SQL笛卡尔积查询与关联查询性能对比
首先声明一下,sql会用略懂,不是专家,以下内容均为工作经验,聊以抒情。
今天帮忙验证同事发布的端口时,查看了一下相关sql内容,发现其使用的sql语句会导致笛卡尔积现象,为了帮其讲解进行了如下分析:
student表:
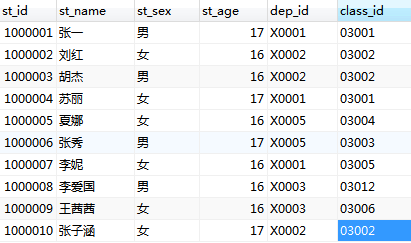
teacher表:

course表:

student_course表:
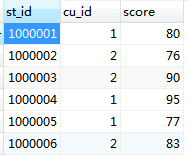
与发现问题类似的SQL1查询语句:
SELECT
d.st_name,d.class_id,d.st_id
FROM
course AS a,
student_course AS b,
teacher AS c,
student AS d
WHERE
a.cu_id = b.cu_id
AND b.st_id = d.st_id
AND c.dep_id = d.dep_id
AND a.cu_name = '英语';
采用内关联的SQL2语句:
SELECT
student.st_name,
student.class_id,
student.st_id
FROM
course
JOIN student_course USING ( cu_id )
JOIN student USING ( st_id )
JOIN teacher USING ( dep_id )
WHERE
course.cu_name = '英语';
执行时间对比(已经多次验证):
SELECT
d.st_name,d.class_id,d.st_id
FROM
course AS a,
student_course AS b,
teacher AS c,
student AS d
WHERE
a.cu_id = b.cu_id
AND b.st_id = d.st_id
AND c.dep_id = d.dep_id
AND a.cu_name = '英语'
> OK
> 时间: 0.002s SELECT
student.st_name,
student.class_id,
student.st_id
FROM
course
JOIN student_course USING ( cu_id )
JOIN student USING ( st_id )
JOIN teacher USING ( dep_id )
WHERE
course.cu_name = '英语'
> OK
> 时间: 0.001s
分析原因:
在不加course.cu_name = '英语'这条约束条件时,我们对比一下查询结果内容,如下所示SQL1查询结果:

SQL2查询结果:

可以看出SQL1结果的字段多于SQL2,当数据量很大或相关表字段更多时,通过where的条件查询会在性能上有明显的区别,因此建议sql编写时注意相关方法的使用以提升性能。
只是个小实验,详细解释可参考该贴:https://www.cnblogs.com/alianbog/p/5618349.html
盗图一枚,敬请见谅。
SQL笛卡尔积查询与关联查询性能对比的更多相关文章
- Mongoose如何实现统计查询、关联查询
[问题]Mongoose如何实现统计查询.关联查询 发布于 4 年前 作者 a272121742 13025 次浏览 最近业务上提出一个需求,要求能做统计,我们设计的文档集,统计可能跨越的文档会 ...
- MySQL查询(关联查询)
一.mysql查询与权限 (一)数据库关联查询 **内连接查询(inner join)** 查询两个表共有的数据,交集 SELECT * FROM tb1 INNER JOIN tb2 ON 条件 所 ...
- Oracle SQL——varchar2() 和 char()关联查询 存在空格
背景 表dbcontinfo 字段loanid,类型为varchar2(60) 表dbloanbal 字段loanid,类型为char(60) loanid字段实际长度为24位 问题 两张表dbloa ...
- Mybatis高级查询之关联查询
learn from:http://www.mybatis.org/mybatis-3/zh/sqlmap-xml.html#Result_Maps 关联查询 准备 关联结果查询(一对一) resul ...
- mysql系列九、mysql语句执行过程及运行原理(分组查询和关联查询原理)
一.背景介绍 了解一个sql语句的执行过程,了解一部分都做了什么,更有利于对sql进行优化,因为你知道它的每一个连接.where.分组.子查询是怎么运行的,都干了什么,才会知道怎么写是不合理的. 大致 ...
- day95:flask:SQLAlchemy数据库查询进阶&关联查询
目录 1.数据库查询-进阶 1.常用的SQLAlchemy查询过滤器 2.常用的SQLAlchemy查询结果的方法 3.filter 4.order_by 5.count 6.limit&of ...
- 11 MySQL_分组查询和关联查询
分组查询 group by 将某个字段的相同值分为一组,对其他字段的数据进行聚合函数的统计,称为分组查询 单字段分组查询 1.查询每个部门的平均工资 select dept_id,avg(sal) f ...
- Mysql子查询、关联查询
mysql中update.delete.install尽量不要使用子查询 一.mysql查询的五种子句 where(条件查询).having(筛选).group by(分组).orde ...
- 【sql】关联查询+表自关联查询
表: 经销商 dealer 字段 uid parent_uid name 联系人 contact 字段 uid dealer_id contact_main 需求: 想要查询到经销商的信 ...
随机推荐
- C语言中return 0和return 1和return -1
转载声明:本文系转载文章 原文作者:十一月zz 原文地址:https://blog.csdn.net/baidu_35679960/article/details/77542787 1.返回值int ...
- PHP-高并发和大流量的解决方案
一 高并发的概念在互联网时代,并发,高并发通常是指并发访问.也就是在某个时间点,有多少个访问同时到来. 二 高并发架构相关概念1.QPS (每秒查询率) : 每秒钟请求或者查询的数量,在互联网领域 ...
- rsync问题
问题一: rsync: chgrp "/data/www/vhosts/go/.rest.qXYFW5" (in apache) failed: Operation not per ...
- centos7 firewalld 开放端口
开通80端口 firewall-cmd --zone=public --add-port=80/tcp --permanent --zone #作用域 --add-port=80/tcp #添加端口, ...
- C#嵌入子窗体,判断子窗体是否打开了
/// <summary> /// 嵌入子窗体,判断子窗体是否打开了 /// </summary> public static Form1 f; public void For ...
- 网络安装Centos x64 6.10
1.下载老毛桃PE最新增强版本,然后生成一个可启动U盘. 2.在U盘或移动硬盘中创建一个目录 MYEXT,然后把centos的安装iso放到里面. 3.引导选择从外置ISO进行安装. https:// ...
- Angular动画——路由动画及高阶动画函数
一.路由动画 路由动画需要在host元数据中指定触发器.动画注意不要过多,否则适得其反. 内容优先,引导用户去注意到某个内容.动画只是辅助手段. 定义一个进场动画,一个离场动画. 因为进场动画和离场动 ...
- Angular动画
Angular动画基于W3C的Web Animations标准.不在Angular Core中了. 组件里面定义一个或多个触发器trigger,每个触发器有一系列的状态和过渡效果来实现. 动画其实就是 ...
- 腾讯工蜂Git关联Jenkins Hooks
现在国内外Git平台非常多,最近维护的腾讯工蜂免费公网版本git.code.tencent.com,免注册(建议使用微信登录,舒服)即可使用私有仓库.对小型团队体验还不错,如果要关联Jenkins进行 ...
- 今日头条Marketing API小工具(.Net Core版本)
前言 由于工作原因,需要用到今日头条的Marketing API做一些广告投放的定制化开发.然后看现在网上也没多少关于头条Marketing API的文章,于是便就有了该篇文章. 头条Marketin ...