Scrapy是什么
1.Scrapy是蜘蛛爬虫框架,我们用蜘蛛来获取互联网上的各种信息,然后再对这些信息进行数据分析处理。
2.Scrapy的组成
- 引擎:处理整个系统的数据流处理,出发事务
- 调度器: 接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回
- 下载器: 下载网页内容,并将网页内容返回给蜘蛛
- 蜘蛛: 蜘蛛是主要干活的,用来制定特定域名或网页的解析规则
- 项目管道: 清洗验证存储数据,页面被蜘蛛解析后,被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件: 位于引擎和下载器之间,处理引擎与下载器之间的请求及响应
- 蜘蛛中间件:位于引擎和蜘蛛之间,处理从引擎发送到调度的请求及响应
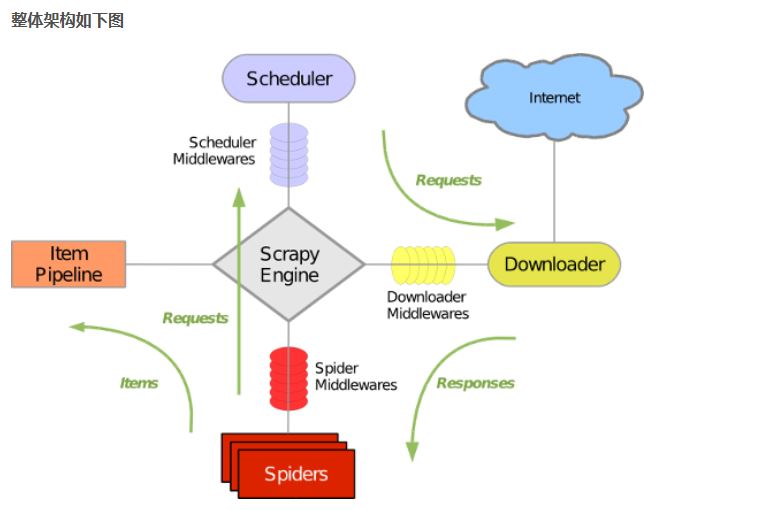
3.工作机制
- 爬取流程
首先从URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回给Scheduler;另一种是需要保存的数据,他们被送到Item Pipeline那里,那是对数据进行后期处理(详细分析,过滤,存储)的地方。另外在数据流动的管道里还可以安装各种中间件,进行必要的处理。
- 数据流程
- 引擎打开一个网站,找到处理该网站的Spider,并向Spider请求第一个要爬取的URL。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器中以request进行调度。
- 引擎向调度器请求下一个要爬取的URL
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件转发给下载器
- 下载完毕后,下载器生成一个该页面的response,并将其通过中间件返回给引擎
- 引擎从下载器中接收到response并通过Spider中间件发送给Spider处理
- Spider处理response并返回爬取到的Item及新的Request给引擎。
- 引擎将爬取到的Item给Item Pipeline,将Request给调度器
- 从第二步重复,直到调度器中没有更多的request,引擎关闭该网站。
Scrapy是什么的更多相关文章
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- scrapy爬虫docker部署
spider_docker 接我上篇博客,为爬虫引用创建container,包括的模块:scrapy, mongo, celery, rabbitmq,连接https://github.com/Liu ...
- scrapy 知乎用户信息爬虫
zhihu_spider 此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧.代码地 ...
- ubuntu 下安装scrapy
1.把Scrapy签名的GPG密钥添加到APT的钥匙环中: sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 6272 ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- scrapy cookies:将cookies保存到文件以及从文件加载cookies
我在使用scrapy模拟登录新浪微博时,想将登录成功后的cookies保存到本地,下次加载它实现直接登录,省去中间一系列的请求和POST等.关于如何从本次请求中获取并在下次请求中附带上cookies的 ...
- Scrapy开发指南
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. Scrapy基于事件驱动网络框架 Twis ...
- 利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询. 安装 在进行今天的任务之前我们需要安装二个框架,分别 ...
- python3 安装scrapy
twisted(网络异步框架) wget https://pypi.python.org/packages/dc/c0/a0114a6d7fa211c0904b0de931e8cafb5210ad82 ...
随机推荐
- 【CF913F】Strongly Connected Tournament 概率神题
[CF913F]Strongly Connected Tournament 题意:有n个人进行如下锦标赛: 1.所有人都和所有其他的人进行一场比赛,其中标号为i的人打赢标号为j的人(i<j)的概 ...
- iOS uitextfield长度限制
[textUsername addTarget:self action:@selector(textFieldDidChange:) forControlEvents:UIControlEventEd ...
- R的transform
函数transform 作用:为原数据框添加新的列,改变原变量列的值,通过赋值NULL删除列变量 用法: transform(‘data’,….) data就是要修改的data, '…..'代表你要 ...
- 关于51单片机使用printf串口调试
在51系列单片机上面使用串口的时候,有时候为了方便调试看一下输出结果,会用到printf函数输出到电脑终端,再用串口助手显示.但是单片机使用printf的时候有一点需要注意的地方. 1.首先添加头文件 ...
- 慕课网,vue高仿饿了吗ASP源码视频笔记
1.源码笔记 我的源码+笔记(很重要):http://pan.baidu.com/s/1geI4i2Z 感谢麦子学院项目相关视频 2.参考资料 Vue.js官网(https://vuejs.org.c ...
- POJ-1414 Life Line (暴力搜索)
Life Line Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 855 Accepted: 623 Description L ...
- MapReduce的洗牌(Shuffle)
Shuffle过程:数据从map端传输到reduce端的过程~ Map端 每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io. ...
- codeforces 586B/C
题目链接:http://codeforces.com/contest/586/problem/B B. Laurenty and Shop time limit per test 1 second m ...
- 6.2.3 Property Access Errors
JavaScript: The Definitive Guide, Sixth Edition by David Flanagan Property access expressions do n ...
- vim编辑器的基本用法
使用linux时候,个人比较喜欢用vim编辑器,对文本进行操作. 为了方便我使用vim编辑器,特地搜索了一下教程记录于此,防止自己忘记了. 下面就是一些vim使用的基础操作: 使用vim打开软件 vi ...