linux内核IDR机制详解【转】
这几天在看Linux内核的IPC命名空间时候看到关于IDR的一些管理性质的东西,刚开始看有些迷茫,深入看下去豁然开朗的感觉,把一些心得输出共勉。
我们来看一下什么是IDR?IDR的作用是什么呢?
先来看下IDR的作用:IDR主要实现ID与数据结构的绑定。刚开始看的时候感觉到有点懵,什么叫“ID与数据结构的绑定”?举一个例子大家就会明白了:在IPC通信的时候先要动态获取一个key值或者使用现有的key值进行通信,那么系统怎么知道这个key值是否使用了呢?这个就需要IDR来进行判断了。以上就是IDR的一些浅显的概念,IDR本质上就是通过对于ID一些有效的管理进而管理和这些ID有关的数据结构----不限于IPC通信的key值。
IDR怎么对于数据ID管理呢?传统上我们对于未使用的ID进行管理的时候可以使用位图进行管理,也可以使用数组进行管理,也可以使用链表进行ID管理,三个个各有优缺点:
- 使用位图进行管理的时候优点是使用空间少,但是对于位图对应的数据结构支持不太友好。
- 使用数组进行管理的时候寻址快速,但是只能管理比较少量的ID数目。
- 使用链表进行管理的时候虽然可以支持大量的数据ID,但是通过链表的指针寻址比较慢。
所以引入了以上三者的优点进行IDR管理。
IDR管理的核心
IDR把每一个ID分级数据进行管理,每一级维护着ID的5位数据,这样就可以把IDR分为7级进行管理(5*7=35,维护的数据大于32位),如下所示:
31 30 | 29 28 27 26 25 | 24 23 22 21 20 | 19 18 17 16 15 | 14 13 12 11 10 | 9 8 7 6 5 | 4 3 2 1 0
例如数据ID为0B 10 11111 10011 00111 11001 100001 00001,寻址如下:
1. 第一级寻址 ary1[0b10]得到第二级地址ary2[]
2. ary3 = ary2[0b11111]
3. ary4 = ary3[ob10011]
4. ary5 = ary4[0b00111]
5. ary6 = ary5[0b11001]
6. ary7 = ary6[0b100001]
7. ary8 = ary7[0b00001]
ary8即为要寻址到的ID对应的IDR指针。
如下图:
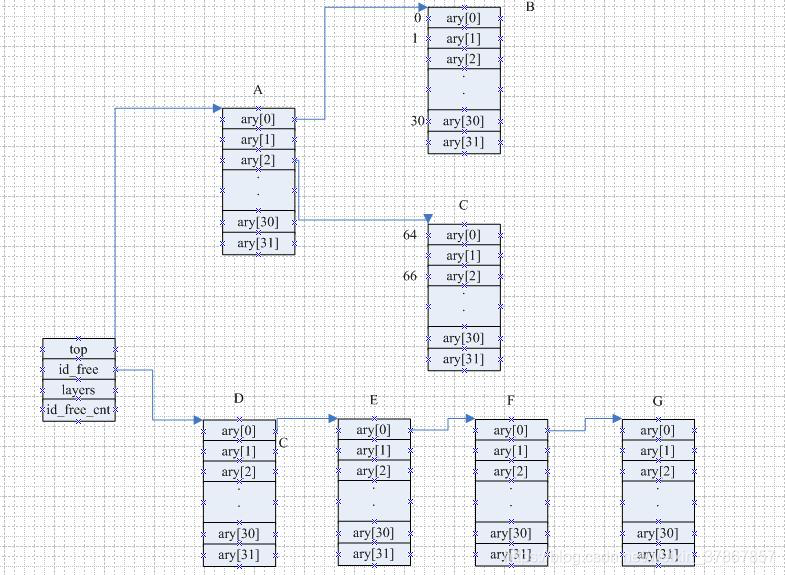
上图中每一个分级中的IDR数组中的值不为空代表相应位有效的ID位,但是使用数组下标标示有效的ID位还是有点慢----需要通过数组下标以及数组内容判断有效的ID位,所以对于每一个IDR引入了有效的ID位图来表示,每一个位图为32位刚好给出了相应的有效的ID位。方便查找。
上图中只是使用了IDR的32个数组表示,并没有给出IDR的位图以及层数标志,下面给出相应的数据结构:
IDR 数据结构:
struct idr_layer {
//位图,ary数组结构哪个有效
unsigned long bitmap; /* A zero bit means "space here" */
//IDR数组
struct idr_layer __rcu *ary[1<<IDR_BITS];
标示
int count; /* When zero, we can release it */
//层数,代表所在的ID位
int layer; /* distance from leaf */
struct rcu_head rcu_head;
};
struct idr {
//IDR层数头,实际上就是32叉树
struct idr_layer __rcu *top;
//尚未使用的IDR
struct idr_layer *id_free;
//层数
int layers; /* only valid without concurrent changes */
//id_free未用的个数;
