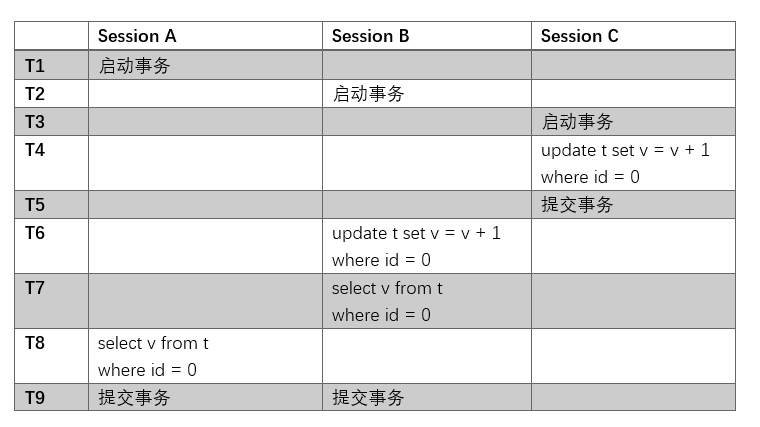
MySQL 入门(3):事务隔离
摘要
在这一篇内容中,我将从事务是什么开始,聊一聊事务的必要性。
然后,介绍一下在InnoDB中,四种不同级别的事务隔离,能解决什么问题,以及会带来什么问题。
最后,我会介绍一下InnoDB解决高并发事务的方式:多版本并发控制。
1 什么是事务
说到事务,一个最典型的例子就是银行转账:假设A和B的余额都是100元,此时A要向B转账50元。那么我们的操作流程是这样的:
- 查询A的余额,保存在
balance中,并判断balance是否大于50元 - 如果是,则
balance减去50元,写回数据库,然后给B的余额加上50元,写回数据库 - 如果不是,返回余额不足
那么问题来了,在第一步查询之后,如果我们马上再进行一次转账,而此时A的余额还是原来的100元,大于50,系统判断余额是充足的,转账成功。但是在写回数据库的时候,A的余额还是50元,而B的余额变成了200元。
相信你也看出来了,问题的核心在于这个流程被人“横插了一脚”,没有安安静静不被打扰的执行完这个转账的流程。
正因为我们希望我们的业务逻辑可以不被打扰,所以我们有了“事务”。
那么,事务需要什么样的条件呢?
相信你也或多或少的听过了ACID这一说法。
1.原子性(Atomicity):在通常的语义下,原子性指的是一条语句不可分割。但是在事务中,指的是组成这条事务的所有语句必须要执行完,或者回滚。
2.一致性(Consistency):这里的一致性和我们说的数据一致性,也有些不太一样。我们说的数据一致性,一般指的是MySQL和Redis中的数据是一致的,又或者是MySQL主库和从库中的数据是一致的。但是在这儿通常指的是事务是否产生了非预期的中间状态或结果。比如上面银行转账的例子,转账之前两个人的余额总数是200元,而转账完变成了250元。这就是不符合一致性的。
3.隔离性(Isolation):顾名思义,隔离性指的是事务之间应该是互不影响的。在MySQL里面,事务的隔离被分成了四个级别,我们在后面会详细介绍。
4.持久性(Duration):这个很容易理解,如果一个事务提交了,数据必须得被保存,而不能丢失。
2 事务的隔离级别
事务的隔离级别从低到高,分为了读未提交,读已提交,可重复读,串行化。
而每个级别的隔离,可能造成的问题有:脏读,不可重复读,幻读。
下面我们来举例说明,假设我们有一张只有两个字段的表,然后插入以下数据:
CREATE TABLE `t`(
id int,
v int,
PRIMARY KEY (`id`)
)ENGINE=InnoDB;
insert into t(id, v) values(0, 0)
注意,以下的内容全都是基于只有一行数据(0, 0)的表t。
2.1 读未提交
此时事务的隔离级别为读未提交:
