数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化
1 标准化 & 归一化
导包和数据
import numpy as np
from sklearn import preprocessing data = np.loadtxt('data.txt', delimiter='\t')

1.1 标准化 (Z-Score)
x'=(x-mean)/std 原转换的数据为x,新数据为x′,mean和std为x所在列的均值和标准差
标准化之后的数据是以0为均值,方差为1的正态分布。
但是Z-Score方法是一种中心化方法,会改变原有数据的分布结构,不适合对稀疏数据做处理。
# 建立 StandardScaler 对象
z_scaler= preprocessing.StandardScaler() # 用 StandardScaler 对象对数据进行标准化处理
z_data = z_scaler.fit_transform(data)

1.2 归一化(Max-Min)
x'=(x-min)/(max-min),min和max为x所在列的最小值和最大值
将数据规整到 [0,1] 区间内(Z-Score则没有类似区间)
归一化后的数据能较好地保持原有数据结构。
数据中有异常值时,受影响比较大
# 建立MinMaxScaler模型对象
m_scaler = preprocessing.MinMaxScaler() # 使用 MinMaxScaler 对象 对数据进行归一化处理
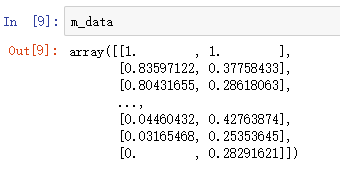
m_data = m_scaler.fit_transform(data)
2 离散化 / 分箱 / 分桶
离散化,就是把无限空间中有限的个体映射到有限的空间中
导包和数据
import pandas as pd
from sklearn.cluster import KMeans
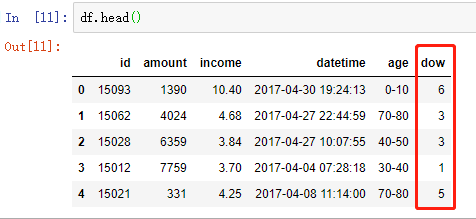
from sklearn import preprocessing df = pd.read_table('data1.txt', names=['id', 'amount', 'income', 'datetime', 'age'])
数据基本情况

2.1 针对时间数据的离散化
方法 1 :使用 pd.to_datetime 及 dt.dayofweek
# 将数据转成 datetime 类型
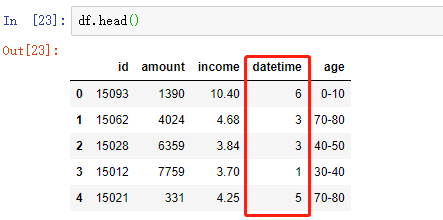
df['datetime'] = pd.to_datetime(df['datetime']) # 显示 周几
df['dow'] = df['datetime'].dt.dayofweek
方法 2:纯手工打造(可以忽略了)
# 将时间转换为datetime格式,Python3中,map返回一个迭代器,所以需要list一下,把其中的值取出来
df['datetime'] = list(map(pd.to_datetime,df['datetime']))
# 离散化为 周几 的格式
df['datetime']= [i.weekday() for i in df['datetime']]
2.2 针对连续数据的离散化
连续数据的离散化结果可以分为两类:
一类是将连续数据划分为特定区间的集合,例如{(0,10],(10,20],(20,50],(50,100]}
一类是将连续数据划分为特定类,例如类1、类2、类3
常见实现针对连续数据化离散化的方法如下。
分位数法:使用四分位、五分位、十分位等分位数进行离散化处理
距离区间法:可使用等距区间或自定义区间的方式进行离散化,该方法(尤其是等距区间)可以较好地保持数据原有的分布
