Solr4+IKAnalyzer的安装配置
一、下载Solr4.10.2
我们以Windows版本为例,solr-4.10.2.zip是目前最新版本,下载地址:
http://www.apache.org/dyn/closer.cgi/lucene/solr/4.10.2
二、 Solr安装:
1、解压solr-4.10.2.zip
2、将 solr-4.10.2/example/webapps/solr.war 拷贝到Tomcat的webapps目录下(如D:\apache-tomcat-7.0.57\webapps),重新启动Tomcat 并访问http://localhost:8080/(目的是解压solr.war),然后你会发现solr-4.10.2/example/webapps/下多了一个Solr的目录。
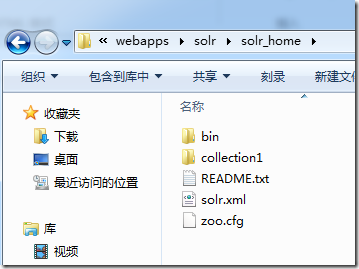
3、在D:\apache-tomcat-7.0.57\webapps\solr创建solr_home目录:
4、修改D:\apache-tomcat-7.0.57\webapps\solr\WEB-INF\web.xml 添加如下配置(apache-tomcat-7.0.56/webapps/solr/WEB-INF/web.xml)
配置solr home的地址:
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>
D:\apache-tomcat-7.0.57\webapps\solr\solr_home
</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
5、复制solr-4.10.2的solr-4.10.2/example/solr/ 所有内容copy到solr_home
6、复制solr-4.10.2的solr-4.10.2/example/lib/ext目录下所有文件
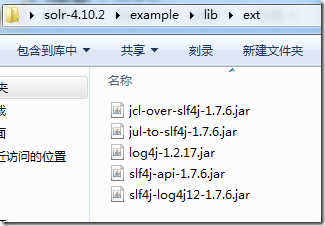
到 apache-tomcat-7.0.56/webapps/solr/WEB-INF/lib
复制solr-4.10.2的example/resources目录下的log4j.properties文件到Tomcat的lib下;
启动Tomcat。
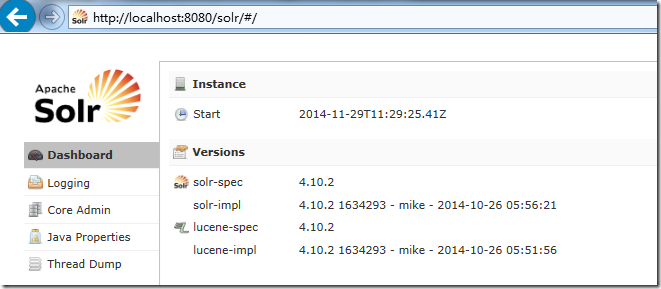
访问:http://localhost:8080/solr 进入到管理界面
三、 集成ikanalyzer中文分词器
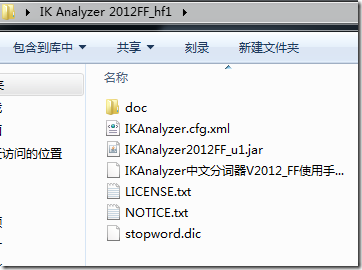
1、在谷歌http://code.google.com/p/ik-analyzer/downloads/list下载IK Analyzer 2012FF_hf1解压后得到如下目录结构:
2、将IKAnalyzer2012FF_u1.jar包copy到 apache-tomcat-7.0.56/webapps/solr/WEB-INF/lib 下。
在apache-tomcat-7.0.56/webapps/solr/WEB-INF/下创建classes目录
将IKAnalyzer.cfg.xml、stopword.dic copy到 apache-tomcat-7.0.56/webapps/solr/WEB-INF/classes
3、修改apache-tomcat-7.0.56/webapps/solr/solr_home/collection1/conf/schema.xml
在第一个节点内添加如下配置:
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
将对应需要用ik分词的字段的type改为以上定义的name值 text_ik(大约120行处):
<field name="sku" type="text_en_splitting_tight" indexed="true" stored="true" omitNorms="true"/>
<field name="name" type="text_ik" indexed="true" stored="true"/>