int id_free_cnt;
spinlock_t lock;
};
下面讨论一下IDR的初始化以及增删改查ID问题:
- IDR的初始化
- IDR的增加
- IDR的查找
IDR的初始化:
IDR的初始化相对来说比较简单,使用IDR_INIT可以初始化一个IDR,原型如下:
#define IDR_INIT(name) \
{ \
.top = NULL, \
.id_free = NULL, \
.layers = 0, \
.id_free_cnt = 0, \
.lock = __SPIN_LOCK_UNLOCKED(name.lock), \
}
可以看到IDR只是把各个数据值为零,原子锁初始化下。
IDR的增加:
IDR增加比较复杂,在C中编程大部分情况可以分为如下两点讨论:
1.idr.top为NULL的情况;
2.idr.top不为NULL的情况;
以上考虑问题也是可以的,但是没有考虑到如下问题:
每一个idr_layer结构体有一个layer标示,我们每每增加一层,就要遍历整个idr的32叉树。无形中增加了系统负担。
idr设计者在考虑问题时候恰恰相反,没增加一个idr_layer层,就把要增加的idr_layer->ary[0]指向旧的idr_layer树的根,把要增加idr_layer->layer赋予旧的根部的idr_layer->layer + 1值,这样就不会考虑到idr->top为NULL的情况了。ps:只需要判断在增加第一个idr_layer时候判断一下,并且把idr_layer->layer值赋为0.
IDR的查找:
在查找IDR时侯会先查找IDR根节点,然后根据ID位所在的层的值遍历IDR树,如果查找到某一段树为NULL,则会返回NULL。
以下是IDR查找的过程:
void *idr_find(struct idr *idp, int id)
{
int n;
struct idr_layer *p;
//获取根IDR
p = rcu_dereference_raw(idp->top);
if (!p)
return NULL;
/**
根据IDR的层数获取要遍历的个数;
**/
n = (p->layer+1) * IDR_BITS;
/* 去除我们不需要查找的位数. */
id &= MAX_ID_MASK;
/***如果ID值大于n, 1<<n为根据层数换算过来的ID的最大值**/
if (id >= (1 << n))
return NULL;
BUG_ON(n == 0);
/***
遍历顺序:28---->0,每次减少5位,可以遍历完全IDR的32叉树
***/
while (n > 0 && p) {
n -= IDR_BITS;
BUG_ON(n != p->layer*IDR_BITS);
p = rcu_dereference_raw(p->ary[(id >> n) & IDR_MASK]);
}
return((void *)p);
}
linux内核IDR机制详解【转】的更多相关文章
- linux 内核 RCU机制详解
RCU(Read-Copy Update)是数据同步的一种方式,在当前的Linux内核中发挥着重要的作用.RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数 ...
- linux内核 RCU机制详解【转】
本文转载自:https://blog.csdn.net/xabc3000/article/details/15335131 简介 RCU(Read-Copy Update)是数据同步的一种方式,在当前 ...
- Linux内核ROP姿势详解(二)
/* 很棒的文章,在freebuf上发现了这篇文章上部分的翻译,但作者貌似弃坑了,顺手把下半部分也翻译了,原文见文尾链接 --by JDchen */ 介绍 在文章第一部分,我们演示了如何找到有用的R ...
