DM的SQL优化入门笔记
1.查看执行计划
EXPLAIN SELECT A.C1+1,B.D2 FROM T1 A, T2 B WHERE A.C1 = B.D1;
2.执行计划:
1 #NSET2: [0, 16, 9]
2 #PRJT2: [0, 16, 9]; EXP_NUM(2), IS_ATOM(FALSE)
3 #NEST LOOP INDEX JOIN2: [0, 16, 9]
4 #CSCN2: [0, 4, 5]; INDEX33555535(B)
5 #SSEK2: [0, 4, 0]; SCAN_TYPE(ASC), IDX_T1_C1 (A), SCAN_RANGE[T2.D1,T2.D1]
3.该计划的大致执行流程如下:
1) CSCN2: 扫描 T2 表的聚集索引,数据传递给父节点索引连接;
2) NEST LOOP INDEX JOIN2: 当左孩子有数据返回时取右侧数据;
3) SSEK2: 利用 T2 表当前的 D1 值作为二级索引 IDX_T1_C1 定位查找的 KEY,返回结果给父节点;
4) NEST LOOP INDEX JOIN2: 如果右孩子有数据则将结果传递给父节点 PRJT2,否则继续取左孩子的下一条记录;
5) PRJT2: 进行表达式计算 C1+1, D2;
6) NSET2: 输出最后结果;
7) 重复过程 1) ~ 4)直至左侧 CSCN2 数据全部取完。
用户如果想了解更多关于操作符的知识,请查看动态视图 V$SQL_NODE_NAME
4.操作符名称、说明
4.1 简图
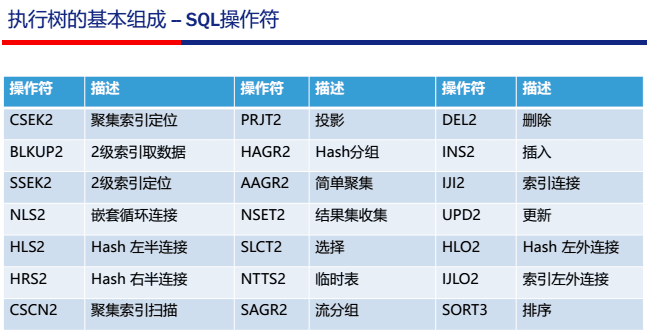
4.2 简图注解
4.2.1 二级索引,一般系统创建主键时生成的索引为主索引,其他为二级索引。
4.2.2 投影,一般SQL语言中的"投影"的含义是指对列的操作, 从表里选择你所要的列 ,就是投影 .比如:Select 姓名,性别 --这里就是对列的选择 ,这个就叫投影From 表
4.2.3 排序,一般都是从上至下判定,asc 时,0,2,5;desc时,5,2,0.
4.3 操作符号详情
AAGR2 简单聚集;如果没有分组(group by), 则总的就一个组,直接计算聚集函数
ACTRL 控制备用计划转换
AFUN 分析函数计算
ASCN 数组当作表来扫描
ASSERT 约束检查
BLKUP2 定位查找
BMAND 位图索引的与运算
BMCNT 位图索引的行数计算
BMCVT 位图索引的 ROWID 转换
BMMG 位图索引归并
BMOR 位图索引的或运算
BMSEK 位图索引的范围查找
CONST VALUE LIST 常量列表
CONSTC 用于复合索引跳跃扫描
CSCN2 聚集索引扫描
CSEK2 聚集索引数据定位
CTNS 用于实现全文索引的 CONTAINS
DELETE 删除数据
DELETE_REMOTE DBLINK 删除操作
DISTINCT 去重
DSCN 动态视图表扫描
DSSEK DISTINCT 列上索引跳跃扫描(单列索引或复合索引)
ESCN 外部表扫描
EXCEPT 集合的差运算,且取差集后删除重复项
EXCEPT ALL 集合的差运算,且取差集后不删除重复项
FAGR2 快速聚集,如果没有 where 条件,且取 count(*), 或者基于索引的 MAX/MIN 值,则可以快速取得集函数的值
FILL BTR 填充 B 树
FTTS MPP\LPQ 下,对临时表的优化
GSEK 空间索引查询
HAGR2 HASH 分组,并计算聚集函数
HASH FULL JOIN2 HASH 全外连接
HASH LEFT JOIN2 HASH 左外连接
HASH LEFT SEMI JOIN2 HASH 左半连接
HASH LEFT SEMI MULTIPLE
JOIN 多列 NOT IN
HASH RIGHT JOIN2 HASH 右外连接
HASH RIGHT SEMI JOIN2 HASH 右半连接