<field name="manu" type="text_ik" indexed="true" stored="true" omitNorms="true"/>
配置完成,重启tomcat并访问http://localhost:8080/solr。 发现左边可以选择分词器
根据我们配置的中文分词器,选择Manu:
分析一个熊孩子造的句子:小明吃完水果然后喝水
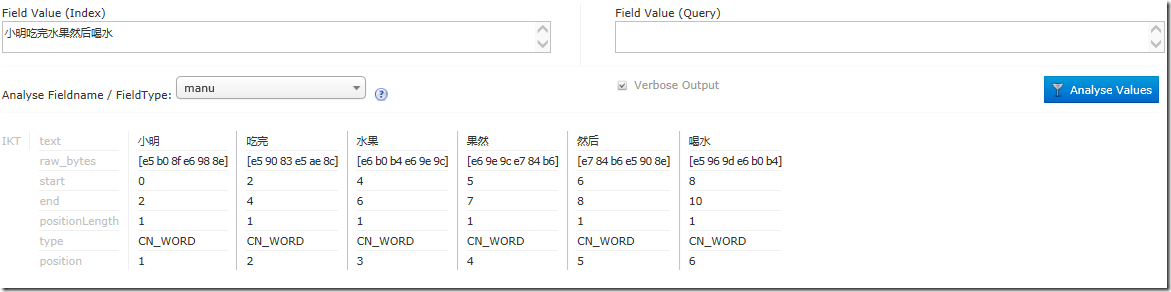
发现非常智能的构建出关键词了。
centos下面的配置:
创建solr目录
/usr/local/solr/tomcat
复制tomcat到指定目录cp apache-tomcat-7.0.47 /usr/local/solr/tomcat -r
将解压后的war复制到tomcat运行目录下cp solr-4.10.3.war /usr/local/solr/tomcat/webapps/solr.war
启动tomcat解压war包 ./startup.sh
查看启动情况:tail -f logs/catalina.out
关闭tomcat:./shutdown.sh
删除war包:rm -rf solr.war
复制lib包cp -f /root/solr-4.10.3/example/lib/ext/* /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib
创建solrhome:cp -r /root/solr-4.10.3/example/solr /usr/local/solr/solrhome
进入/usr/local/solr/tomcat/webapps/solr/WEB-INF/
修改web.xml中,注意去掉注释
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solr/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
然后启动,然后访问/solr/即可
配置分词
cp IKAnalyzer2012FF_u1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib
在/usr/local/solr/tomcat/webapps/solr/WEB-INF/
创建mkdir classes
复制配置文件cp ext_stopword.dic IKAnalyzer.cfg.xml mydict.dic /usr/local/solr/tomcat/webapps/solr/WEB-INF/classes
复制schema.xml到/usr/local/solr/solrhome/collection1/conf
cp -rf schema.xml /usr/local/solr/solrhome/collection1/conf
复制solrconfig.xml到/usr/local/solr/solrhome/collection1/conf
cp -rf solrconfig.xml /usr/local/solr/solrhome/collection1/conf
Solr4+IKAnalyzer的安装配置的更多相关文章
- 【转载】Solr4+IKAnalyzer的安装配置
转载:http://www.cnblogs.com/madyina/p/4131751.html 一.下载Solr4.10.2 我们以Windows版本为例,solr-4.10.2.zip是目前最新版 ...
- Solr4.10.3安装配置
系统环境 window版本为:windows 8.1 64位 软件环境 JDK版本:1.7 solr版本:4.10.3 tomcat版本:tomcat 7 安装过程 步骤一:将下载好的solr-4.1 ...
- solr4.5安装配置 linux+tomcat6.0+mmseg4j-1.9.1分词
首先先介绍下solr的安装配置 solr下载地址 (我这用的solr-4.5.0) 运行环境 JDK 1.5或更高版本 下载地址(Solr 4以上版本,要求JDK 1.6) 我用的JDK1.6 ) ...
