centos7搭建hadoop2.10完全分布式
本篇介绍在centos7中大家hadoop2.10完全分布式,首先准备4台机器:1台nn(namenode);3台dn(datanode)
| IP | hostname | 进程 |
| 192.168.30.141 | s141 | nn(namenode) |
| 192.168.30.142 | s142 | dn(datanode) |
| 192.168.30.143 | s143 | dn(datanode) |
| 192.168.30.144 | s144 | dn(datanode) |
由于本人使用的是vmware虚拟机,所以在配置好一台机器后,使用克隆,克隆出剩余机器,并修改hostname和IP,这样每台机器配置就都统一了每台机器配置 添加hdfs用户及用户组,配置jdk环境,安装hadoop 见 :centos7搭建hadoop2.10伪分布模式
下面是安装完全分布式的一些步骤和细节:
1.设置每台机器的hostname 和 hosts
设置hostname,这里用s+ip最后一组数字(如:192.168.30.141为s141),修改一下文件
vim /etc/hostname
修改hosts文件,hosts设置有后可以使用hostname访问机器,这样比较方便,修改如下:
127.0.0.1 locahost
192.168.30.141 s141
192.168.30.142 s142
192.168.30.143 s143
192.168.30.144 s144
2.配置无密登录,即ssh无密登录
我们将s141设置为nn,就需要s141能够通过ssh无密登录到其他机器,这样就需要在s141机器hdfs用户下生成密钥对,并将s141公钥发送到其他机器放到~/.ssh/authorized_keys文件中
在s141机器上生成密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
执行命令后

说明成功了,查看 ~/.ssh下是否生成密钥对:

将id_rsa.pub文件内容追加到s141-s144机器的/home/centos/.ssh/authorized_keys中,现在其他机器暂时没有authorized_keys文件,我们就将id_rsa.pub更名为authorized_keys即可,如果其他机器已存在authorized_keys文件可以将id_rsa.pub内容追加到该文件后,远程复制可以使用scp命令:
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/authorized_keys
scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/authorized_keys
scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/authorized_keys
scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/authorized_keys
s141机器可以使用cat生成authorized_keys文件
cat id_rsa.pub >> authorized_keys
