01_Flume基本架构及原理
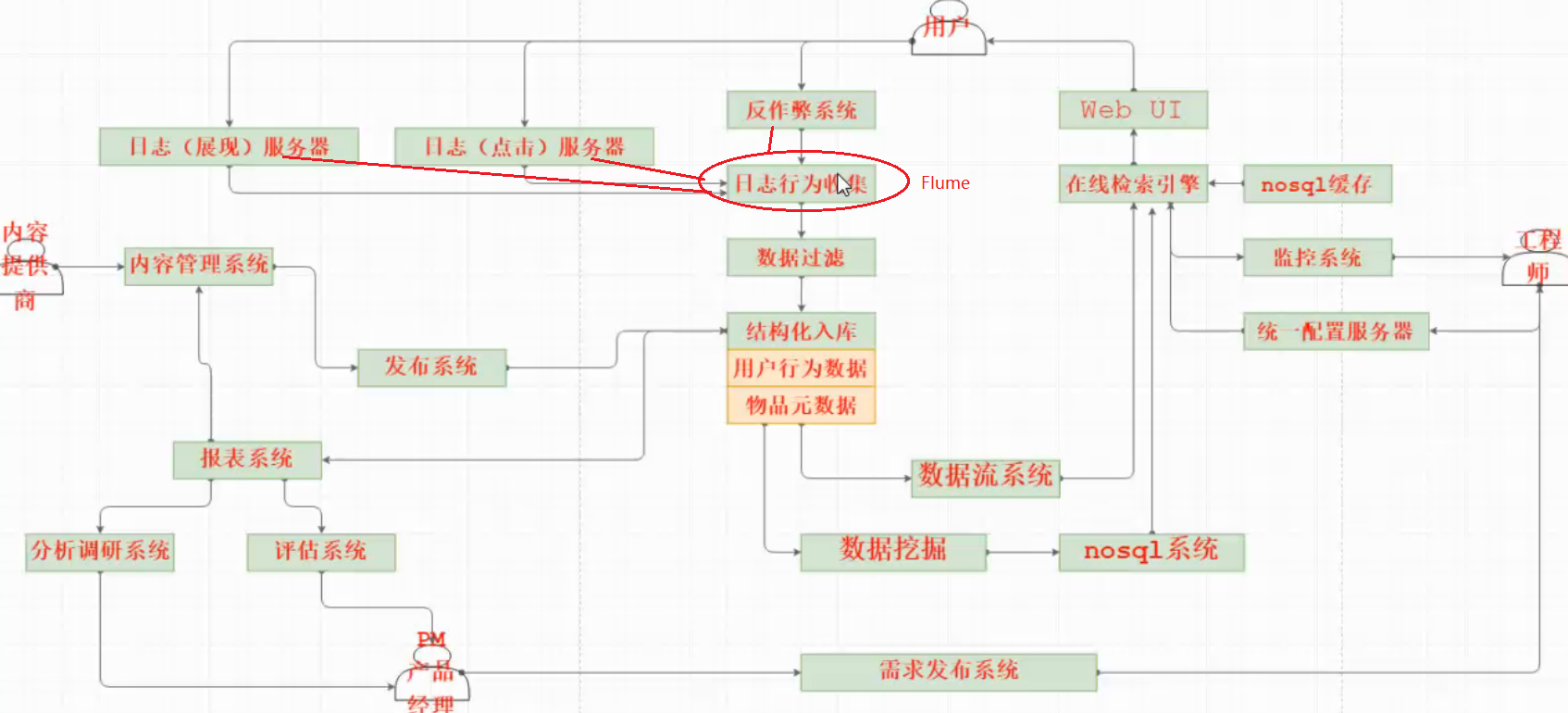
Flume消息收集系统,在整个系统架构中的位置
Flume概况
1) Apache软件基金会的顶级项目
2)存在两个大的版本:Flume 0.9.x(Flume-OG,original generation), Flume 1.x(Flume-NG,next generation)
3) 信息采集系统(分布式,支持水平扩展,事务机制保证消息event可靠传输,可定制的信息输入和信息输出,基于Java运行)
事务机制:下游agent将信息成功缓存后,上游agent才认为该信息传输成功
4)主要目的:deliver data from application to Apache Hadoop's ecosystem(HDFS,HBASE,HIVE,LocalFileSystem)
多管道接入(fan in),多管道输出(fan out),上下文路由(将event根据需求发送给不同的接收方)
5)运行环境:基于java编写,运行在unix-like系统(Ubuntu,CentOS, RHEL,SLES,Mac OS X)
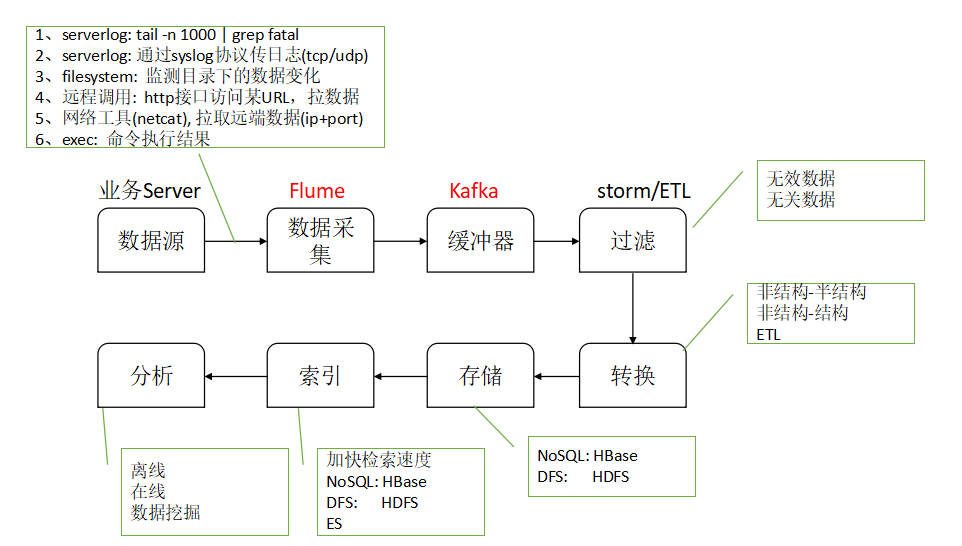
数据从产生到进入分析阶段的整个流程
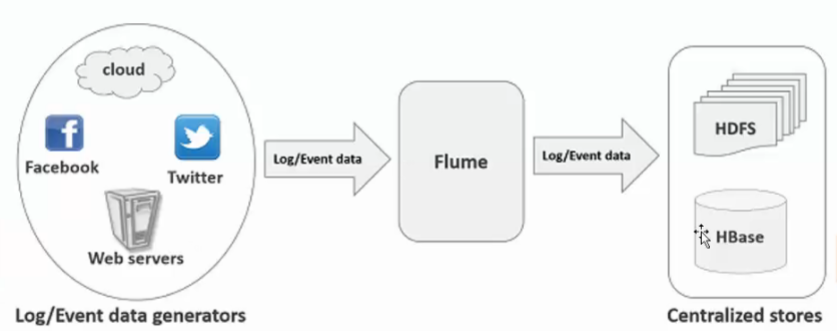
Flume的输入数据和输出数据

Flume架构
打开Flume来看

一般来说,Agent和Collector分离部署:
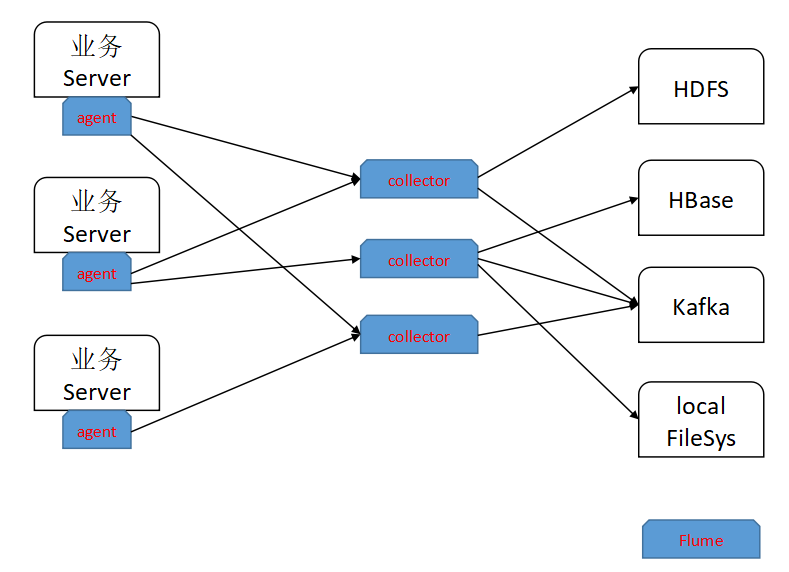
1)业务Server,只部署Agent, 尽量少的入侵业务系统
2)Collector可能会有多个,负责event汇聚的分发
3)Agent layer, Collector Layer, Storage Layer
打开Agent或者collector来看
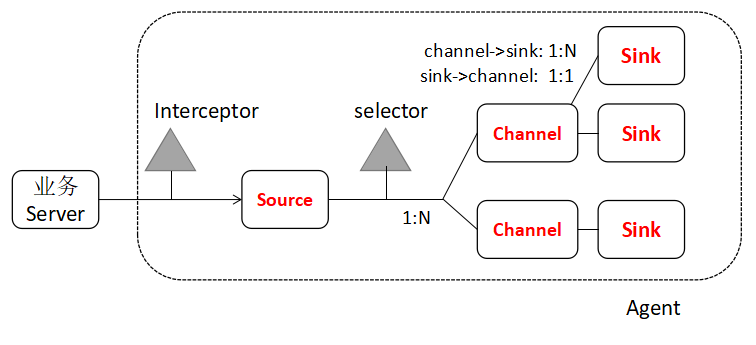
Agent或者Collector由3个必要组件,2个可选组件构成,Event是组件间的数据传递单位
1个Agent或者Collector,就是1个JVM进程
必要组件