频率区间法:将数据按照不同数据的频率分布进行排序,然后按照等频率或指定频率离散化,这种方法会把数据变换成均匀分布。好处是各区间的观察值是相同的,不足会改变了原有数据的分布状态。每个桶里的数值个数是相同的
聚类法:例如使用 K 均值将样本集分为多个离散化的簇
2.2.1 距离区间法:自定义分箱区间实现离散化
# 自定义区间边界
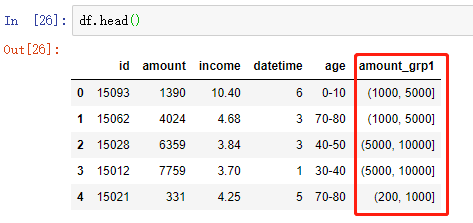
bins = [0, 200, 1000, 5000, 10000]
# 按照给定区间 使用 pd.cut 将数据进行离散化
df['amount_grp1'] = pd.cut(df['amount'], bins=bins)
附:实现离散化 并添加自定义标签(另外一份数据中的)
bins = [0,2,10,300]
labels = [ '<2', '<10','<300'] # right == False : 左闭右开,不加此项,默认为左开右闭的
df['price_level'] = pd.cut(df.price,bins=bins,labels=labels, right=False)
2.2.2 频率区间法:按照等频率或指定频率离散化
df['amount3'] = pd.qcut(df['amount'], 4, labels=['bad', 'medium', 'good', 'awesome'])
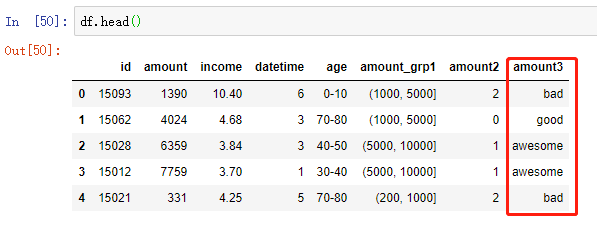
2.2.3 聚类法实现离散化
# 获取要聚类的数据
df_clu = df[['amount']] # 创建 KMeans 模型并指定要聚类数量
model_kmeans = KMeans(n_clusters=4, random_state=111) # 建模聚类
kmeans_result = model_kmeans.fit_predict(df_clu) # 将新离散化的数据合并到原数据框
df['amount2'] = kmeans_result
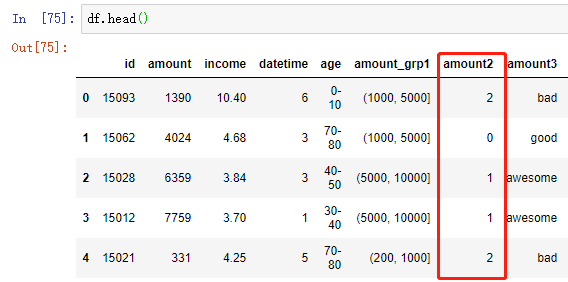
对第 5 行代码的补充:
创建KMeans模型并指定要聚类数量,分成4组
random_state 随机数种子,指定之后,每次划分的训练集测试集划分方式相同
如果指定的random_state相同,每次生成的随机数都是一样的
3 二值化
根据某一阈值,将数据分成两类,得到一个只拥有两个值域的二值化数据集
# 建立Binarizer模型对象,利用income这一列的平均值作为阈值,进行二值化
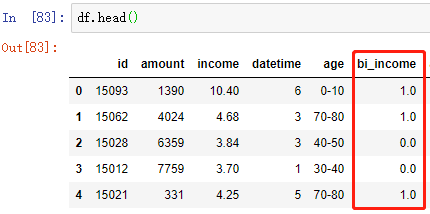
bi_scaler = preprocessing.Binarizer(threshold=df['income'].mean()) # Binarizer标准化转换
bi_income = bi_scaler.fit_transform(df[['income']])
df['bi_income'] = bi_income
数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化的更多相关文章
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 机器学习之数据预处理,Pandas读取excel数据
Python读写excel的工具库很多,比如最耳熟能详的xlrd.xlwt,xlutils,openpyxl等.其中xlrd和xlwt库通常配合使用,一个用于读,一个用于写excel.xlutils结 ...
- 机器学习入门-数值特征-进行二值化变化 1.Binarizer(进行数据的二值化操作)
函数说明: 1. Binarizer(threshold=0.9) 将数据进行二值化,threshold表示大于0.9的数据为1,小于0.9的数据为0 对于一些数值型的特征:存在0还有其他的一些数 二 ...
