数据预处理 | 使用 Pandas 统一同一特征中不同的数据类型
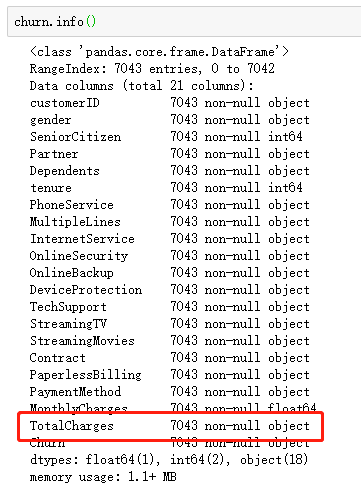
出现的问题:如图,总消费金额本应该为float类型,此处却显示object
需求:将 TotalCharges 的类型转换成float
使用 pandas.to_numeric(arg, errors='raise', downcast=None) 方法,可将参数转换为数字类型。
(别的类型转换,遇到再补充)
df = pd.read_excel('./data_files/Using_Customer-Churn.xlsx')
# 将df.TotalCharges 转成数字类型的数据,则将无效解析设置为NaN
df.TotalCharges = pd.to_numeric(df.TotalCharges, errors='coerce')
df.isnull().sum()
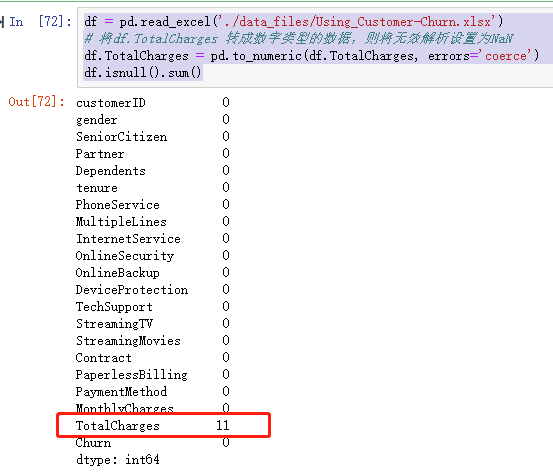
此时,转换完成!
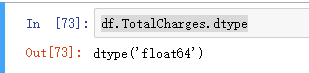
关于pandas.to_numeric 方法的详细信息可参见:https://www.cjavapy.com/article/532/
—————————— 手动分隔,以下为原来的野生思路 —————————
1 首先要找出本特征中,包含的数据类型究竟有哪些
# 创建一个用于盛放数据类型的列表
test_type = list() for i in churn["TotalCharges"]: # 将数据类型 不重复的放入列表中
if type(i) not in test_type:
test_type.append(type(i))
print(test_type) """
[<class 'float'>, <class 'int'>, <class 'str'>]
"""
2 查看除 float 和 int 之外的类型的数据有哪些
# 创建用于盛放数据的列表
str_values= list() for i in churn["TotalCharges"]:
if type(i) != float and type(i) != int:
# 将既不是 float 也不是 int 的数据加到列表
str_values.append(i) print(str_values) """
[' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ']
"""
此时得到:非数值型数据均为空格。
3 将数据统一为 float 类型
# 空值替换所有空格
churn['TotalCharges'] = churn["TotalCharges"].replace(" ",np.nan)
# 去掉含有空值的样本
churn = churn[churn["TotalCharges"].notnull()]
# 将 TotalCharges 转换成 float类型
churn['TotalCharges'] = churn['TotalCharges'].astype(float)
此时
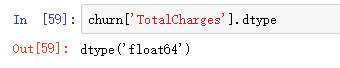
大功告成!
遍历的方法,相对来说效率略低,Pandas 应该有什么方法,更加直接吧
纯野生思路,找到更好的办法再更新~
数据预处理 | 使用 Pandas 统一同一特征中不同的数据类型的更多相关文章
- 机器学习之数据预处理,Pandas读取excel数据
Python读写excel的工具库很多,比如最耳熟能详的xlrd.xlwt,xlutils,openpyxl等.其中xlrd和xlwt库通常配合使用,一个用于读,一个用于写excel.xlutils结 ...
- 数据预处理 | 使用 pandas.to_datetime 处理时间类型的数据
数据中包含日期.时间类型的数据可以通过 pandas 的 to_datetime 转换成 datetime 类型,方便提取各种时间信息 1 将 object 类型数据转成 datetime64 1&g ...
- 数据预处理 | 使用 Pandas 进行数值型数据的 标准化 归一化 离散化 二值化
1 标准化 & 归一化 导包和数据 import numpy as np from sklearn import preprocessing data = np.loadtxt('data.t ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(十三):sklearn中的数据预处理和特征工程(六)特征选择 feature_selection 简介
当数据预处理完成后,我们就要开始进行特征工程了. 在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人, ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
随机推荐
- ExecutionContext(执行上下文)综述
>>返回<C# 并发编程> 1. 简介 2. 同步异步对比 3. 上下文的捕获和恢复 4. Flowing ExecutionContext vs Using Synchron ...
- 01-Flink运行架构
1.flink运行时的组件 Flink 运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作: 作业管理器(JobManager).资源管理器(ResourceManager). ...
- windows7精简iso
网站地址: https://www.90pan.com/b1268487 迅雷链接: magnet:?xt=urn:btih:EE4B0FE780B6EC97D6FB9A9D22A8EE1627DA7 ...
- 如何修改Tomcat运行时jvm编码
问题: 最近在部署项目的时候出现数据乱码的情况,经过一番查看项目都是用的UTF-8编码格式,数据也是,但是经过调用接口传给对方就乱码了. 由于是部署在Windows环境下,Windows默认编码GBK ...
- elsearch搜索引擎 + painless脚本语言入门
最近项目用到了elsearch,ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎. 自从版本6.0之后,其默认脚本语言变为 painless . ...
- Java-利用位数猜年龄
题目: 美国数学家维纳(N.Wiener)智力早熟,11岁就上了大学.他曾在1935~1936年应邀来中国清华大学讲学.一次,他参加某个重要会议,年轻的脸孔引人注目.于是有人询问他的年龄,他回答说:“ ...
- Python爬虫连载3-Post解析、Request类
一.访问网络的两种方法 1.get:利用参数给服务器传递信息:参数为dict,然后parse解码 2.post:一般向服务器传递参数使用:post是把信息自动加密处理:如果想要使用post信息,需要使 ...
- STL中的Set和Map——入门新手篇
STL中的Set和Map 先来看一段网络上的文字描述: 上图是一段关于STL中Set集合的描述,同样的,也近似适合Map的描述.上述文字中,描述了最为重要的特征: Set和Map,底层调用了红黑树的结 ...
- 《茶余饭后小故事》MV*、MVC、MVP、MVVM的前世今生
今天我们讲讲历史,讲讲故事,不扯高深术语. MV*表示的意思是:M(Model逻辑层) + View(视图层) + *(中间者).上帝提出了这个逻辑与视图分离,用中间者进行连接的伟大思想,并将实现这个 ...
- centos7 lnmp环境搭建
1- 安装gcc c++编译器 yum install gcc gcc-c++ cmake 2- 安装nginx-1.8.1及依赖包 2.1- 安装nginx依赖包 yum -y install pc ...