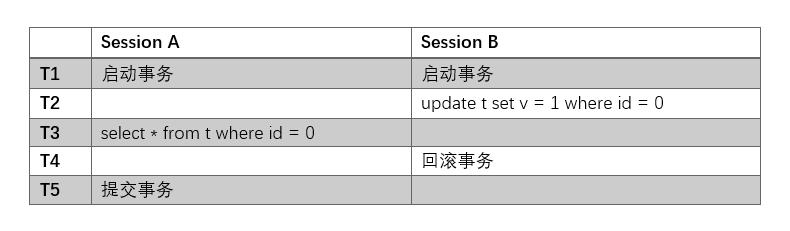
在图中可以看出:在T3时刻,事务A查找到的数据是(0, 1),但是后来事务B回滚了,也就造成了(0, 1)这行数据是错误的,这被称为是脏读。
问题的根源在于,事务A读到了事务B未提交的数据,这也是事务隔离级别读未提交所存在的问题。这样的事务隔离级别,仅仅能够保证事务的原子性,但是没有保证事务的隔离性,是最低级别的事务隔离级别。
2.2 读已提交
知道了上面的问题是因为事务读取了尚未提交的数据,那么我们让事务的隔离级别变成读已提交,也就是说,此时只能读取已经提交过的事务。那么这样做的话,我们来看看会有什么问题:
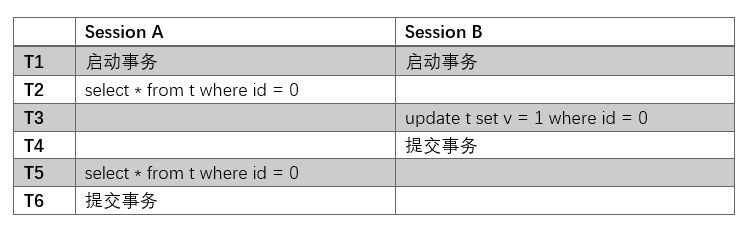
我们知道,在读已提交这个隔离级别中,只能查找到已经提交的数据。那么在T5时刻,事务B已经提交了,那么他的更改对于事务A是可见的。
也就是说,在T5时刻,事务A查找到的数据是(0, 1)。但是问题来了,在T2时刻事务A查找到的数据是(0,0)。这种在同一个事务中,查找同样的一行数据,却得到了不同的结果,称为“不可重复读”。
在读已提交这个事务隔离级别中,问题在于没能保证在同一个事务中查询结果是不变的。
2.3 可重复读
既然在上面我们发现了不能够在一个事务中保持结果不变的这么一个问题,那么我们让MySQL在事务启动的那一瞬间,将所有的数据拷贝成一个快照,然后让这个事务所有的查找都在这个快照上进行。这样的话,在同一个事务中,所有的查询都是一致的。
这样的事务隔离级别,称为“可重复读”。
注意,这里的“把所有数据拷贝成一个快照”的说法是不准确的,因为这样做的话,每启动一个事务,所需要的存储空间就得增加一倍,显然是不可能的。但是你可以先这么理解,在后面的内容我会跟你解释MySQL是如何做到“快照”这一功能的。
那么,在“可重复读”这一隔离级别中,又可能会出现什么样的问题呢?
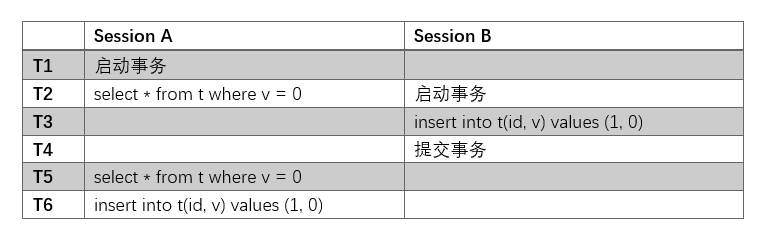
在T2时刻,事务A得到的结果是这样的:
| id | v |
|---|---|
| 0 | 0 |
值得注意的是,我们在T3时刻,在事务B中也插入了一行v为0的数据,但是因为我们使用的是可重复读这一隔离级别,所以可以推断,在T5时刻的查找,并不会找到新插入的这一行数据。
也就是说,在T5时刻,查询结果还是和T2时刻是一样的:
| id | v |
|---|---|
| 0 | 0 |
但是,问题来了。因为此时事务A是不知道事务B的存在的,当事务A发现不存在id为1,v为0的数据之后,事务A准备插入这一行数据,MySQL会返回这样的错误:
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
这个报错的意思是,主键重复了。然后事务A就很迷惑:明明我查到并不存在这一行数据,但是为什么我就是无法插入呢?