1)Source:对接各种输入数据源(数据源直接发送event,或者Source将数据转换为event,Event由可选的Header和Byte净荷构成)

2) Channel:缓存event,直到event被Sink成功发送
最常用的是 memory(内存队列)和 file(本地文件),其他类型的channel还包括jdbc channel,kafka channel等
memory channel最大的问题是可能存在event丢失的风险,file可以持久化存储event但肯定就没有内存队列快
3) Sink: 将event送给下游Agent,或者将event送给下游存储
Agent间的级联,上游Sink必须为avro sink, 下游Source必须为avro source
可选组件
interceptor:干预器,主要用于向Event Header中注入一些附加信息(时间戳,主机信息,自定义信息,由于上下文路由)或者信息过滤(匹配正则的Event放行,匹配正则的Event丢弃)
1) timestamp interceptor: 在event的header中添加时间戳(处理该event的即时时间)
2) host interceptor: 在event的header中添加当前agent运行的主机的hostname或者IP地址
3) static interceptor: 在event的header中添加配置文件中指定的key,value
4) Regex Filtering: 将event的body中的内容和指定的正则表达式匹配,将匹配的event丢弃
5) Regex Extractor: 将event的body中的内容和指定的正则表达式匹配,将匹配的event放行,并添加header(指定的key, value为匹配的内容)
总结:interceptor可以级联,配置文件中通过空格分隔,前一个interceptor处理后的event,是后一个interceptor的输入event
selector: 选择器,主要用于选择Event将发往哪一个Channel(路由)
selector将event发送给channel有两种方式:复制Replicating(全部都发,默认方式), 复用Multiplexing(根据一定规则分发);
复用分发原理:selector根据event header中指定key的值来决定该event应该发给哪一个channel
