lucene 建立索引的过程
时间 -- :: CSDN博客 原文 http://blog.csdn.net/caohaicheng/article/details/
看lucene主页(http://lucene.apache.org/)上目前lucene已经到4.9.0版本了, 参考学习的书是按照2.1版本讲解的,写的代码例子是用的3.0.2版本的,版本
的不同导致有些方 法的 使用差异,但是大体还是相同的。
参考资料:
1、公司内部培训资料
2、《Lucene搜索引擎开发权威经典》于天恩著.
Lucene使用挺简单的,耐心看完都能学会,还有源代码。
一、创建索引的基本方式
所有开源搜索引擎的基本架构和原理都是类似的,Lucene也不例外,用它来建立搜索引擎也是要解决的四个基本问题:抓取数据、解析数据、创建索引和执行搜索。
1、理解创建索引的过程
参考书中对索引的创建有一个很形象的比喻:
创建索引的过程可以类比为写文集。下面以文集的写作为例进行讲解,文集里面有许多文章,每一篇文章包括标题、内容、作品名称、写作时间等信息。
我们采用以下的方式来写这本文集:先写文章,再将文章整合起来。
首先为每一篇文章添加标题、内容、写作时间等信息,从而写好一篇文章。
然后把每一篇文章添加到书里面去,这样文集就写好了。
文集的结构如下图所示:按从左到右的方向,是读文集,即打开一本书,然后翻阅里面的文章;按从右到左的方向是写文集。

创建索引的过程如下:
(1)、建立索引器IndexWriter,这相当于一本书的框架
(2)、建立文档对象Document,这相当于一篇文章
(3)、建立信息字段对象Field,这相当于一篇文章中的不同信息(标题、正文等)。
(4)、将Field添加到Document里面。
(5)、将Document添加到IndexWriter里面。
(6)、关闭索引器IndexWriter。
如下图所示是一个索引的结构,按从左到右是读索引(即搜索)。按从右到左是创建索引:
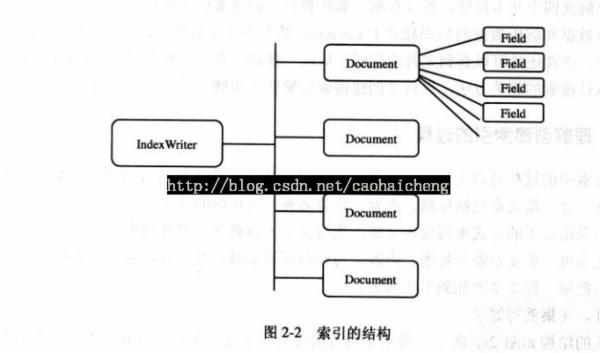
按照上图所示的结构,创建索引有三个基本的步骤:
(1)、创建Field,将文章的不同信息包装起来
(2)、将多个Field组织到一个Document里面,这样完成了对一篇文章的包装。
(3)、将多个Document组织到一个IndexWriter里面,也就是将多个文章组装起来,最终形成索引
下面的三个小节就按照创建索引的基本步骤来讲解创建索引的具体方法。
2、创建Field
创建Field的方法有许多,下面是最常用的方法。
Field field=new Field(Field名称,Field内容,存储方式,索引方式);
这四个参数的含义如下:
(1)、Field名称就是为Field起的名字,类似于数据表的字段名称。
(2)、Field内容就是该Field的内容,类似数据库表的字段内容。
(3)、存储方式包括三种:不存储(Field.Store.NO)、完全存储(Field.Store.YES)和压缩存储(Field.Store.COMPRESS)。
通常,如果不担心索引太大的话,可以都使用完全存储的方式。但是,出于对性能的考虑,索引文件的内容是越小越好。因此,如果Field的内容很少就采用完全存储(如标
题),如果Field的内容很多就采用不存储或压缩存储的方式,如正文。
(4)、索引的方式包括四种:
不索引(Field.Index.NO)、索引但不分析(Field.Index.NO_NORMS)、索引但不分词(Field.Index.UN_TOKENIZED)、分词并索引(Field.Index.TOKENIZED)。
3、创建Document
创建Document方法如下:
Document doc=new Document();
这个方法用来创建一个不含有任何Field的空Document。
如果想把Field添加到Document里面,只需要add方法。例如doc.add(field);
重复的使用就可以将多个Field加入到一个Document里面。
4、创建IndexWriter
创建IndexWriter方式也不少,拿出一个常用的:
<span style="font-family:SimSun;font-size:12px;"><span style="font-family:SimSun;font-size:12px;"> File indexDir = new File("E:\\Index");
Directory dir = new SimpleFSDirectory(indexDir);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
IndexWriter indexWriter = new IndexWriter(dir, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);</span></span>
关于几个参数的介绍:
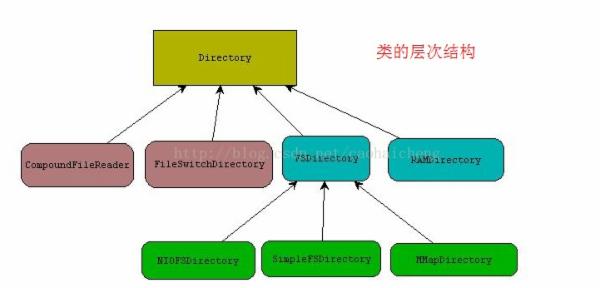
(1)、Directory (目录类型) 该类是抽象类
它的直接子类在不同版本中还是有区别的,我们直说3.0.2版本,它的子类包括 、 、 FileSwitchDirectory、 CompoundFileReader ,两个子类代表着不同的两种目录类型
FSDirectory:文件系统中的一个路径,会直接将索引写入到磁盘上
RAMDirectory:内存中的一个区域,虚拟机退出后内容会随之消失,所以需要将RAMDirectory中的内容转到FSDirectory。
FileSwitchDirectory: 一个是用于可以同时在两个不同的目录中读取文件的FileSwitchDirectory,这是个代理类。
CompoundFileReader: 是用户读取复合文件的CompoundFileReader,只能读取扩展名为cfs的文件。(写扩展名为cfs的文件用CompoundFileWriter)CompoundFileReader仅在SegmentReader中被引用。
其中FSDirectory又分为3类:
A、 windows下的SimpleFSDirectory
B、linux支持NIO的NIOFSDirectory
