机器学习之KNN---k最近邻算法-机器学习
KNN算法是机器学习中入门级算法,属于监督性学习算法。SupervisedLearning.
通过Plinko游戏来介绍该算法。
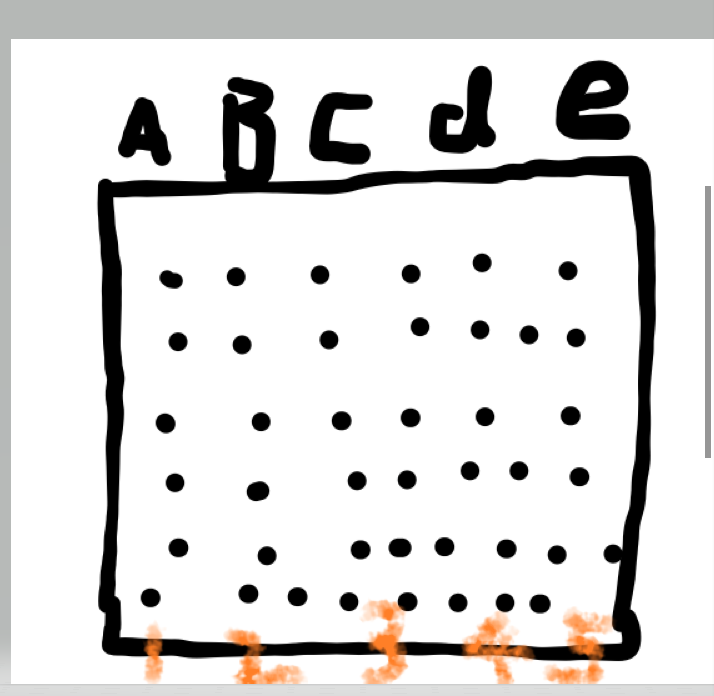
就是随机在上面投球,然后球进下面的哪个地方就得多少分。
然后在规定得投次数得到最高得分数,应该怎么投?
然后预测每次投能得到多少分?
首先应该通过训练数据集,看看在每个位置投得点,能得到多少分,然后预测点距离每次点得距离,然后排序,那么预测点周围出现次数最多得就是大概率得到得分数。
1,通过训练得数据集,提取特征值和标签,特征值就是距离左侧得距离。标签就是投下去得到得分数。
2,选择预测点,和K个距离近得数。计算每个点得距离。
3.排序,前K个点得出现最多次标签得就是得分得大概率值。
#KNN算法是寻找K个距离最近的邻居,然后根据已知的邻居label,出现次数最多的,推断出测试点的类别。
# polinko 模拟
import numpy as np
import collections as c def KNN(k,predictPoint,feature,label):
# 先求出预测点与周围点的距离,然后排序,找出距离最近的k个点,出现最多的次数,就是预测结果。
# map内置函数(func,iterable)
distance = list(map(lambda x: abs(200 - x), feature))
# np.sort()是直接排序,而我们需要feature和labell联系一起
# print(np.sort(distance))
# 所以应该使用np.argsort()可以得到排序的后的index,可以与label关联
sort_index = np.argsort(distance)
# 通过切片找出K个最邻近的点
return c.Counter(label[sort_index][:k]).most_common(1)[0][0] # 返回的是(4,2),表示在k的最邻近元素,4出现最多次数为2 if __name__ == '__main__':
data = np.array([
[120, 3],
[140, 3],
[160, 3],
[40, 2],
[70, 2],
[200, 4],
[250, 4],
[100, 3]
])
feature = data[:,0]
label = data[:,-1]
k = 5
predictPoint = 170
print(KNN(k,predictPoint,feature,label))
预测结果:
3
代码中给出的数据集是随机写的,不一定准。
现在选择真实的数据集,通过numpy中loadtext()读取csv文本数据集。
np.loadtxt("data01.csv",delimiter=",")这个第一个参数文件名称,第二个delimiter是数据分割符.
