#Week2 Linear Regression with One Variable
一、Model Representation
还是以房价预测为例,一图胜千言:

h表示一个从x到y的函数映射。
二、Cost Function
因为是单变量线性回归,所以假设函数是:
\]
所以接下来的问题是怎样确定参数\(\theta_0\)和\(\theta_1\)?
这两个参数会决定我们的模型预测值与训练集的实际数据的差距,这就是建模误差。
那么在回归问题中,代价函数选择如下的平方误差函数比较合理:
\]
m是训练集的样本数目,\(x^{(i)}\)是每个房子的尺寸,\(y^{(i)}\)是实际价格。
只要寻找使得\(J(\theta_0,\theta_1)\)最小的参数即可。
之所以要除以2,主要是为了后续的梯度下降法求导时抵消平方的那个2。
三、Gradient Descent
为了求得代价函数的最小值,采用梯度下降法。
- 用一个随机的参数组合计算\(J\)
- 找到一个使得\(J\)下降最多的参数组合,更新参数,直到找到一个局部最优解
就像下山一样,每次都走一步,每次选择下降最快的方向直到局部最低。
在批量梯度下降算法(所有的训练样本都要用到)中,同步更新所有参数:

\(\alpha\)是学习率,表示每一步走多长。
如果\(\alpha\)太小,那么更新的过程就会很缓慢;如果\(\alpha\)太大,可能跳过最低点,导致发散。
当接近局部最优时,由于斜率会越来越小,所以每一步会自动走得很小,不需要减小学习率\(\alpha\)。
四、Gradient Descent For Linear Regression
对之前得回归模型应用梯度下降算法:
对\(J(\theta_0,\theta_1)\)求关于\(\theta_0\)、\(\theta_1\)的偏导数,带入参数更新公式,有:
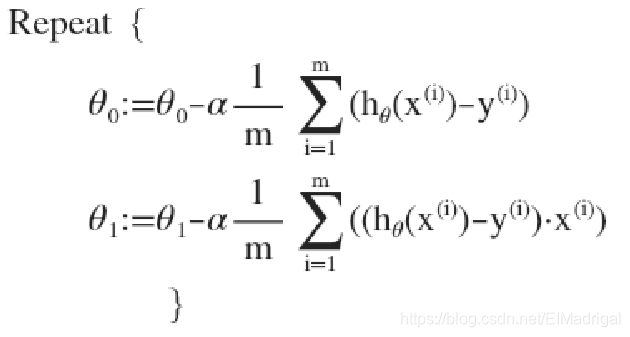
#Week2 Linear Regression with One Variable的更多相关文章
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Stanford机器学习---第一讲. Linear Regression with one variable
原文:http://blog.csdn.net/abcjennifer/article/details/7691571 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 机器学习笔记1——Linear Regression with One Variable
Linear Regression with One Variable Model Representation Recall that in *regression problems*, we ar ...
- Machine Learning 学习笔记2 - linear regression with one variable(单变量线性回归)
一.Model representation(模型表示) 1.1 训练集 由训练样例(training example)组成的集合就是训练集(training set), 如下图所示, 其中(x,y) ...
- Ng第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 2.4 梯度下降 2.5 梯度下 ...
- 【cs229-Lecture2】Linear Regression with One Variable (Week 1)(含测试数据和源码)
从Ⅱ到Ⅳ都在讲的是线性回归,其中第Ⅱ章讲得是简单线性回归(simple linear regression, SLR)(单变量),第Ⅲ章讲的是线代基础,第Ⅳ章讲的是多元回归(大于一个自变量). 本文的 ...
- MachineLearning ---- lesson 2 Linear Regression with One Variable
Linear Regression with One Variable model Representation 以上篇博文中的房价预测为例,从图中依次来看,m表示训练集的大小,此处即房价样本数量:x ...
- 斯坦福第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 I 2.4 代价函数的直观理解 I ...
- 机器学习 (一) 单变量线性回归 Linear Regression with One Variable
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang的个人笔 ...
随机推荐
- Spring (五):AOP
本文是按照狂神说的教学视频学习的笔记,强力推荐,教学深入浅出一遍就懂!b站搜索狂神说或点击下面链接 https://space.bilibili.com/95256449?spm_id_from=33 ...
- js实现表单的隔行换色、鼠标高亮出来等相关内容以及相关事件的作用
主要是使用的onload().onmouseover和onmouseout的相关应用,满足此次的相关操作. 具体的相关的两个代码如下: <!DOCTYPE html> <html&g ...
- docker 服务器安装harbor
一.Harbor是什么? 二.环境搭建 2.1在linux centos搭建服务 2.2docker安装 yum安装 yum install docker 卸载 :pip uninstall dock ...
- Vue+Mock.js模拟登录和表格的增删改查
有三类人不适合此篇文章: "喜欢站在道德制高点的圣母婊" -- 适合去教堂 "无理取闹的键盘侠" -- 国际新闻版块欢迎你去 "有一定基础但又喜欢逼逼 ...
- intelij idea 和 eclipse 使用上的区别
一.项目创建区别 使用基于IntelliJ的IDE,都会对project和module的关系比较糊涂.用简单的一句话来概括是: IntelliJ系中的Project相当于Eclipse系中的works ...
- 【python实现卷积神经网络】卷积层Conv2D反向传播过程
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- Codeup 25609 Problem I 习题5-10 分数序列求和
题目描述 有如下分数序列 2/1,3/2,5/3,8/5,13/8,21/13 - 求出次数列的前20项之和. 请将结果的数据类型定义为double类型. 输入 无 输出 小数点后保留6位小数,末尾输 ...
- undefined 和 not defined
概念上的解释: undefined是javascript语言中定义的五个原始类中的一个,换句话说,undefined并不是程序报错,而是程序允许的一个值. not defined是javascript ...
- L23模型微调fine tuning
resnet185352 链接:https://pan.baidu.com/s/1EZs9XVUjUf1MzaKYbJlcSA 提取码:axd1 9.2 微调 在前面的一些章节中,我们介绍了如何在只有 ...
- stand up meeting for beta release plan 12/16/2015
今天我们开会讨论一下beta版需要的feature,其中待定的feature是可选做的,如果有时间.其他都是必须实现的. 因为做插件的计划失败了,所以我们现在是pdf阅读器和取词查词加入生词本这两部分 ...