卷积涨点论文 | Asymmetric Convolution ACNet | ICCV | 2019
文章原创来自作者的微信公众号:【机器学习炼丹术】。交流群氛围超好,我希望可以建议一个:当一个人遇到问题的时候,有这样一个平台可以快速讨论并解答,目前已经1群已经满员啦,2群欢迎你的到来哦。加入群唯一的要求就是,你对AI有兴趣。加我的微信我邀请进群cyx645016617。
- 论文名称:“ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks”
- 论文链接:https://arxiv.org/abs/1908.03930
- 模型缩写:ACNet
0 我的理解
这个ACNet是一个不错的对于卷积核结构的一个创新。总的来说是一个值得在CNN模型中尝试的trick,至于有没有效果还得看缘分。不过这个trick的听同行来说,算是一个好的trick,所以值得尝试。
这个trick的代价是增加了训练阶段的时间和参数,但是并不会增加推理阶段的时长,也不会增加最终模型的参数。
1 论文讲解
这个方法挺简单了,可以用这一张图来展示:
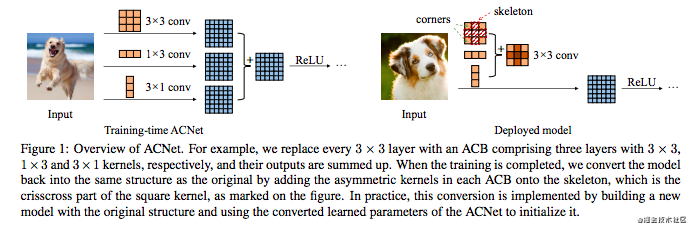
炼丹兄带你理解这图:
- 图片分为左右两个部分,左边是训练阶段的ACNet,右边是部署的模型,可以理解为测试推理阶段;
- 一般3x3的卷积,其实就是左图中第一行的那个卷积,ACNet的创新在于3x3的卷积的侧面并行了1x3和3x1两个矩形卷积核的卷积。可以理解为,任何一个卷积网络中,本来的一个3x3的卷积层,假如使用ACNet的方法,就会变成3哥卷积层并行的一个结构。
- 三个卷积层的输出结构相加,就是这个这个AC卷积层的输出特征图了
- 为什么说,测试阶段模型的参数没有增加呢?这不是多了两个卷积层,那参数怎么会不增加呢?从右边的图可以看到,这三个卷积核其实可以合并成一个卷积核,所以其实acnet是完全等价于一般的卷积模型的。
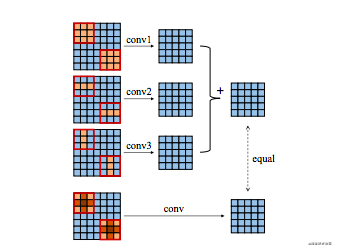
个人的理解,一般的模型也是有可能训练出ACNet的效果的,因为两者的参数完全等价。但是ACNet可能是因为强化了横向和纵向的特征,所以会取得更好的效果。并且这个相当于,给卷积核增加了一层限制,卷积核的每一个参数不再是同等中重要的,中心更为重要。因为增加了限制,可能也会避免过拟合。这是个人从实验中得到的一些猜想和思考。
下面看一下另外一篇文章的解释,看得懂的朋友可以验证自己理解的是否正确:

2 训练代码
我先写一个用一般卷积的非常简单的分类网络:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(p = 0.5),
nn.Linear(64 * 7 * 7, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(p = 0.5),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(p = 0.5),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
下面我来把这个网络转成使用ACNet的结构,先构建一个acblock来代替卷积:
class ACConv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=3,stride=1,padding=1,bias=True):
super(ACConv2d,self).__init__()
self.conv = nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,padding=padding,bias=True)
self.ac1 = nn.Conv2d(in_channels,out_channels,kernel_size=(1,kernel_size),
stride=stride,padding=(0,padding),bias=True)
self.ac2 = nn.Conv2d(in_channels,out_channels,kernel_size=(kernel_size,1),
stride=stride,padding=(padding,0),bias=True)
def forward(self,x):
ac1 = self.ac1(x)
ac2 = self.ac2(x)
x = self.conv(x)
return (ac1+ac2+x)/3
然后把网路中的nn.Conv2d替换成ACConv2d即可:
class ACNet(nn.Module):
def __init__(self):
super(ACNet, self).__init__()
self.features = nn.Sequential(
ACConv2d(1, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
ACConv2d(32, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
ACConv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
ACConv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(p = 0.5),
nn.Linear(64 * 7 * 7, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(p = 0.5),
nn.Linear(512, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(p = 0.5),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