HASH RIGHT SEMI JOIN32 用于 OP SOME/ANY/ALL 的 HASH 右半连接
HASH2 INNER JOIN HASH 内连接
HEAP TABLE 临时结果表
HEAP TABLE SCAN 临时结果表扫描
HFD 删除事务性型 HUGE 表数据
HFDEL2 删除非事务性型 HUGE 表数据
HFDEL_EP MPP 下从 EP 删除非事务性型 HUGE 表数据
HFD_EP MPP 下从 EP 删除事务性型 HUGE 表数据
HFI 事务型 HUGE 表插入记录
HFI2 MPP 下优化的事务型 HUGE 表插入记录
HFINS2 非事务型 HUGE 表插入记录
HFINS3 MPP 下优化的非事务型 HUGE 表插入记录
HFINS4 非 MPP 下, 针对非事务型 HUGE 水平分区主表的插入优化,需要参数 HFINS_PARALLEL_FLAG=2
HFINS_EP MPP 下从 EP 插入非事务型 HUGE 表数据
HFI_EP MPP 下从 EP 插入事务型 HUGE 表数据
HFLKUP 根据 ROWID 检索非事务型 HUGE 表数据
HFLKUP2 根据 ROWID 检索事务型 HUGE 表数据
HFLKUP_EP MPP 下从 EP 根据 ROWID 检索非事务型 HUGE 表数据
HFLKUP2_EP MPP 下从 EP 根据 ROWID 检索事务型 HUGE 表数据
HFSCN 非事务型 HUGE 表的逐行扫描
HFSCN2 事务型 HUGE 表的逐行扫描
HFSEK 根据 KEY 检索非事务型 HUGE 表数据
HFSEK2 根据 KEY 检索事务型 HUGE 表数据
HFU 更新事务型 HUGE 表数据
HFUPD 更新非事务型 HUGE 表数据
HFUPD_EP MPP 下从 EP 更新非事务型 HUGE 表数据
HFU_EP MPP 下从 EP 更新事务型 HUGE 表数据
HIERARCHICAL QUERY 层次查询
HPM 水平分区表归并排序
INDEX JOIN LEFT JOIN2 索引左连接
INDEX JOIN SEMI JOIN2 索引半连接
INSERT 插入记录
INSERT3 MPP 下,查询插入优化处理
INSERT_LIST 堆表插入
INSERT_REMOTE DBLINK 插入操作
INTERSECT 集合的交运算,且取交集后删除重复项
INTERSECT ALL 集合的交运算,且取交集后不删除重复项
LOCAL BROADCAST 本地并行模式下,消息广播到各线程,包含必要的聚集函数合并计算
LOCAL COLLECT 本地并行下数据收集处理,代替 LOCAL GATHER
LOCAL DISTRIBUTE 本地并行模式下,消息各线程的相互重分发
LOCAL GATHER 本地并行模式下,消息收集到主线程
LOCAL SCATTER 本地并行模式下,主线程向各从线程广播消息
LOCK TID 上锁
LSET DBLINK 查询结果集
MERGE INNER JOIN3 归并内连接
MERGE SEMI JOIN3 归并半连接
MPP BROADCAST
MPP 模式下,消息广播到各站点,包含必要的聚集函数合并计算
MPP COLLECT 用于替换顶层 MPP GATHER,除了收集数据到主节点,还增加主从节点间的同步执行功能,防止从节点不断发送数据到主节点造成邮件堆积
MPP DISTRIBUTE MPP 模式下,消息各站点的相互重分发
MPP GATHER MPP 模式下,消息收集到主站点
MPP SCATTER MPP 模式下,主站点向各从站点广播消息
MSYNC MPP 下数据同步处理
MVCC CHECK 多版本检查
NCUR2 游标操作
NEST LOOP FULL JOIN2 嵌套循环全外连接
NEST LOOP INDEX JOIN2 索引内连接
NEST LOOP INNER JOIN2 嵌套循环内连接
NEST LOOP LEFT JOIN2 嵌套循环左外连接