Flume可靠性信息传递的原理(上下游协同,事务处理)
简单来说:下游agent将event成功缓存到channel后,上游agent才认为该event传输成功, 然后上游将该event从channel中删除
Flume的级联
1)多Agent级联

2) 多个Agent聚合级联
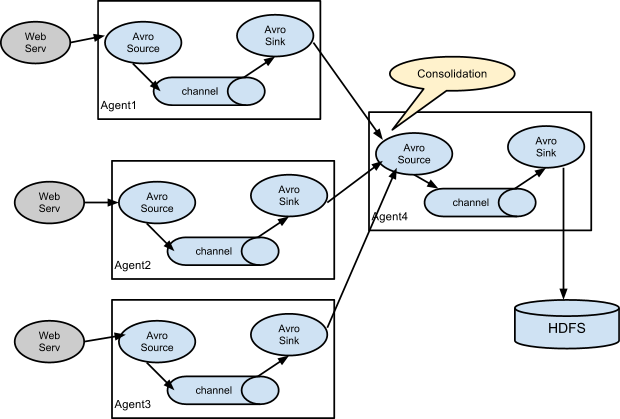
3) 复用分流

01_Flume基本架构及原理的更多相关文章
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- 爱莲(iLinkIT)的架构与原理
随着移动互联网时代的到来,手机正在逐步替代其他的设备,手机是电话.手机是即时通讯,手机是相机,手机是导航仪,手机是钱包,手机是音乐播放器……. 除此之外,手机还是一个大大的U盘,曾几何时,我们用一根长 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- Oracle rac架构和原理
Oracle RAC Oracle Real Application Cluster (RAC,实时应用集群)用来在集群环境下实现多机共享数据库,以保证应用的高可用性:同时可以自动实现并行处理 ...
- storm架构及原理
storm 架构与原理 1 storm简介 1.1 storm是什么 如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统.按照作者 Nathan Marz 的说 ...
随机推荐
- WordPress 3.8 后台仪表盘将重新设计
WordPress 3.8 的后台仪表盘界面将会重新设计 概况(RightNow) -> 改为网站内容(SiteContent) 快速发布(QuickPress) -> 改为快速草稿(Qu ...
- PAT 1054 The Dominant Color[简单][运行超时的问题]
1054 The Dominant Color (20)(20 分) Behind the scenes in the computer's memory, color is always talke ...
- C#:文件、byte[]、Stream相互转换