3 效果及原因

效果上看,模型在ImageNet上是有一定的效果的。为什么会有这样的提升呢?论文中给出了一种解释,因为1x3和3x1的卷积核对于竖直翻转和水平翻转是有鲁棒性的。看下图:
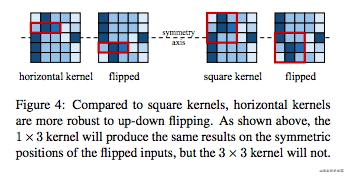
特征图竖直翻转之后,对于1x3的卷积核的特征并没有影响,但是3x3的卷积核中的特征已经发生改变。同理,3x1的卷积核对于水平翻转也有鲁棒性。
这个翻转鲁棒性是一种解释,下面还有另外一种解释:
这部分的原因个人理解是来自梯度差异化,原来只有一个[公式]卷积层,梯度可以看出一份,而添加了1x3和3x1卷积层后,部分位置的梯度变为2份和3份,也是更加细化了。而且理论上可以融合无数个卷积层不断逼近现有网络的效果极限,融合方式不限于相加(训练和推理阶段一致即可),融合的卷积层也不限于1x3或3x1尺寸。
我把这个方法用在我MNIST数据集的识别上,不过没有什么效果哈哈。希望将来可以我的项目有提升效果,是一个值得尝试的trick,欢迎大家收藏点赞。
4 改进
最后,如果你耐心看到这里,并且对之前的内容加以思考,就会发现,我写的ac卷积,并没有实现在推理过程的卷积核融合。我后来完善了一下代码,当调用model.eval()后,acconv卷积就会融合成一个卷积层,而不是3个并行的卷积层:
class ACConv2d(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=3,stride=1,padding=1,bias=False):
super(ACConv2d,self).__init__()
self.bias = bias
self.conv = nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,padding=padding,bias=bias)
self.ac1 = nn.Conv2d(in_channels,out_channels,kernel_size=(1,kernel_size),
stride=stride,padding=(0,padding),bias=bias)
self.ac2 = nn.Conv2d(in_channels,out_channels,kernel_size=(kernel_size,1),
stride=stride,padding=(padding,0),bias=bias)
self.fusedconv = nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,padding=padding,bias=bias)
def forward(self,x):
if self.training:
ac1 = self.ac1(x)
ac2 = self.ac2(x)
x = self.conv(x)
return (ac1+ac2+x)/3
else:
x = self.fusedconv(x)
return x
def train(self,mode=True):
super().train(mode=mode)
if mode is False:
weight = self.conv.weight.cpu().detach().numpy()
weight[:,:,1:2,:] = weight[:,:,1:2,:] + self.ac1.weight.cpu().detach().numpy()
weight[:,:,:,1:2] = weight[:,:,:,1:2] + self.ac2.weight.cpu().detach().numpy()
self.fusedconv.weight = torch.nn.Parameter(torch.FloatTensor(weight/3))
if self.bias:
bias = self.conv.bias.cpu().detach().numpy()+self.conv.ac1.cpu().detach().numpy()+self.conv.ac2.cpu().detach().numpy()
self.fusedconv.bias = torch.nn.Parameter(torch.FloatTensor(bias/3))
if torch.cuda.is_available():
self.fusedconv = self.fusedconv.cuda()
感谢各位的阅读,喜欢的可以点个“赞”和“在看”!
参考文章:
- https://arxiv.org/pdf/1908.03930.pdf
- https://zhuanlan.zhihu.com/p/131282789
- https://blog.csdn.net/u014380165/article/details/103916114
- https://arxiv.org/abs/1908.03930
卷积涨点论文 | Asymmetric Convolution ACNet | ICCV | 2019的更多相关文章
- 深度可分离卷积结构(depthwise separable convolution)计算复杂度分析
https://zhuanlan.zhihu.com/p/28186857 这个例子说明了什么叫做空间可分离卷积,这种方法并不应用在深度学习中,只是用来帮你理解这种结构. 在神经网络中,我们通常会使用 ...
- ICCV 2019|70 篇论文抢先读,含目标检测/自动驾驶/GCN/等(提供PDF下载)
虽然ICCV2019已经公布了接收ID名单,但是具体的论文都还没放出来,为了让大家更快得看论文,我们汇总了目前已经公布的大部分ICCV2019 论文,并组织了ICCV2019论文汇总开源项目(http ...
