python之网络爬虫
一、演绎自已的北爱
踏上北漂的航班,开始演奏了我自已的北京爱情故事
二、爬虫1
1、网络爬虫的思路
首先:指定一个url,然后打开这个url地址,读其中的内容。
其次:从读取的内容中过滤关键字;这一步是关键,可以通过查看源代码的方式获取。
最后:下载获取的html的url地址,或者图片的url地址保存到本地
2、针对指定的url来网络爬虫
分析:
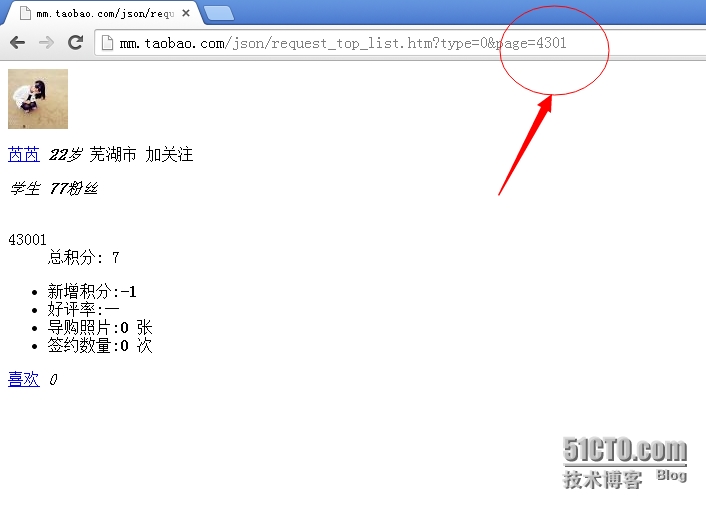
第一步:大约共有4300个下一页。
第二步:一个页面上有10个个人头像
第三步:一个头像内大约有100张左右的个人图片
指定的淘宝mm的url为:http://mm.taobao.com/json/request_top_list.htm?type=0&page=1
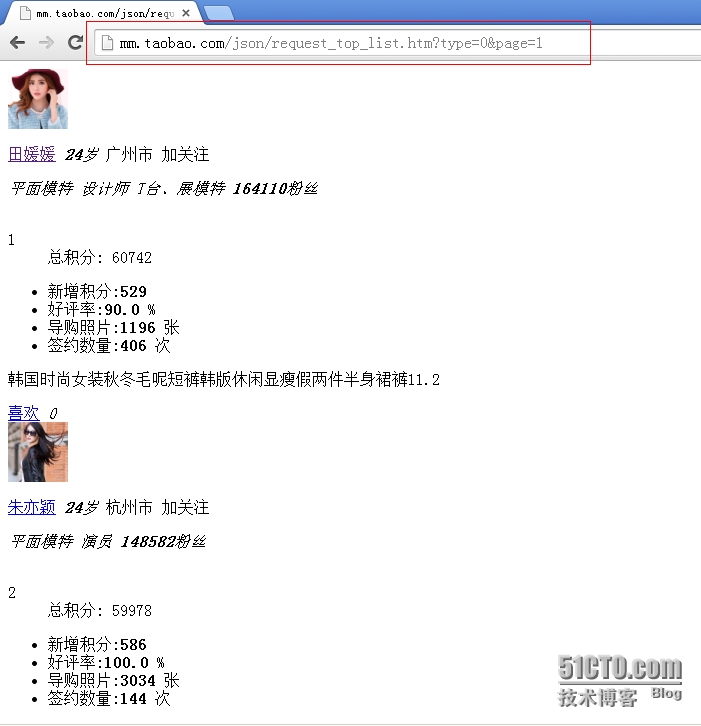
这个页面默认是没有下一页按钮的,我们可以通过修改其url地址来进行查看下一个页面
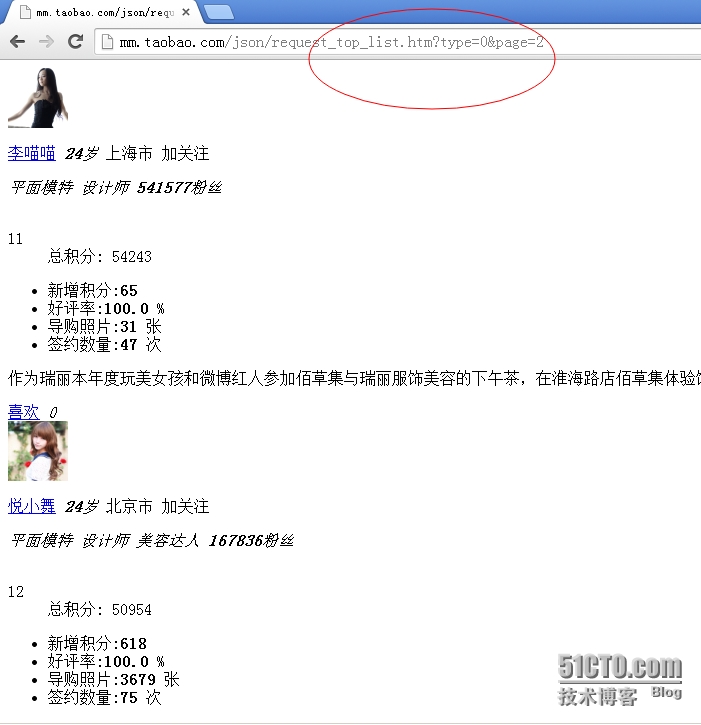
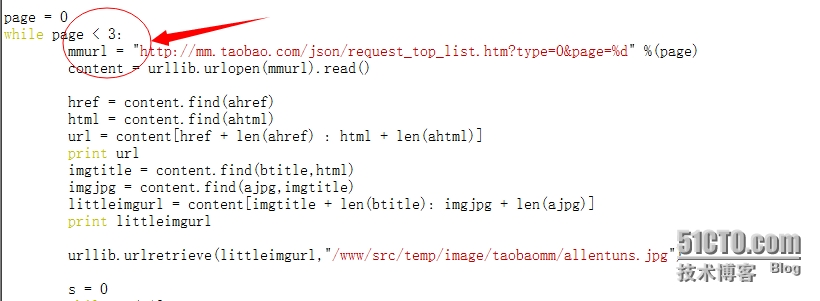
最后一页的url地址和页面展示如下图所示:
点击任意一个头像来进入个人的主页,如下图

3、定制的脚本
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
#!/usr/bin/env python#coding:utf-8#Author:Allentuns#Email:zhengyansheng@hytyi.comimport urllibimport osimport sysimport timeahref = '<a href="'ahrefs = '<a href="h'ahtml = ".htm"atitle = "<img style"ajpg = ".jpg"btitle = '<img src="'page = 0while page < 4300: #这个地方可以修改;最大值为4300,我测试的时候写的是3. mmurl = "http://mm.taobao.com/json/request_top_list.htm?type=0&page=%d" %(page) content = urllib.urlopen(mmurl).read() href = content.find(ahref) html = content.find(ahtml) url = content[href + len(ahref) : html + len(ahtml)] print url imgtitle = content.find(btitle,html) imgjpg = content.find(ajpg,imgtitle) littleimgurl = content[imgtitle + len(btitle): imgjpg + len(ajpg)] print littleimgurl urllib.urlretrieve(littleimgurl,"/www/src/temp/image/taobaomm/allentuns.jpg") s = 0 while s < 18: href = content.find(ahrefs,html) html = content.find(ahtml,href) url = content[href + len(ahref): html + len(ajpg)] print s,url imgtitle = content.find(btitle,html) imgjpg = content.find(ajpg,imgtitle) littleimgurl = content[imgtitle : imgjpg + len(ajpg)] littlesrc = littleimgurl.find("src") tureimgurl = littleimgurl[littlesrc + 5:] print s,tureimgurl if url.find("photo") == -1: content01 = urllib.urlopen(url).read() imgtitle = content01.find(atitle) imgjpg = content01.find(ajpg,imgtitle) littleimgurl = content01[imgtitle : imgjpg + len(ajpg)] littlesrc = littleimgurl.find("src") tureimgurl = littleimgurl[littlesrc + 5:] print tureimgurl imgcount = content01.count(atitle) i = 20 try: while i < imgcount: content01 = urllib.urlopen(url).read() imgtitle = content01.find(atitle,imgjpg) imgjpg = content01.find(ajpg,imgtitle) littleimgurl = content01[imgtitle : imgjpg + len(ajpg)] littlesrc = littleimgurl.find("src") tureimgurl = littleimgurl[littlesrc + 5:] print i,tureimgurl time.sleep(1) if tureimgurl.count("<") == 0: imgname = tureimgurl[tureimgurl.index("T"):] urllib.urlretrieve(tureimgurl,"/www/src/temp/image/taobaomm/%s-%s" %(page,imgname)) else: pass i += 1 except IOError: print '/nWhy did you do an EOF on me?' break except: print '/nSome error/exception occurred.' s += 1 else: print "---------------{< 20;1 page hava 10 htm and pic }-------------------------}" page = page + 1 print "****************%s page*******************************" %(page)else: print "Download Finshed." |
4、图片展示(部分图片)
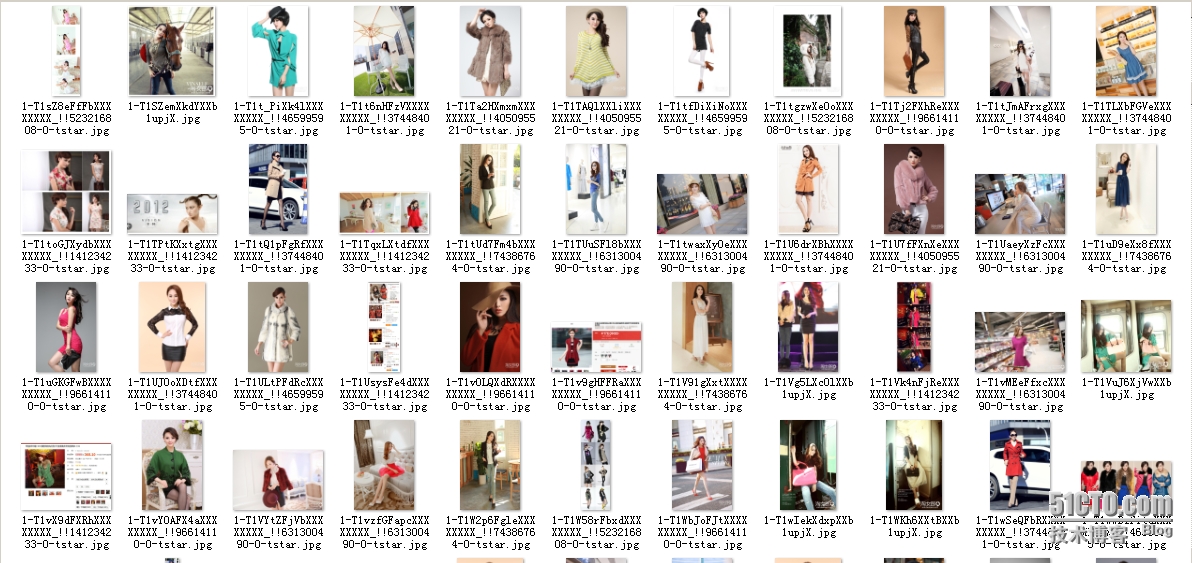
5、查看下载的图片数量
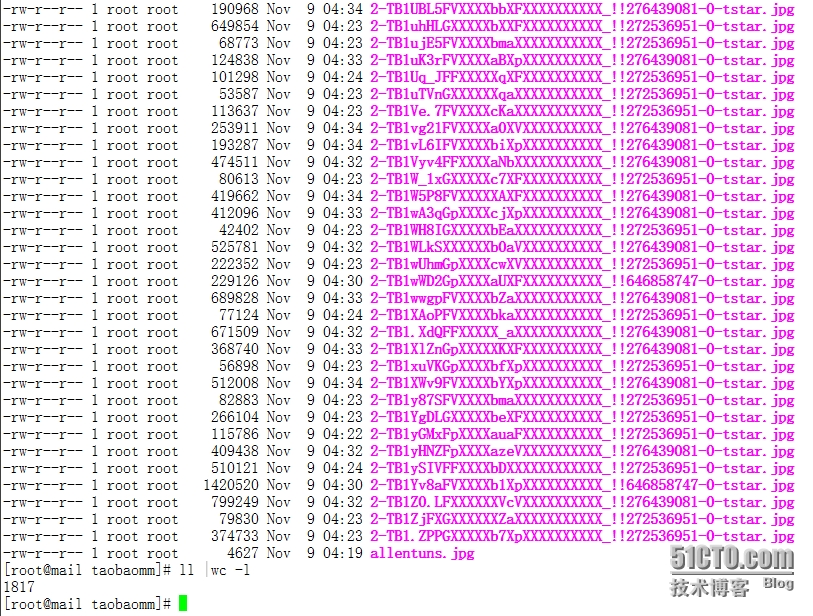
二、爬虫2
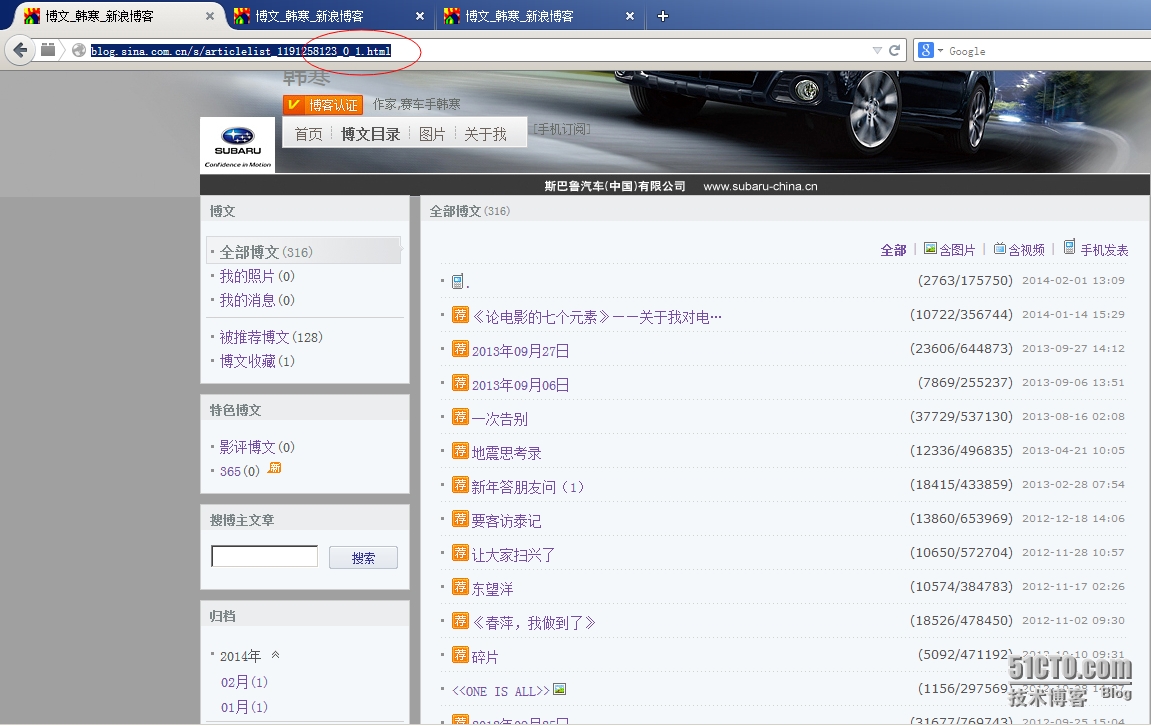
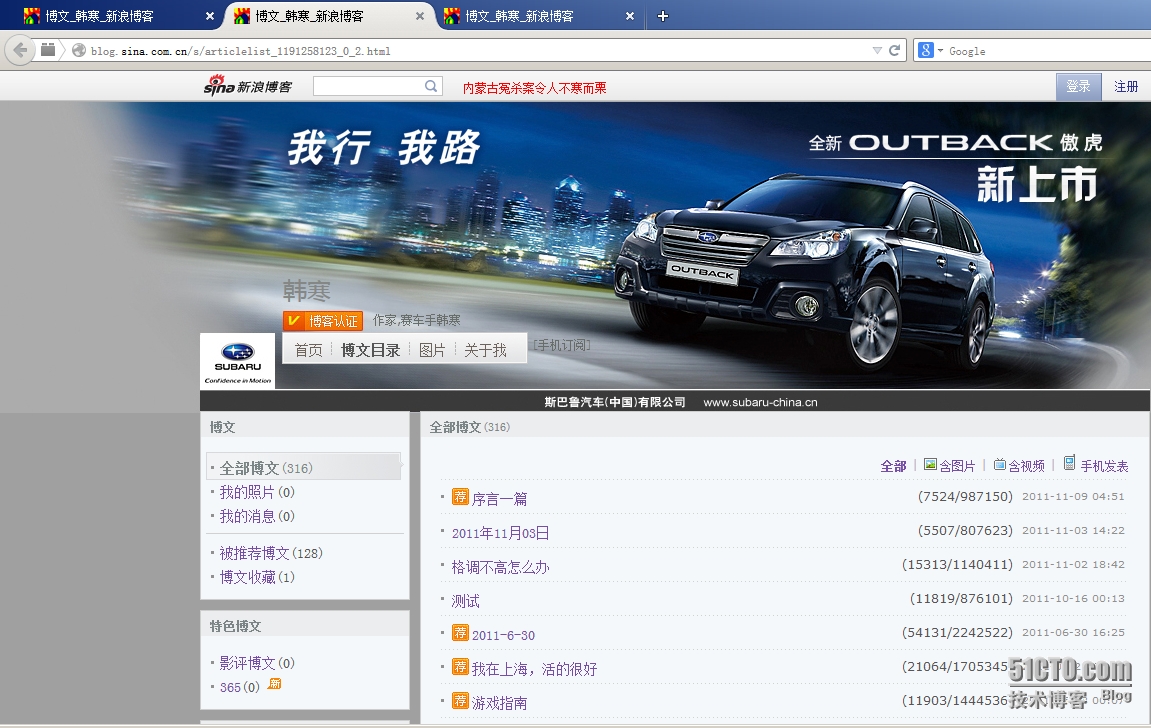
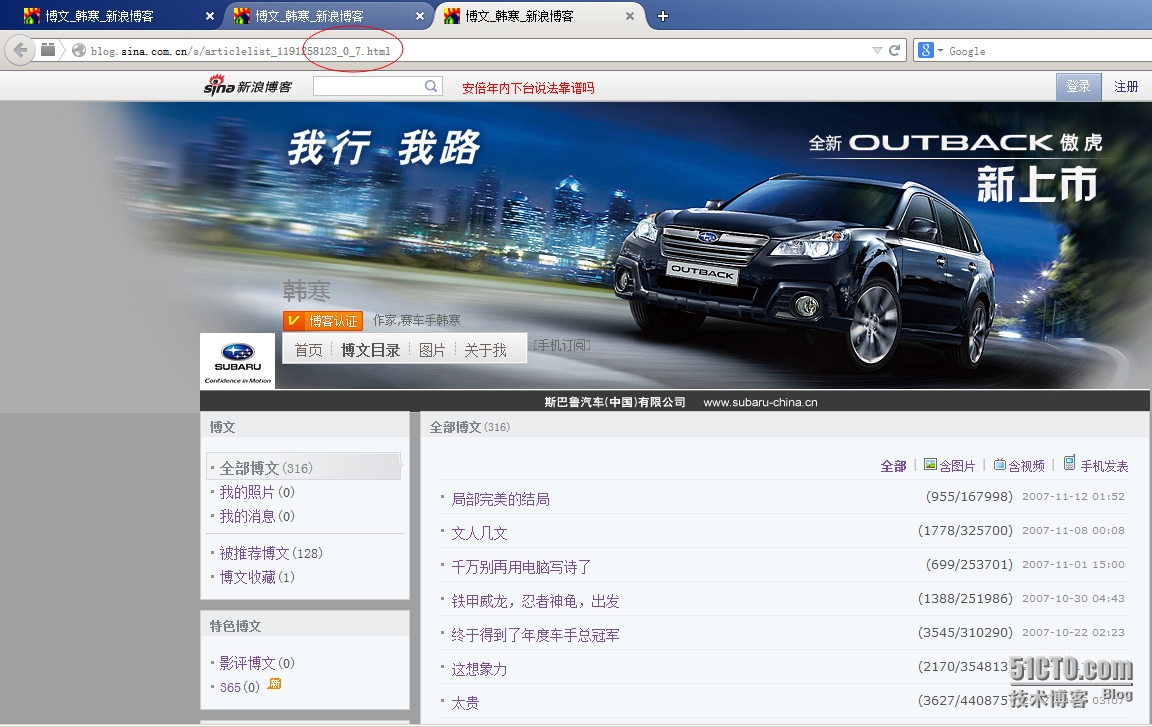
1、首先来分析url
第一步:总共有7个页面;
第二步:每个页面有20篇文章
第三步:查看后总共有317篇文章
2、python脚本
脚本的功能:通过给定的url来将这片博客里面的所有文章下载到本地