- Linux内核异常处理体系结构详解(一)【转】
转自:http://www.techbulo.com/1841.html 2015年11月30日 ⁄ 基础知识 ⁄ 共 6653字 ⁄ 字号 小 中 大 ⁄ Linux内核异常处理体系结构详解(一)已 ...
- [转]Linux内核源码详解--iostat
Linux内核源码详解——命令篇之iostat 转自:http://www.cnblogs.com/york-hust/p/4846497.html 本文主要分析了Linux的iostat命令的源码, ...
- Linux find运行机制详解
本文目录: 1.1 find基本用法示例 1.2 find理论部分 1.2.1 expression-operators 1.2.2 expression-options 1.2.3 expressi ...
- linux内核 idr机制
idr机制解决了什么问题?为什么需要idr机制(或者说,idr机制这种解决方案,相对已有的其他方案,有什么优势所在) ? idr在linux内核中指的就是整数ID管理机制,从本质上来说,这就是一种将整 ...
- 嵌入式Linux内核I2C子系统详解
1.1 I2C总线知识 1.1.1 I2C总线物理拓扑结构 I2C总线在物理连接上非常简单,分别由SDA(串行数据线)和SCL(串行时钟线)及上拉电阻组成.通信原理是通过对SCL和SDA线高 ...
- linux内核调优详解
cat > /etc/sysctl.conf << EOF net.ipv4.ip_forward = net.ipv4.conf.all.rp_filter = net.ipv4. ...
随机推荐
- the python challenge闯关记录(9-16)
9 第九关 是一张图,上面有很多的黑点,查看网页源代码发现了上一关的提示: 还发现了一大串的数字 感觉又是一个使用PIL库进行图像处理的题,百度后知道要将这些点连接起来并重新画图.但是不能在原始图上修 ...
- Mysql的两种偏移量分页写法
当一个查询语句偏移量offset很大的时候,如select * from table limit 10000,10 , 先获取到offset的id后,再直接使用limit size来获取数据,效率会有 ...
- git push 时提示用户名或密码相关错误信息
这里讲的是一个常见的第一次push提示输入用户名密码时,输入错误的解决办法.它导致在后面其他项目什么的在push的时候一直失败,并提示有用户名密码错误信息. 第一步:进入到“控制面板” (这里如何进入 ...
- 【Spark篇】---Spark故障解决(troubleshooting)
一.前述 本文总结了常用的Spark的troubleshooting. 二.具体 1.shuffle file cannot find:磁盘小文件找不到. 1) connection timeout ...
- BBS论坛(二十四)
24.1.编辑板块 cms/js/banners.js $(function () { $('.edit-board-btn').click(function () { var self = $(th ...
- JVM基础系列第8讲:JVM 垃圾回收机制
在第 6 讲中我们说到 Java 虚拟机的内存结构,提到了这部分的规范其实是由<Java 虚拟机规范>指定的,每个 Java 虚拟机可能都有不同的实现.其实涉及到 Java 虚拟机的内存, ...
- .NET Core实战项目之CMS 第十章 设计篇-系统开发框架设计
这两天比较忙,周末也在加班,所以更新的就慢了一点,不过没关系,今天我们就进行千呼万唤的系统开发框架的设计.不知道上篇关于架构设计的文章大家有没有阅读,如果阅读后相信一定对架构设计有了更近一部的理解,如 ...
- 『左偏树 Leftist Tree』
新增一道例题 左偏树 Leftist Tree 这是一个由堆(优先队列)推广而来的神奇数据结构,我们先来了解一下它. 简单的来说,左偏树可以实现一般堆的所有功能,如查询最值,删除堆顶元素,加入新元素等 ...
- Hive 导入 parquet 格式数据
Hive 导入 parquet 数据步骤如下: 查看 parquet 文件的格式 构造建表语句 倒入数据 一.查看 parquet 内容和结构 下载地址 社区工具 GitHub 地址 命令 查看结构: ...
- [Leetcode]237. Delete Node in a Linked List -David_Lin
Write a function to delete a node (except the tail) in a singly linked list, given only access to th ...