- elasticsearch系列一:elasticsearch(ES简介、安装&配置、集成Ikanalyzer)
一.ES简介 1. ES是什么? Elasticsearch 是一个开源的搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础之上 用 Java 编写的,它的内部使用 Lucene 做索引 ...
- elasticsearch系列一elasticsearch(ES简介、安装&配置、集成Ikanalyzer)
一.ES简介 1. ES是什么? Elasticsearch 是一个开源的搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础之上 用 Java 编写的,它的内部使用 Lucene 做索引 ...
- Hive安装配置指北(含Hive Metastore详解)
个人主页: http://www.linbingdong.com 本文介绍Hive安装配置的整个过程,包括MySQL.Hive及Metastore的安装配置,并分析了Metastore三种配置方式的区 ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- ADFS3.0与SharePoint2013安装配置(原创)
现在越来越多的企业使用ADFS作为单点登录,我希望今天的内容能帮助大家了解如何配置ADFS和SharePoint 2013.安装配置SharePoint2013这块就不做具体描述了,今天主要讲一下怎么 ...
- Hadoop的学习--安装配置与使用
安装配置 系统:Ubuntu14.04 java:1.7.0_75 相关资料 官网 下载地址 官网文档 安装 我们需要关闭掉防火墙,命令如下: sudo ufw disable 下载2.6.5的版本, ...
随机推荐
- POJ 3686 & 拆点&KM
题意: 有n个订单,m个工厂,第i个订单在第j个工厂生产的时间为t[i][j],一个工厂可以生产多个订单,但一次只能生产一个订单,也就是说如果先生产a订单,那么b订单要等到a生产完以后再生产,问n个订 ...
- javascript为元素绑定事件响应函数
javascript中为元素设置响应时间有两种方法. (1):object.onclick=functionName; 这种方法不可以传递参数. (2):object.onclick=function ...
- A+B Problem 详细解答 (转载)
此为详细装13版 转载自:https://vijos.org/discuss/56ff2e7617f3ca063af6a0a3 全文如下,未作修改,仅供围观,不代表个人观点: 你们怎么都在做网络流,不 ...
- freemarker 直接使用List来遍历set集合,可能会报错
转摘:http://www.javaweb1024.com/java/JavaWebzhongji/2015/04/08/528.html freemarker 直接使用List来遍历set集合,可 ...
- 用Java通过串口发送手机短信
用Java通过串口发短信其实很简单,因为有现成的类库供我们使用.有底层的类库,也有封装好一点的类库,下面我介绍一下在 Win32 平台下发送短信的方法. 如果你想用更底层的类库开发功能更强大的应用程序 ...
- 使用edtftpj-***.jar上传下载中文问题的解决方案和注意点
FileTransferClient ftpClient = null; try { ftpClient = new FileTransferClient(); // set remote host ...
- FileStorage Read String Start With Number Need Quotation Mark 读取数字开头的字符串需要加引号
// Write data FileStorage fs("test.yml", FileStorage::WRITE); fs << "MyString&q ...
- CentOS网卡配置文件
[root@xaiofan ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0TYPE=EthernetONBOOT=yesNM ...
- Qt 程序退出时断言错误——_BLOCK_TYPE_IS_VALID(pHead->nBlockUse),由setAttribute(Qt::WA_DeleteOnClose)引起
最近在学习QT,自己仿写了一个简单的QT绘图程序,但是在退出时总是报错,断言错误: 报错主要问题在_BLOCK_TYPE_IS_VALID(pHead->nBlockUse),是在关闭窗口时报的 ...
- 【转】【Asp.Net MVC】asp.net mvc Model验证总结及常用正则表达式
本文属转载,来源: http://www.byywee.com/page/M0/S868/868615.html 关于Model验证官方资料: http://msdn.microsoft.com/zh ...