然后就和后面一样,提取特征值和标签值,计算k个局里近的距离。
但是和真实的还有有差距,这个是怎么回事。
所以造成结果不正确的原因有这些:
还需要
1.调整参数,简称调参。
2.可能还有其他维度特征会影响结果,但是现在只给了一种特征值。
缺点:对于数据量很大得训练集合,耗费内存。对硬件要求较高。
机器学习之KNN---k最近邻算法-机器学习的更多相关文章
- 机器学习【一】K最近邻算法
K最近邻算法 KNN 基本原理 离哪个类近,就属于该类 [例如:与下方新元素距离最近的三个点中,2个深色,所以新元素分类为深色] K的含义就是最近邻的个数.在sklearn中,KNN的K值是通过n ...
- 机器学习-K最近邻算法
一.介绍 二.编程 练习一(K最近邻算法在单分类任务的应用): import numpy as np #导入科学计算包import matplotlib.pyplot as plt #导入画图工具fr ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- PCB 加投率计算实现基本原理--K最近邻算法(KNN)
PCB行业中,客户订购5000pcs,在投料时不会直接投5000pcs,因为实际在生产过程不可避免的造成PCB报废, 所以在生产前需计划多投一定比例的板板, 例:订单 量是5000pcs,加投3%,那 ...
- 12、K最近邻算法(KNN算法)
一.如何创建推荐系统? 找到与用户相似的其他用户,然后把其他用户喜欢的东西推荐给用户.这就是K最近邻算法的分类作用. 二.抽取特征 推荐系统最重要的工作是:将用户的特征抽取出来并转化为度量的数字,然后 ...
- 《算法图解》——第十章 K最近邻算法
第十章 K最近邻算法 1 K最近邻(k-nearest neighbours,KNN)——水果分类 2 创建推荐系统 利用相似的用户相距较近,但如何确定两位用户的相似程度呢? ①特征抽取 对水果 ...
- [笔记]《算法图解》第十章 K最近邻算法
K最近邻算法 简称KNN,计算与周边邻居的距离的算法,用于创建分类系统.机器学习等. 算法思路:首先特征化(量化) 然后在象限中选取目标点,然后通过目标点与其n个邻居的比较,得出目标的特征. 余弦相似 ...
- K最近邻算法项目实战
这里我们用酒的分类来进行实战练习 下面来代码 1.把酒的数据集载入到项目中 from sklearn.datasets import load_wine #从sklearn的datasets模块载入数 ...
- 图说十大数据挖掘算法(一)K最近邻算法
如果你之前没有学习过K最近邻算法,那今天几张图,让你明白什么是K最近邻算法. 先来一张图,请分辨它是什么水果 很多同学不假思索,直接回答:“菠萝”!!! 仔细看看同学们,这是菠萝么?那再看下边这这张图 ...
随机推荐
- python装饰器参数那些事_接受参数的装饰器
# -*- coding: utf-8 -*- #coding=utf-8 ''' @author: tomcat @license: (C) Copyright 2017-2019, Persona ...
- jquery 自定义类
jQuery自定义类封装: (function ($) { $.DragField = function (arg) { var name = "你好"; //这个是私有变量,外部 ...
- Configuring IPMI under Linux using ipmitool
http://www.thomas-krenn.com/en/wiki/Configuring_IPMI_under_Linux_using_ipmitool Configuring IPMI und ...
- 测开之路五十:monggodb安装与初步使用
mongodb下载地址:https://www.mongodb.com/download-center Robo3T下载地址:https://robomongo.org/ 安装mongodb 双击无脑 ...
- laravel 简单应用 redis
1.连接配置 database.php 中 测试用 都没做修改 2.创建测试路由及控制器 //添加路由 Route::get('testRedis','RedisController@testRedi ...
- python字符串常用函数-大小写,删除空格,字符串切片
- Reciting(second)
It is subtly revealed in the caricature that a son is expressing his concern about disposing of nu ...
- HDU 1028 Ignatius and the Princess III (动态规划)
题目链接:HDU 1028 Problem Description "Well, it seems the first problem is too easy. I will let you ...
- Ubuntu添加与删除PPA源
目录 PPA,英文全称为 Personal Package Archives,即个人软件包档案.是 Ubuntu Launchpad 网站提供的一项源服务,允许个人用户上传软件源代码,通过 Launc ...
- 用vim写go代码——vim-go插件
GoImport:导入包 GoImport!:导入远程包 GoImportAs: 导入包并且重命名