenkins是什么 1)Jenkins是 ...
- 【opencv基础】detectmultiscale函数详解
前言 简单的人脸检测程序可以直接基于opencv的函数库进行实现,本文介绍一下detectMultiScale函数. 函数简介 opencv2人脸检测使用的是detectMultiScale函数,可以 ...
- Vec3b类型数据确定颜色通道
前言 这几天实习生测试一张图像的三个通道分别是什么颜色,使用的是Vec3b类型,然后发现了一个有意思的点.. 测试过程 先创建了一定大小的数据, Mat test( , , CV_8UC3, Scal ...
- nmap扫描时的2个小经验
http://pnig0s1992.blog.51cto.com/393390/367558/ 1.我肉鸡的环境是Windows XP sp3,在使用nmap扫描外网的时候,提示我 pcap_open ...
- (8)os和sys模块
import sysprint(sys.argv) #默认获取当前文件的路径 import os os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir(& ...
- IE7下对某些seajs压缩文件不兼容的解决方法
seajs.config({ comboExcludes: /common.js/ }) (杨磊哥提供)
- spring cloud 知识点
优秀的介绍资料: 资料 地址 spring cloud 中文网 https://springcloud.cc/ spring cloud 介绍 https://www.jianshu.com/p/74 ...