01-scrapy框架
1.Scrapy图例:
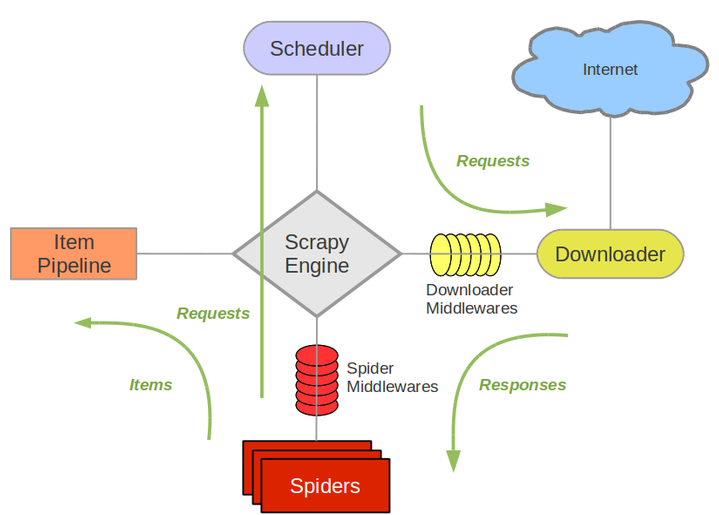
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
************************上述内容是对scrapy框架的一个简单介绍,内容摘自网络****************************
*****************************************************************************************
*********************下述内容为scrapy命令信息,以及爬虫起送后的信息做一简单的整理和描述********************
1、我们通过pip install scrapy安装好scrapy以后在终端键入scrapy,就会显示如下信息:
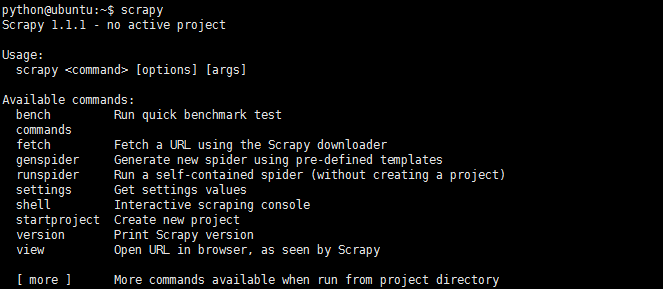
1).bench:快速测试当前硬件环境的性能,对于爬虫来说我们可以主要关注两个方面,一个是IO性能,一方面cpu的性能,IO主要取决于请求发送和相应的接收,cpu性能越强我们解析数据的速度就会越快
2).fetch:快速测试一个url地址是否能够使用,scrapy fetch 'http://www.baidu.com'
3).genspider:创建爬虫文件
4).runspider:运行爬虫
5).获取settings.py中某个字段的信息
6).shell终端界面,可用shell对我们设定的页面提取规则进行调试
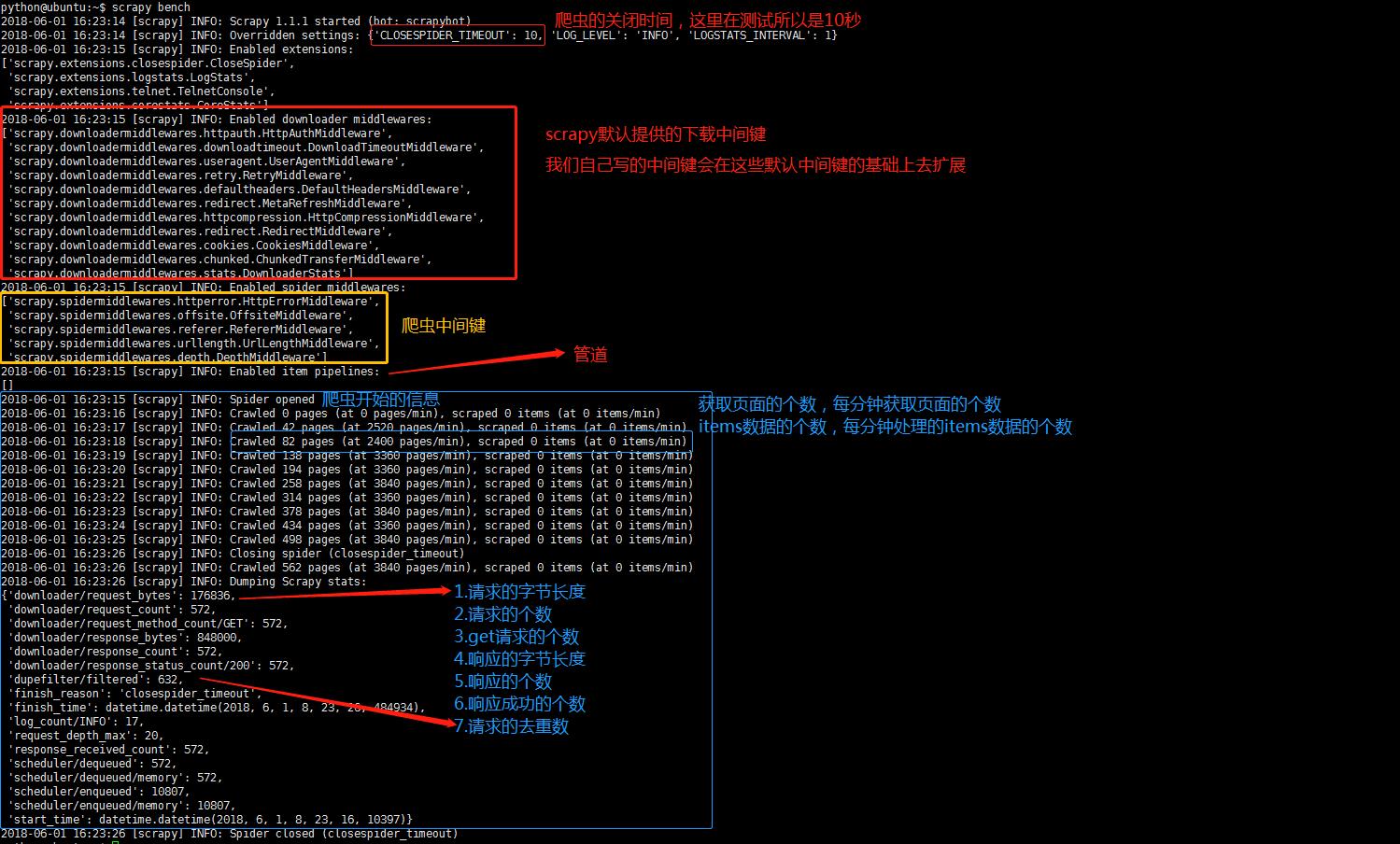
以scrapy bench为例,展示一下爬虫启动后的预加载信息以及具体的爬虫信息
01-scrapy框架的更多相关文章
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- Scrapy框架学习参考资料
00.Python网络爬虫第三弹<爬取get请求的页面数据> 01.jupyter环境安装 02.Python网络爬虫第二弹<http和https协议> 03.Python网络 ...
- Python 爬取 北京市政府首都之窗信件列表-[Scrapy框架](2020年寒假小目标04)
日期:2020.01.22 博客期:130 星期三 [代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明] //博客总体说明 1.准备工作(本期博客) 2.爬取工作 3.数据处理 4.信息展 ...
- Java多线程系列--“JUC锁”01之 框架
本章,我们介绍锁的架构:后面的章节将会对它们逐个进行分析介绍.目录如下:01. Java多线程系列--“JUC锁”01之 框架02. Java多线程系列--“JUC锁”02之 互斥锁Reentrant ...
- java多线程系类:JUC锁:01之框架