- 轻量化卷积神经网络MobileNet论文详解(V1&V2)
本文是 Google 团队在 MobileNet 基础上提出的 MobileNetV2,其同样是一个轻量化卷积神经网络.目标主要是在提升现有算法的精度的同时也提升速度,以便加速深度网络在移动端的应用.
- ThunderNet :像闪电一样,旷视再出超轻量级检测器,高达267fps | ICCV 2019
论文提出了实时的超轻量级two-stage detector ThunderNet,靠着精心设计的主干网络以及提高特征表达能力的CEM和SAM模块,使用很少的计算量就能超越目前的one-stage d ...
- FCOS : 找到诀窍了,anchor-free的one-stage目标检测算法也可以很准 | ICCV 2019
论文提出anchor-free和proposal-free的one-stage的目标检测算法FCOS,不再需要anchor相关的的超参数,在目前流行的逐像素(per-pixel)预测方法上进行目标检测 ...
- YOLACT : 首个实时one-stage实例分割模型,29.8mAP/33.5fps | ICCV 2019
论文巧妙地基于one-stage目标检测算法提出实时实例分割算法YOLACT,整体的架构设计十分轻量,在速度和效果上面达到很好的trade-off. 来源:[晓飞的算法工程笔记] 公众号 论文: ...
- 实用,小物体检测的有监督特征级超分辨方法 | ICCV 2019
论文提出新的特征级超分辨方法用于提升检测网络的小物体检测性能,该方法适用于带ROI池化的目标检测算法.在VOC和COCO上的小物体检测最大有5~6%mAP提升,在Tsinghua-Tencent 10 ...
- [ICCV 2019] Weakly Supervised Object Detection With Segmentation Collaboration
新在ICCV上发的弱监督物体检测文章,偷偷高兴一下,贴出我的poster,最近有点忙,话不多说,欢迎交流- https://arxiv.org/pdf/1904.00551.pdf http://op ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
随机推荐
- phpstorm中去除sql的背景颜色
链接 http://www.oschina.net/question/1779564_2143393 这是去除黄线 再去除灰色线
- 【CF607B】Zuma——区间dp(记忆化搜索/递推)
以下是从中文翻译成人话的题面: 给定一个长度小于等于500的序列,每个数字代表一个颜色,每次可以消掉一个回文串,问最多消几次可以消完? (7.16) 这个题从洛谷pend回来以后显示有103个测试点( ...
- Java基础教程——运算符
运算符 算术运算符 加 减 乘 除 取余 自加 自减 + - * / % ++ -- public class 算术运算符 { public static void main(String[] arg ...
- Qt5字符串编码转换学习
目录 1.通过Python3示例探索常用字符串编码 UTF8 ANSI Unicode 小结 2.Qt5中使用QTextCodec进行编码转换 小结 1.通过Python3示例探索常用字符串编码 下面 ...
- Network-Emulator-Toolkit 模拟各种网络环境 windows
背景.目标.目的 (1) 背景: 我们在使用网络时,时常遇到在正常网络环境下的代码运行一切正常,可以复杂的网络环境下的各种问题无法复现,必须搭建模拟各种网络环境,去复现问题,定位问题.不管是移动平台, ...
- tomcat安装及环境变量配置
java环境的配置应该都学过吧,这里简单的讲一下. 下载安装java JDK,注意安装的路径,我们需要进行环境变量的配置. 2 安装完成以后,配置环境变量 环境变量的配置这里就以win7为例:右击计算 ...
- 「刷题笔记」LCA问题相关
板子 ll lg[40]; ll dep[N],fa[N][40]; ll dis[N]; void dfs(ll u,ll f) { dep[u]=dep[f]+1; fa[u][0]=f; for ...
- flask:蓝图--blueprint
一.蓝图 1.什么是蓝图?(WHAT) 1)蓝图就是模块化处理的类 2)用于实现单个应用的视图.模板.静态文件的集合 总结:蓝图就是一个存储操作路由映射方法的容器,主要用来实现客户端请求和URL相互关 ...
- JDK8日期类入门
关于jdk8的时间类的用法,网上有很多教程教你如何用,比如: System.out.println(LocalDateTime.now()); 可以获取当前的时间, 2020-12-06T18:02: ...
- dart时间处理的几个方法
一.时间处理的方法 1.获取当前时间 new DateTime.now(); 2.设置时间 new DateTime(2020, 11, 11, 12, 37 , 36); 3.解析时间 DateTi ...