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
#!/usr/bin/env python#coding: utf-8import urllibimport timelist00 = []i = j = 0page = 1while page < 8: str = "http://blog.sina.com.cn/s/articlelist_1191258123_0_%d.html" %(page) content = urllib.urlopen(str).read() title = content.find(r"<a title") href = content.find(r"href=",title) html = content.find(r".html",href) url = content[href + 6:html + 5] urlfilename = url[-26:] list00.append(url) print i, url while title != -1 and href != -1 and html != -1 and i < 350: title = content.find(r"<a title",html) href = content.find(r"href=",title) html = content.find(r".html",href) url = content[href + 6:html + 5] urlfilename = url[-26:] list00.append(url) i = i + 1 print i, url else: print "Link address Finshed." print "This is %s page" %(page) page = page + 1else: print "spage=",list00[50] print list00[:51] print list00.count("") print "All links address Finshed."x = list00.count('')a = 0while a < x: y1 = list00.index('') list00.pop(y1) print a a = a + 1print list00.count('')listcount = len(list00)while j < listcount: content = urllib.urlopen(list00[j]).read() open(r"/tmp/hanhan/"+list00[j][-26:],'a+').write(content) print "%2s is finshed." %(j) j = j + 1 #time.sleep(1)else: print "Write to file End." |
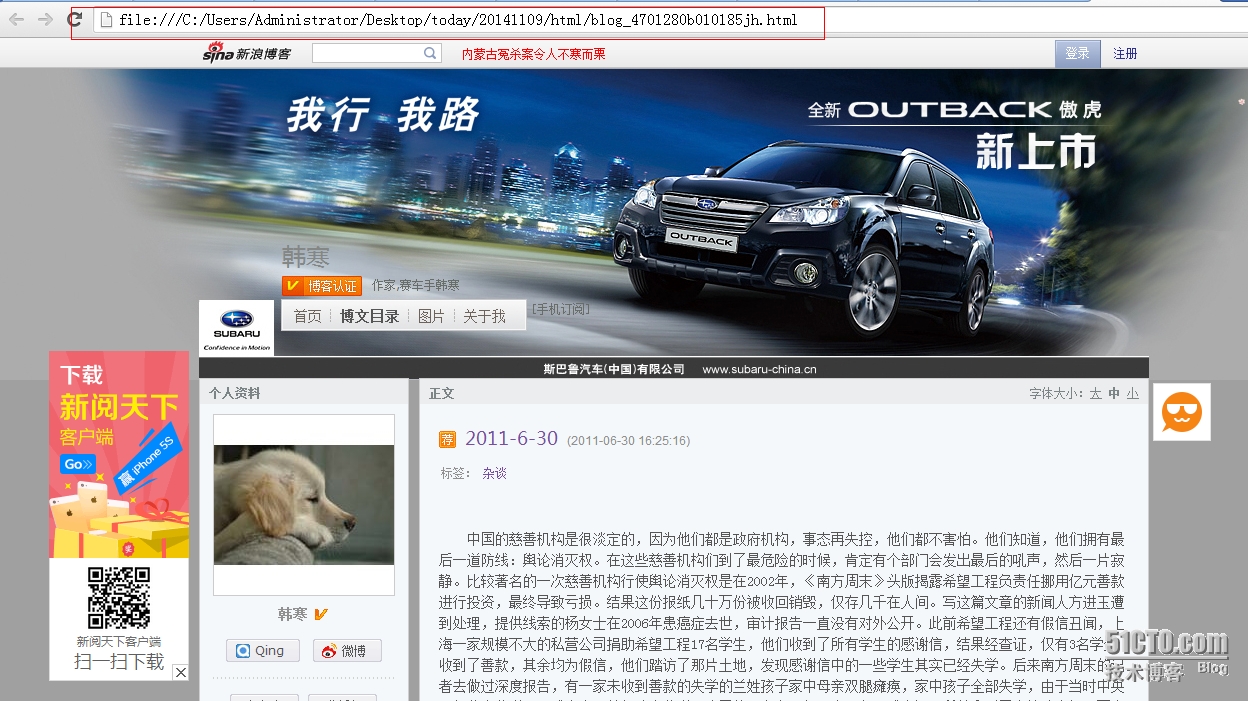
3、下载文章后的截图
 4、从linux下载到windows本地,然后打开查看;如下截图
4、从linux下载到windows本地,然后打开查看;如下截图
python之网络爬虫的更多相关文章
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- Python即时网络爬虫项目: 内容提取器的定义(Python2.7版本)
1. 项目背景 在Python即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间太多了(见上图),从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端 ...