这就是幻读。
原因和解决办法我会下一篇文章中提到,我们先继续看看最严格的事务隔离级别。
2.4 串行化
串行化,顾名思义,就是事务必须得串行执行。
说得再详细一点:所有包含写操作的事务,必须得串行执行。
和其他的隔离级别不同,在串行化中,读操作都会被加上共享锁,并遵循严格两阶段加锁协议。
在串行化中,因为事务是按顺序执行的,所以不可能会出现上面提到的那些问题。但是问题在于,当事务串行化之后,MySQL不能再并发处理事务了,此时性能极低。
关于锁的内容,我将在下一篇提到。
3 多版本并发控制
在2.3 可重复读内容中,我提到了“快照”这一说法。
不过说的不够准确,因为MySQL确实不可能在事务启动的一瞬间将所有的数据都备份一遍。
在这里,我准备介绍一下InnoDB的多版本并发控制(Multi-Version Concurrency Control),简称MVCC。
首先明确两个概念:
首先,每一个事务在启动的时候都被分配了一个id,这个id由InnoDB分配,是递增的。
其次,InnoDB会向数据库中的每一行都添加三个字段,DB_TRX_ID表示插入或者更新这一行的事务id;DB_ROLL_PTR是一个指针,指向了undo log中的旧版本数据;DB_ROW_ID是一个递增的行id。
我们先来看这张图:
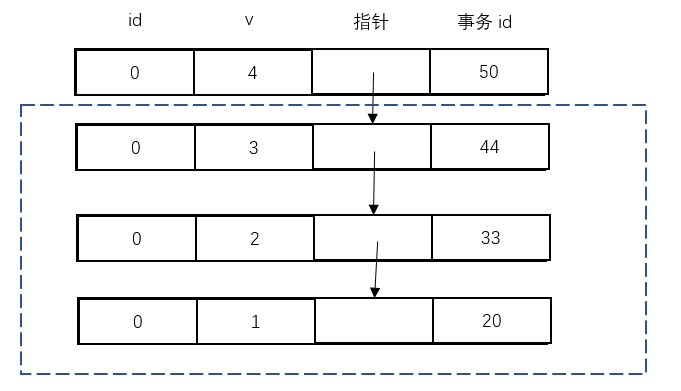
还是上面提到的表t,他有两个字段,id和v。然后加上了InnoDB自动添加的指针字段和事务id字段,省略了行id字段。
在最上面的虚线方框外的那行数据,代表了最新的id为0的数据,此时的v为4,这行数据是由id为50的事务更改的。
往下看,在这个最新的数据中,指针指向了id为0,v为3的一行数据,而这行数据是由id为44的事务更改的。
说到这里你可能已经明白了,InnoDB每次更新数据,都会把更新这行数据所在的事务的id记录在事务id字段中,然后把原数据的内存地址填入指针字段。也就是说,InnoDB可以根据这里的指针地址,找到这一行数据的修改历史记录以及产生这条记录的事务id。
那么这跟我们说的“快照”,有什么关系呢?