- 数据预处理:规范化(Normalize)和二值化(Binarize)
注:本文是人工智能研究网的学习笔记 规范化(Normalization) Normalization: scaling individual to have unit norm 规范化是指,将单个的样 ...
- python的N个小功能(图片预处理:打开图片,滤波器,增强,灰度图转换,去噪,二值化,切割,保存)
############################################################################################# ###### ...
- 数据预处理 | 使用 Pandas 统一同一特征中不同的数据类型
出现的问题:如图,总消费金额本应该为float类型,此处却显示object 需求:将 TotalCharges 的类型转换成float 使用 pandas.to_numeric(arg, errors ...
- 数据预处理 | 使用 pandas.to_datetime 处理时间类型的数据
数据中包含日期.时间类型的数据可以通过 pandas 的 to_datetime 转换成 datetime 类型,方便提取各种时间信息 1 将 object 类型数据转成 datetime64 1&g ...
- python数据预处理和特性选择后列的映射
我们在用python进行机器学习建模时,首先需要对数据进行预处理然后进行特征工程,在这些过程中,数据的格式可能会发生变化,前几天我遇到过的问题就是: 对数据进行标准化.归一化.方差过滤的时候数据都从D ...
- 数据准备<3>:数据预处理
数据预处理是指因为算法或者分析需要,对经过数据质量检查后的数据进行转换.衍生.规约等操作的过程.整个数据预处理工作主要包括五个方面内容:简单函数变换.标准化.衍生虚拟变量.离散化.降维.本文将作展开介 ...
随机推荐
- Ajax0001:ajax介绍 JSON数据处理
- SAP SD 销售中的借贷项凭证
SAP SD 销售中的借贷项凭证 SAP系统中,正常与客户的应收款都能通过销售订单来实现. 但实际操作中,常有收款后发现价格有误或其他原因需退款客户或补收客户货款的情况,或者客户需要少量的材料,但不能 ...
- GitLab Runner
GitLab Runner是一个开源项目,用于运行你的作业(jobs)并将结果发送回GitLab.它与GitLab CI结合使用,GitLab CI是GitLab用于协调jobs的开源持续集成服务. ...
- linux中压缩解压缩命令
目录 gzip gunzip tar(打包压缩) tar(解包解压) zip unzip bzip2 bunzip2 gzip 解释 命令名称:gzip 命令英文原意:GUN zip 命令所在路径:/ ...
- 第10章 DOM
第10章 DOM 10.1 节点层次 10.1.1 Node 类型 10.1.2 Document 类型 10.1.3 Element 类型 10.1.4 Text 类型 10.1.5 Comment ...
- OpenCASCADE(一) VS2017+OpenCASCADE+MFC 下载配置安装运行单文档程序画个基本图形
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/12368154.html 一.下载OpenCASCADE 官网下载是: http://www.o ...
- 刷题84. Largest Rectangle in Histogram
一.题目说明 题目84. Largest Rectangle in Histogram,给定n个非负整数(每个柱子宽度为1)形成柱状图,求该图的最大面积.题目难度是Hard! 二.我的解答 这是一个 ...
- 15.python文件(file)方法详解
文件的基本操作 文件读写: 文件的读写满足以下3个步骤: 1).打开文件 2).操作数据(读.写) 3).关闭文件 --> 不要忘记 1).打开文件: python的open() 方法用于打开一 ...
- C++ Primer 抄书笔记(一)
操作系统通过调用main函数(function)来运行C++程序: int main(){ ; } main函数返回类型必为int.大多数系统中main的返回值被用来指示状态.0即成功:非0由系统定义 ...
- JS高阶编程技巧--惰性函数
在vue.react等框架大量应用之前,我们需要使用jQuery或者原生js来操作dom写代码,在用原生js进行事件绑定时,我们可以应用DOM2级绑定事件的方法,即:元素.addEventListen ...