一.byte[] 和 Stream /// <summary> /// byte[]转换成Stream /// </summary> /// <param name=&q ...
- Intro to Python for Data Science Learning 3 - functions
Functions from:https://campus.datacamp.com/courses/intro-to-python-for-data-science/chapter-3-functi ...
- Scrapy是什么
1.Scrapy是蜘蛛爬虫框架,我们用蜘蛛来获取互联网上的各种信息,然后再对这些信息进行数据分析处理. 2.Scrapy的组成 引擎:处理整个系统的数据流处理,出发事务 调度器: 接受引擎发过来的请求 ...
- 20165207 2017-2018-2《Java程序设计》课程总结
20165207 2017-2018-2<Java程序设计>课程总结 每周作业链接汇总 预备作业1:我期望的师生关系 预备作业2:学习基础与C语言调查反馈 预备作业3:Linux安装与命令 ...
- 安装rocketmq-console
一.alibaba版本 使用rocketmq命令查看集群状态,查看topic信息时比较麻烦,而且不直观,这个时候可以使用一些web页面来管理rocketmq. 以前曾使用过一个老版本的工具,适用于al ...
- Struts2 Spring Hibernate 框架整合 Annotation MavenProject
项目结构目录 pom.xml 添加和管理jar包 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns ...
- 高并发下,php使用uniqid函数生成唯一标识符的四种方案
PHP uniqid()函数可用于生成不重复的唯一标识符,该函数基于微秒级当前时间戳.在高并发或者间隔时长极短(如循环代码)的情况下,会出现大量重复数据.即使使用了第二个参数,也会重复,最好的方案是结 ...
- redhat6.4 elasticsearch1.7.3安装配置
利用elasticsearch管理集群索引, 今天刚好需要重新调整elasticsearch的最大内存, 所以自己安装了练手 附件: elasticsearch 附件:elasticsearch-he ...