假设现在是“可重复读”的事务隔离级别,那么在事务启动的时候,InnoDB内部会生成一个数组,数组里面记录了所有当前活跃(也就是说还在执行没有提交)的事务id,并进行排序。
那么在当前事务执行查找语句的时候,找到的每一行数据都会进行如下的判断:
- 如果这行数据的事务id小于数组中的最小值,那么表示这行数据已经在事务启动之前更新完毕,可以直接返回
- 如果这行数据的事务id大于数组中的最大值,那么说明这行数据是在当前事务之后启动并修改的,那么这行数据不可见,需要使用指针找上一条数据,直到符合条件返回
- 如果这行数据的事务id位于数组中的最大最小值中间,那么还需要判断这行数据的事务id是否在数组中,如果在,代表了这个事务还是活跃的,应该使用指针找上一条数据;否则的话,说明这个事务已经提交了,可以直接返回数据
我们来看一个例子:
假设在此之前,表t已经有了这么一行数据,id=0,v=1,是由id为100的事务插入的。
然后假设事务A的id是101,事务B是102,事务C是103。
到了T4时刻,事务C更新了这行数据,数据的历史版本如下:
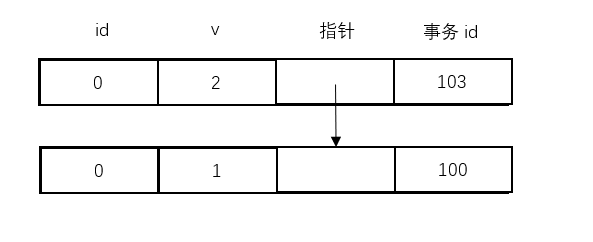
然后到了T6时刻,事务B准备更新这行数据。注意,更新的时候,是不管数据的历史版本的,一定要更新最新的那行数据。这被称为是“当前读”,意思是InnoDB的更新、插入、删除操作,是与快照无关的,必须得更新最新的数据。关于这一部分的内容,在下一节会继续展开介绍。
于是,变成了这样:

然后到了T7时刻,准备读取数据。
在事务B启动的时候,事务C还没有启动,所以数组为[101, 102],而读取到的数据版本是102,就是事务B自己做的更新,所以这行数据符合要求,返回。
到了T8时刻,事务A准备读取数据。因为事务A启动的时候,数组为[101],而当前的数据事务id是102,大于100,不符合要求,所以要查找上一个数据。
但是上一个数据的id是103,也大于101,所以也不符合要求,查找上一行的数据。
最终,找到了事务id为100的这行数据,返回。
简单的来讲就是:
- 未提交的不可见
- 当前事务启动之后提交的,不可见
- 当前事务修改的,可见
- 当前事务启动之前提交的,可见
上面的分析过程是基于“可重复读”,也就是说,视图是在事务启动的一瞬间创建的。其实“读已提交”也是一样的意思,只不过一致性视图不是在事务启动的一瞬间创建的,而是在每一条select语句(也被称为一致性读)之前创建的。
还需要补充的是,数据的历史版本,都被保存在了undo log中,并且InnoDB会判断当不需要这些旧版本数据的时候,会清理以释放空间。
此外,所有对undo log的更新,都会被保存在redo log中。
写在最后
首先,谢谢你能看到这里!
这篇文章鸽了比较久,不好意思,最近事儿实在是太多了。
本来这篇文章打算写《事务隔离和锁》的,但是写着写着发现内容太多了一些,就打算这篇先把事务隔离相关的内容写完,下一篇再写锁相关的。
如果在这篇文章中有什么是我理解有误的,或者是我讲的不够清晰的,欢迎一起交流学习!
下一篇很快送上,这次一定不鸽(笑)
PS:如果有其他的问题,也可以在公众号找到作者。并且,所有文章第一时间会在公众号更新,欢迎来找作者玩~

MySQL 入门(3):事务隔离的更多相关文章
- mysql中不同事务隔离级别下数据的显示效果--转载
事务是一组原子性的SQL查询语句,也可以被看做一个工作单元.如果数据库引擎能够成功地对数据库应用所有的查询语句,它就会执行所有查询,如果任何一条查询语句因为崩溃或其他原因而无法执行,那么所有的语句就都 ...
- 浅谈mysql中不同事务隔离级别下数据的显示效果
事务的概念 事 务是一组原子性的SQL查询语句,也可以被看做一个工作单元.如果数据库引擎能够成功地对数据库应用所有的查询语句,它就会执行所有查询,如果任何一条查 询语句因为崩溃或其他原因而无法执行,那 ...
- 事务,Oracle,MySQL及Spring事务隔离级别
一.什么是事务: 事务逻辑上的一组操作,组成这组操作的各个逻辑单元,要么一起成功,要么一起失败. 二.事务特性(4种): 原子性 (atomicity):强调事务的不可分割:一致性 (consiste ...
- 谈谈MySQL支持的事务隔离级别,以及悲观锁和乐观锁的原理和应用场景?
在日常开发中,尤其是业务开发,少不了利用 Java 对数据库进行基本的增删改查等数据操作,这也是 Java 工程师的必备技能之一.做好数据操作,不仅仅需要对 Java 语言相关框架的掌握,更需要对各种 ...