此时authorized_keys文件权限需要改为644(注意,经常会因为这个权限问题导致ssh无密登录失败)
chmod authorized_keys
3.配置hadoop配置文件(${hadoop_home}/etc/hadoop/)
core-sit.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s141/</value>
</property>
</configuration>
hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
mapred-site.xml:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
slaves(指定数据节点):
s142
s143
s144
hadoop-env.sh(配置jdk环境变量):
export JAVA_HOME=/opt/soft/jdk
4.将s141中hadoop配置文件分发大其他机器上,使用scp
scp -r hadoop hdfs@s142:/opt/soft/hadoop/etc/
scp -r hadoop hdfs@s143:/opt/soft/hadoop/etc/
scp -r hadoop hdfs@s144:/opt/soft/hadoop/etc/
5.格式化hdfs
首先删除/tmp/下相关hadoop文件,可以直接清空,删除${hadoop_home}/logs 下日志文件
格式化文件系统
hadoop namenode -format
6.启动hadoop
start-all.sh
7.验证启动是否成功
使用jps查看进程
nn: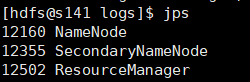
dn: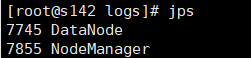
页面访问:http://192.168.30.141:50070
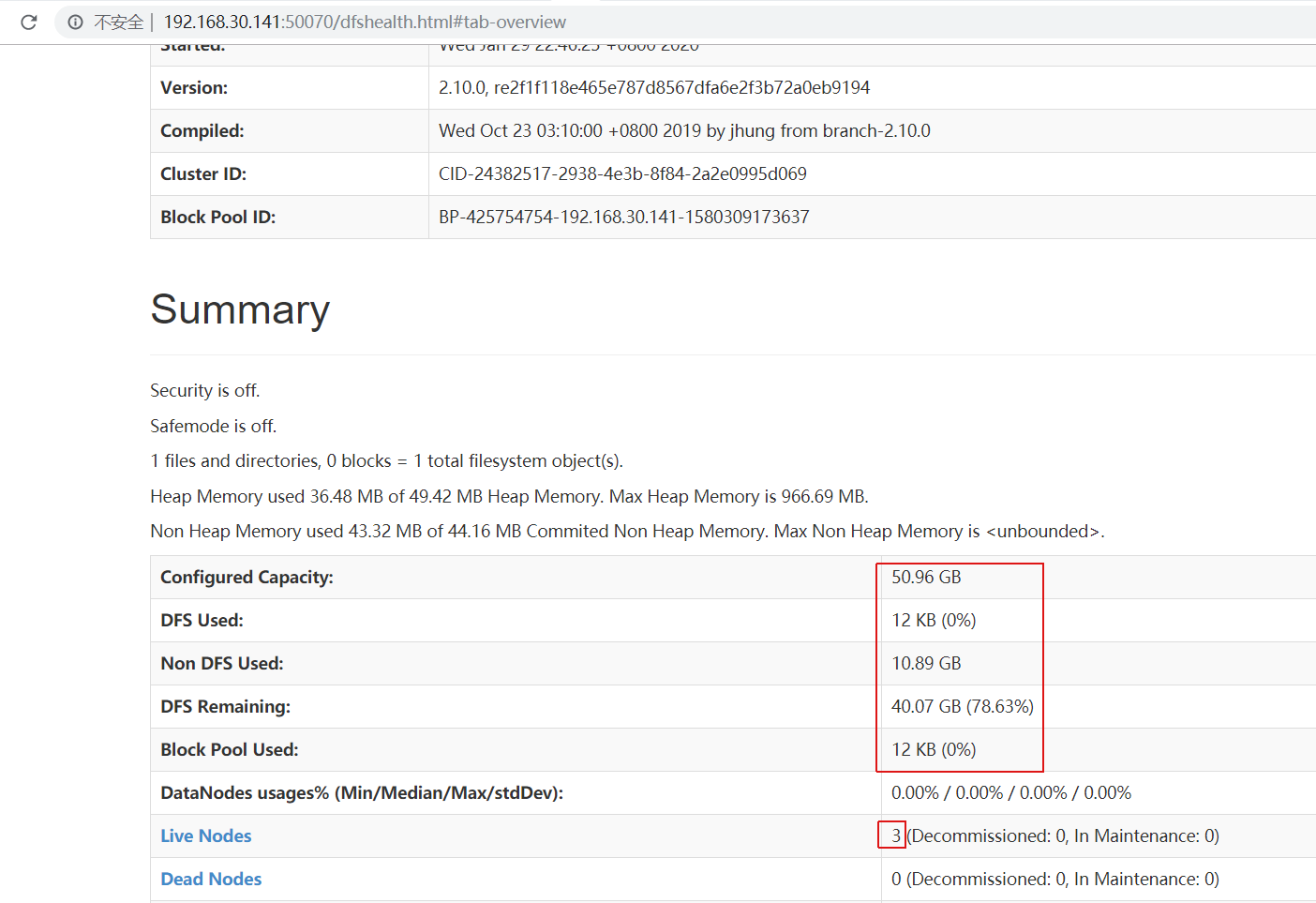
说明启动成功
centos7搭建hadoop2.10完全分布式的更多相关文章
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- centos7搭建hadoop2.10伪分布模式
1.准备一台Vmware虚拟机,添加hdfs用户及用户组,配置网络见 https://www.cnblogs.com/qixing/p/11396835.html 在root用户下 添加hdfs用户, ...
- CentOS7搭建FastDFS V5.11分布式文件系统及Java整合详细过程
1.1 FastDFS的应用场景 FastDFS是为互联网应用量身定做的一套分布式文件存储系统,非常适合用来存储用户图片.视频.文档等文件.对于互联网应用,和其他分布式文件系统相比,优势非常明显.其中 ...
- centos7搭建hadoop-2.7.3,zookeeper-3.4.6,hbase-1.2.5(root用户)
环境:[centos7.hadoop-2.7.3.zookeeper-3.4.6.hbase-1.2.5] 两个节点:[主节点,主机名为Master,用户为root:从节点,主机名为Slave,用户为 ...