C、还有一个是内存Map目录MMapDirectory
(2)、Analyzer(分析器) 抽象类
负责对各种输入的数据源进行分析,包括过滤和分词等多种功能。
分析器是用来做词法分析的,包括英文分析器和中文分析器等。要根据所要建立的索引的文件情况选择合适的分析器。常用的有StandardAnalyzer(标准分析器)、CJKAnalyzer(二分法分词
器)、ChineseAnalyzer(中文分析器)等。
可以根据自己的需要去编辑分析器,从而处理不同 的语言文字(当然,我不会)。
IndexWriter创建完之后可以用addDocument()的方法将document对象放置到IndexWriter中:writer.addDocument(doc);
可以放置多个。
最终要调用close()方法关闭索引器,例如writer.close();
到此,创建索引的步骤就介绍完了,下面我们就该看实例了:
二、创建一个简单索引实例:
<span style="font-family:SimSun;font-size:12px;">import java.io.File; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version; public class LuceneMainProcess { public static void main(String[] args) {
createLuceneIndex();
} public static void createLuceneIndex() {
try {
File indexDir = new File("E:\\Index");
Directory dir = new SimpleFSDirectory(indexDir);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
//IndexWriter为某个Document建立索引时所取到的Field内的最大词条数目,该属性的初始值为10000
IndexWriter indexWriter = new IndexWriter(dir, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);
// 创建8个文档
Document doc1 = new Document();
Document doc2 = new Document();
Document doc3 = new Document();
Document doc4 = new Document();
Document doc5 = new Document();
Document doc6 = new Document();
Document doc7 = new Document();
Document doc8 = new Document(); Field f1 = new Field("bookname", "钢铁是怎样炼成的", Field.Store.YES,
Field.Index.ANALYZED);
Field f2 = new Field("bookname", "英雄儿女", Field.Store.YES,
Field.Index.ANALYZED);
Field f3 = new Field("bookname", "篱笆女人和狗", Field.Store.YES,
Field.Index.ANALYZED);
Field f4 = new Field("bookname", "女人是水做的", Field.Store.YES,
Field.Index.ANALYZED);
Field f5 = new Field("bookname", "我的兄弟和女儿", Field.Store.YES,
Field.Index.ANALYZED);
Field f6 = new Field("bookname", "白毛女", Field.Store.YES,
Field.Index.ANALYZED);
Field f7 = new Field("bookname", "钢的世界", Field.Store.YES,
Field.Index.ANALYZED);
Field f8 = new Field("bookname", "钢铁战士", Field.Store.YES,
Field.Index.ANALYZED); doc1.add(f1);
doc2.add(f2);
doc3.add(f3);
doc4.add(f4);
doc5.add(f5);
doc6.add(f6);
doc7.add(f7);
doc8.add(f8); indexWriter.addDocument(doc1);
indexWriter.addDocument(doc2);
indexWriter.addDocument(doc3);
indexWriter.addDocument(doc4);
indexWriter.addDocument(doc5);
indexWriter.addDocument(doc6);
indexWriter.addDocument(doc7);
indexWriter.addDocument(doc8); indexWriter.optimize();//对索引进行优化,保证检索时的速度,但是需要消耗内存和磁盘空间,耗时耗力,需要的时候再优化(而非任意时刻)
indexWriter.close();//关闭索引器,否则会导致索引的数据滞留在缓存中未写入磁盘,有可能连目录的锁也没有去除
} catch (Exception e) {
e.printStackTrace();
}
} }
</span>
执行之后我们发现E盘下出现了一个index目录,这就是我们创建的索引文件。
到此,索引文件也就是创建完毕了。
明天接着往下整理索引的读取,到时候我们就可以更直观的判断上面创建的索引是否成功。
lucene 建立索引的过程的更多相关文章
- lucene建立索引的过程
建立索引过程 用户提交数据=>solr建立索引=>调用lucene包建立索引 官方建立索引和查询索引的例子如下: http://lucene.apache.org/core/4_10_3/ ...