- MySQL事物(一)事务隔离级别和事物并发冲突
数据库的操作通常为写和读,就是所说的CRUD:增加(Create).读取(Read).更新(Update)和删除(Delete).事务就是一件完整要做的事情.事务是恢复和并发控制的基本单位.事务必须始 ...
- MySQL四种事务隔离级别详解
本文实验的测试环境:Windows 10+cmd+MySQL5.6.36+InnoDB 一.事务的基本要素(ACID) 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做 ...
- 在MySQL中设置事务隔离级别有2种方法:
在MySQL中设置事务隔离级别有2种方法: 1 在my.cnf中设置,在mysqld选项中如下设置 [mysqld] transaction-isolation = READ-COMMITTED 2 ...
- 面试必问的MySQL锁与事务隔离级别
之前多篇文章从mysql的底层结构分析.sql语句的分析器以及sql从优化底层分析, 还有工作中常用的sql优化小知识点.面试各大互联网公司必问的mysql锁和事务隔离级别,这篇文章给你打神助攻,一飞 ...
- MySql锁和事务隔离级别
在讲mysql事物隔离级别之前,我们先简单说说mysql的锁和事务. 一:数据库锁 因为数据库要解决并发控制问题.在同一时刻,可能会有多个客户端对同一张表进行操作,比如有的在读取该行数据,其他的尝试去 ...
- 第36讲 谈谈MySQL支持的事务隔离级别,以及悲观锁和乐观锁的原理和应用场景
在日常开发中,尤其是业务开发,少不了利用 Java 对数据库进行基本的增删改查等数据操作,这也是 Java 工程师的必备技能之一.做好数据操作,不仅仅需要对 Java 语言相关框架的掌握,更需要对各种 ...
随机推荐
- EFCore.Sharding(EFCore开源分表框架)
EFCore.Sharding(EFCore开源分表框架) 简介 引言 开始 准备 配置 使用 按时间自动分表 性能测试 其它简单操作(非Sharing) 总结 简介 本框架旨在为EF Core提供S ...
- Crowd 批量添加用户(Postman 数据驱动)
背景 最近公司大量新员工入职,需要批量创建 Crowd 用户.设置密码.分配应用组等机械性重复工作(主要还是懒~),故把这个加餐任务分配给刚来的测试同学去研究. 一是:让他了解下 Postman 的数 ...
- Salesforce 开发 | Salesforce与微信集成实操指南
配置前须知 Salesforce通过试点对特定客户提供Lightning WeChat Messaging,该试点需要同意特定的条款.除非Salesforce宣布WeChat Messaging全面可 ...
- 干货:python面对对象类继承简介
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:python视觉算法 PS:如有需要Python学习资料的小伙伴可以加 ...
- Daily Scrum 1/12/2016
Zhaoyang & Yandong: Optimize the speech input interface Fuchen: Code refactor in the NLP module ...
- 图数据库的内部结构 (NEO4j)
What “Graph First” Means for Native Graph Technology Neo4j是一个具有原生处理(native processing)功能和原生图存储(nativ ...
- STM32 i2c通讯失败复位方法
最近在调研STM32 F10X,准备把公司AVR的MCU项目迁移到STM32上.在调研STM32 i2c这一部分时,在与i2c slave硬件连接断开后,这时再去读/写 i2c slave需要STM3 ...
- 初学者的Pygame安装教程
最近在自学python,在看完了些基础知识之后,准备写个小项目[外星人入侵],这个项目需要安装pygame. 所以就在网上找到了两个下载地址https://bitbucket.org/pygame/p ...
- Java同步方法:synchronized到底锁住了谁?
目录 前言 同步方法 类的成员方法 类的静态方法 同步代码块 总结 其他同步方法 参考资料 前言 相信不少同学在上完Java课后,对于线程同步部分的实战,都会感到不知其然. 比如上课做实验的时候,按着 ...
- udp包最大数据长度是多少
因为udp包头有2个byte用于记录包体长度. 2个byte可表示最大值为: 2^16-1=64K-1=65535 udp包头占8字节, ip包头占20字节, 65535-28 = 65507 ...