本章,我们介绍锁的架构:后面的章节将会对它们逐个进行分析介绍.目录如下:01. Java多线程系列--"JUC锁"01之 框架02. Java多线程系列--"JUC锁&q ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Java 集合系列 01 总体框架
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
随机推荐
- XSS绕过WAF的姿势
初始测试 1.使用无害的payload,类似<b>,<i>,<u> 观察响应,判断应用程序是否被HTML编码,是否标签被过滤,是否过滤<>等等: 2.如 ...
- opencv中对图片的二值化操作并提取特定颜色区域
一.最近因为所在的实习公司要求用opencv视觉库来写一个对图片识别并提取指定区域的程序.看了很多资料,只学会了皮毛,下面附上简单的代码.运行程序之前需要安装opencv库,官网地址为:https:/ ...
- 启用yarn的高可用
选择高可用的主机,新的一台: 点运行结束后,会看到实例会多出一个备用的节点:
- SpringBoot自动化配置之二:自动配置(AutoConfigure)原理、EnableAutoConfiguration、condition
自动配置绝对算得上是Spring Boot的最大亮点,完美的展示了CoC约定优于配置: Spring Boot能自动配置Spring各种子项目(Spring MVC, Spring Security, ...
- Comet OJ - Contest #13
Rank53. 第一次打这种比赛.还是有不少问题的,以后改吧. A题WA了两次罚了不少时. C写到一半发现只能过1,就先弃了. D一眼没看出来.第二眼看出来就是一个类似于复数的快速幂. 然后B切了. ...
- 解决iframe缓存机制导致页面不清除缓存不刷新页面的bug
在使用iframe时,已有页面嵌套了一个iframe页面,当这个页面提交后再次跳转到本页面时,原本iframe内的页面应该刷新数据的,结果未刷新,需要清除缓存后才刷新. 解决方案: var fresh ...
- Linux日常操作整理
1. Linux下建立ssh互信 需要在两台机器上保证安装ssh步骤:cd ~/.sshssh-keygen(每台机器执行此操作)ssh root@192.168.2.100 cat ~/.ssh/i ...
- linux c 链接详解3-静态库
3静态库 摘自:Linux C编程一站式学习 透过本节可以学会编译静态链接库的shell脚本! 有时候需要把一组代码编译成一个库,这个库在很多项目中都要用到,例如libc就是这样一个库,我们在不同的程 ...
- VIM如何自动保存文件、自动重加载文件、自动刷新显示文件
1.手动重加载文件的命令是:e! 2.一劳永逸的方法是:vim提供了自动加载的选项 autoread,默认关闭. 在vimrc中添加 set autoread即可打开自动加载选项,相关选项: :hel ...
- IBM小机拆镜像换盘
1.硬盘告警信息 2.故障排查 查看错误日志 # errpt -aj C62E1EB7 查看hdisk0的信息,发现hdisk0属于rootvg # lspv 查看hdi ...