- Docker中自动化搭建Hadoop2.6完全分布式集群
这一节将在<Dockerfile完成Hadoop2.6的伪分布式搭建>的基础上搭建一个完全分布式的Hadoop集群. 1. 搭建集群中需要用到的文件 [root@centos-docker ...
- CentOS7搭建Hadoop2.8.0集群及基础操作与测试
环境说明 示例环境 主机名 IP 角色 系统版本 数据目录 Hadoop版本 master 192.168.174.200 nameNode CentOS Linux release 7.4.1708 ...
- CentOS7搭建FastDFS V5.11分布式文件系统-第一篇
1.绪论 最近要用到fastDFS,所以自己研究了一下,在搭建FastDFS的过程中遇到过很多的问题,为了能帮忙到以后搭建FastDFS的同学,少走弯路,与大家分享一下.FastDFS的作者淘宝资深架 ...
- CentOS7搭建FastDFS V5.11分布式文件系统(二)
1.CentOS7 FastDFS搭建 前面已下载好了要用到的工具集,下面就可以开始安装了: 如果安装过程中出现问题,可以下载我提供的,当前测试可以通过的工具包: 点这里点这里 1.1 安装libfa ...
- CentOS7搭建FastDFS V5.11分布式文件系统(一)
1.绪论 最近要用到fastDFS,所以自己研究了一下,在搭建FastDFS的过程中遇到过很多的问题,为了能帮忙到以后搭建FastDFS的同学,少走弯路,与大家分享一下.FastDFS的作者淘宝资深架 ...
随机推荐
- win7安装mysql数据库
1. 软件准备,以64位系统为例如果是32位的下载32位压缩包即可] https://dev.mysql.com/downloads/mysql/ 2.下载解压到本地,将解压路径的bin目录配置到环境 ...
- Bugku-CTF加密篇之affine(y = 17x-8 flag{szzyfimhyzd})
affine y = 17x-8 flag{szzyfimhyzd} 答案格式:flag{*} 来源:第七届山东省大学生网络安全技能大赛
- KM算法模板 hdu 2255
KM算法是在匹配是完备的情况下寻找最优匹配. 首先,先将范围定为最大的情况,如果最大的情况无法满足,就下降一个维度继续匹配. 直到匹配成功. #include<cstdio> #inclu ...
- Spring bean继承
Bean 定义继承 bean 定义可以包含很多的配置信息,包括构造函数的参数,属性值,容器的具体信息例如初始化方法,静态工厂方法名,等等. 子 bean 的定义继承父定义的配置数据.子定义可以根据需要 ...
- 前端——语言——Core JS——《The good part》读书笔记——第五章节(Inheritance)
本章题目是继承,实质上介绍JS如何实现面向对象的三大特性,封装,继承,多态.本章的最后一个小节介绍事件. 与Java语言对比,虽然名称同样称为类,对象,但是显然它们的含义存在一些细微的差异,而且实现三 ...
- LOJ#6713. 「EC Final 2019」狄利克雷 k 次根 加强版
题目描述 定义两个函数 \(f, g: \{1, 2, \dots, n\} \rightarrow \mathbb Z\) 的狄利克雷卷积 \(f * g\) 为: \[ (f * g)(n) = ...
- javaScript中的querySelector和querySelectorAll
querySelector和querySelectorAll是W3C提供的 新的查询接口,其主要特点如下: 1.querySelector只返回匹配的第一个元素,如果没有匹配项,返回null. 2.q ...
- P&R --From 陌上风骑驴看IC
FLOORPLAN: 做好floorplan要掌握哪些知识技能 遇到floorplan问题,大致的debug步骤和方法有哪些 如何衡量floorplan的QA 以上是驴神提的五大点问题.鄙人狠狠地反驳 ...
- 新手学习arm的建议
本文来自:chen4013874的博客 如果您是ARM初学者或者以前是51单片机应用开发工程师,想快速进入32位ARM嵌入式开发领域,建议您阅读本文档.本文档是我们结合多年ARM开发经验,针对初学者对 ...
- 【PAT甲级】1076 Forwards on Weibo (30 分)
题意: 输入两个正整数N和L(N<=1000,L<=6),接着输入N行数据每行包括它关注人数(<=100)和关注的人的序号,接着输入一行包含一个正整数K和K个序号.输出每次询问的人发 ...