- Lucene建立索引搜索入门实例
第一部分:Lucene建立索引 Lucene建立索引主要有以下两步:第一步:建立索引器第二步:添加索引文件准备在f盘建立lucene文件夹,然后 ...
- 【转】Lucene不同版本中Field的Keyword、UnIndex,导致lucene 建立索引总是报错 急!!
lucene 建立索引 总是报错 急!! http://zhidao.baidu.com/link?url=iaVs9JH4DfN6iwaWImt7VMJENWCWGGaWFGPjqhUw_jz7Fs ...
- Lucene4.9学习笔记——Lucene建立索引
基本上创建索引需要三个步骤: 1.创建索引库IndexWriter对象 2.根据文件创建文档Document 3.向索引库中写入文档内容 这其中主要涉及到了IndexWriter(索引的核心组件,用于 ...
- elasticsearch(lucene)索引数据过程
倒排索引存储-分段存储(lucene的功能)在lucene中:lucene index包含了若干个segment在elasticsearch中:index包含了若干主从shard,shard包干了若干 ...
- lucene 建立索引的不同方式
1.创建一个简单的索引: package lia.meetlucene; import java.io.File; import org.apache.lucene.document.Document ...
- solr建立索引的过程
HttpSolrServer HttpSolrServer继承SolrServer 参考文档:http://my.oschina.net/qige/blog/173008
- html抽取文本信息-java版(适合lucene建立索引)
import org.htmlparser.NodeFilter; import org.htmlparser.Parser; import org.htmlparser.beans.StringBe ...
- 利用Lucene将被索引文件目录中的所有文件建立索引
1.新建两个文件夹htm和index,其中htm中存放被索引的文件,index文件中存放建立的索引文件. 2.新建解析目录中所有文件的类,用来解析指定目录下的所有文件. import java.io. ...
随机推荐
- 转MYSQL学习(五) 索引
索引是在存储引擎中实现的,因此每种存储引擎的索引都不一定完全相同,并且每种存储引擎也不一定支持所有索引类型. 根据存储引擎定义每个表的最大索引数和最大索引长度.所有存储引擎支持每个表至少16个索引,总 ...
- 字母排列_next_permutation_字典序函数_待解决
问题 B: 字母排列 时间限制: 1 Sec 内存限制: 64 MB提交: 19 解决: 5[提交][状态][讨论版] 题目描述 当给出一串字符时,我们逐个可以变换其字符,形成新的字符串.假如对这 ...
- codeforces B. Sereja and Stairs 解题报告
题目链接:http://codeforces.com/problemset/problem/381/B 题目意思:给定一个m个数的序列,需要从中组合出符合楼梯定义 a1 < a2 < .. ...
- Java 复制文件的高效方法
转载自:http://jingyan.baidu.com/article/ff4116259c2d7712e4823780.html 在Java编程中,复制文件的方法有很多,而且经常要用到.我以前一直 ...
- iOS开发——开发实战篇&版本控制SVN和Git使用详解
版本控制SVN和Git使用详解 公司的实际开发中,在天朝使用较多的还是SVN,因为SVN是集中式的,在天朝上班你们都懂的! -----------------svn--------- ...
- [Android Pro] 监听内容提供者ContentProvider的数据变化
转载自:http://blog.csdn.net/woshixuye/article/details/8281385 一.提出需求 有A,B,C三个应用,B中的数据需要被共享,所以B中定义了内容提供者 ...
- jQuery操作DOM和CSS函数
function des html jquery result html() 获取元素中HTML内容 <div id="box" style="color:red& ...
- unix PS命令和JPS命令的区别
1.JPS介绍 用来查看基于HotSpot的JVM里面中,所有具有访问权限的Java进程的具体状态, 包括进程ID,进程启动的路径及启动参数等等,与unix上的ps类似,只不过jps是用来显示java ...
- MySQL auto-extending data file
http://blog.csdn.net/hw_libo/article/details/39215723 http://blog.sina.com.cn/s/blog_5037eacb0102vjm ...
- 一个可能有用的封闭PGSQL操作的PYTHON函数
URL: http://www.linuxyw.com/517.html 一般操作: import psycopg2 连接数据库 conn = psycopg2.connect(database=db ...