- Python即时网络爬虫项目: 内容提取器的定义
1. 项目背景 在python 即时网络爬虫项目启动说明中我们讨论一个数字:程序员浪费在调测内容提取规则上的时间,从而我们发起了这个项目,把程序员从繁琐的调测规则中解放出来,投入到更高端的数据处理工作 ...
- Python即时网络爬虫:API说明
API说明——下载gsExtractor内容提取器 1,接口名称 下载内容提取器 2,接口说明 如果您想编写一个网络爬虫程序,您会发现大部分时间耗费在调测网页内容提取规则上,不讲正则表达式的语法如何怪 ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- Python 3网络爬虫开发实战》中文PDF+源代码+书籍软件包
Python 3网络爬虫开发实战>中文PDF+源代码+书籍软件包 下载:正在上传请稍后... 本书书籍软件包为本人原创,在这个时间就是金钱的时代,有些软件下起来是很麻烦的,真的可以为你们节省很多 ...
- Python 3网络爬虫开发实战中文 书籍软件包(原创)
Python 3网络爬虫开发实战中文 书籍软件包(原创) 本书书籍软件包为本人原创,想学爬虫的朋友你们的福利来了.软件包包含了该书籍所需的所有软件. 因为软件导致这个文件比较大,所以百度网盘没有加速的 ...
- Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包(免费赠送)+崔庆才
Python 3网络爬虫开发实战中文PDF+源代码+书籍软件包+崔庆才 下载: 链接:https://pan.baidu.com/s/1H-VrvrT7wE9-CW2Dy2p0qA 提取码:35go ...
- 《Python 3网络爬虫开发实战中文》超清PDF+源代码+书籍软件包
<Python 3网络爬虫开发实战中文>PDF+源代码+书籍软件包 下载: 链接:https://pan.baidu.com/s/18yqCr7i9x_vTazuMPzL23Q 提取码:i ...
随机推荐
- javascript设计模式与开发实践阅读笔记(6)——代理模式
代理模式:是为一个对象提供一个代用品或占位符,以便控制对它的访问. 代理模式的关键是,当客户不方便直接访问一个对象或者不满足需要的时候,提供一个替身对象来控制对这个对象的访问,客户实际上访问的是替身对 ...
- 设想 Docker 下部署 KVM
设想 Docker 下部署 KVM 一.安装 $ yum -y install kvm # kvm base , must $ yum -y install libvirt -y # libvirtd ...
- android: 创建自己的内容提供器
我们学习了如何在自己的程序中访问其他应用程序的数据.总体来说思 路还是非常简单的,只需要获取到该应用程序的内容 URI,然后借助 ContentResolver 进行CRUD 操作就可以了.可是你有没 ...
- Visual Studio 2012完美的拥抱GitHub
详情请查看http://www.aehyok.com/Blog/Detail/73.html 个人网站地址:aehyok.com QQ 技术群号:206058845,验证码为:aehyok 本文文章链 ...
- Java的自动装箱和拆箱的简单讲解
装箱就是把基础类型封装成一个类.比如把int封装成Integer,这时你就不能把他当成一个数了,而是一个类了,对他的操作就需要用它的方法了. 拆箱就是把类转换成基础类型.比如你算个加法什么的是不能用 ...
- 成功在神舟K650c-i7 d2(i7-4700MQ、HM87)上装好了Windows XP
成功在神舟K650c-i7 d2(i7-4700MQ.HM87)上装好了Windows XP 本来已经在K650c上装好了Windows7.Windows8双系统,奈何某些旧软件只能在Windows ...
- 导出Redis某个列表所有数据的语句
echo "smembers done:www.huaihua.gov.cn" | redis-cli -h 127.0.0.1 >> /home/dz/fkw.d ...
- Material Design练习
最近写了个小应用练习material design的控件使用,使用豆瓣V2 API访问豆瓣电影,程序很小,也就用了几个API而已,能够显示北美票房榜.电影排行榜,查看电影详情,以及进行电影搜索,可惜豆 ...
- 数据库中字段类型对应的C#中的数据类型
数据库中字段类型对应C#中的数据类型: 数据库 C#程序 int int32 text string bigint int64 binary System.Byte[] ...
- 菜鸟学JS(五)——window.onload与$(document).ready()
我们继续说JS,我们常常在页面加载完成以后做一些操作,比如一些元素的显示与隐藏.一些动画效果.我们通常有两种方法来完成这个事情,一个就是window.onload事件,另一个就是JQuery的read ...