NEST LOOP SEMI JOIN2 嵌套循环半连接
NTTS2 临时表,临时存放数据
NSET2 结果集(result set)收集,一般是查询计划的顶层节点
PARALLEL 控制水平分区子表的扫描
PIPE2 管道;先做一遍右儿子,然后执行左儿子,并把左儿子的数据向上送,直到左儿子不再有数据
PRJT2 关系的―投影‖(project)运算,用于选择表达式项的计算
PSCN 批量参数当作表来扫描
REMOTE SCAN DBLINK 远程表扫描
RN 实现 ROWNUM 查询
RNSK ROWNUM 作为过滤条件时的计算处理
SAGR2 如果输入流是有序的,则使用流分组,并计算聚集函数
SELECT INTO2 查询插入
SET TRANSACTION 事务操作(START 除外)
SLCT2 关系的―选择‖(select)运算,用于查询条件的过滤
SORT2 排序
SORT3 排序
SPL2 临时表;和 NTTS2 不同的是,它的数据集不向父亲节点传送,而是被编号,用编号和 KEY 来定位访问;而 NTTS2 的数据,主动传递给父亲节点
SSCN 直接使用二级索引进行扫描
SSEK2 二级索引数据定位
START TRANSACTION 启动会话
STAT 统计信息计算
TOPN2 取前 N 条记录
UFLT 处理 UPDATE FROM 子句
UNION UNION 计算
UNION ALL UNION ALL 运算
UNION ALL(MERGE) UNION ALL 运算(使用归并)
UNION FOR OR2 OR 过滤的 UNION 计算
UPDATE 更新数据
UPDATE_REMOTE DBLINK 更新操作
DM的SQL优化入门笔记的更多相关文章
- 浅谈SQL优化入门:3、利用索引
0.写在前面的话 关于索引的内容本来是想写的,大概收集了下资料,发现并没有想象中的简单,又不想总结了,纠结了一下,决定就大概写点浅显的,好吧,就是懒,先挖个浅坑,以后再挖深一点.最基本的使用很简单,直 ...
- 浅谈SQL优化入门:2、等值连接和EXPLAIN(MySQL)
1.等值连接:显性连接和隐性连接 在<MySQL必知必会>中对于等值连接有提到两种方式,第一种是直接在WHERE子句中规定如何关联即可,那么第二种则是使用INNER JOIN关键字.如下例 ...
- sql优化问题笔记(mysql)
相信大家平时面试都会遇到这个问题:平时你都是怎么对sql进行调优的? 此篇文章相当于一个随便笔记,根据朋友们的聊天记录整理而成,如有不对,请指正! 注意:这篇是以mysql整理的 查看sql计划分析 ...
- 《SQL优化入门》讲座总结
MySQL运行机制 MySQL每个query只能运行在一个CPU上,更多的CPU,更快的CPU会更有利于并发 MySQL执行计划 Using filesort: 表示无法利用索引完成排序,也有可能是因 ...
- 浅谈SQL优化入门:1、SQL查询语句的执行顺序
1.SQL查询语句的执行顺序 (7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_ ...
- mysql系列十一、mysql优化笔记:表设计、sql优化、配置优化
可以从这些方面进行优化: 数据库(表)设计合理 SQL语句优化 数据库配置优化 系统层.硬件层优化 数据库设计 关系数据库三范式 1NF:字段不可分; 2NF:有主键,非主键字段依赖主键; 3NF:非 ...
- sql优化详细介绍学习笔记
因为最近在面试,发现sql优化这个方面问的特别特别的多.之前都是零零星星,不够全面的了解一点,刚刚在网上查了一下,从 http://blog.csdn.net/zhushuai1221/article ...
- oracle sql优化笔记
oracle优化一般分为:1.sql优化(现在oracle都会根据sql语句先进行必要的优化处理,这种应该用户不大了,但是像关联和嵌套查询肯定是和影响性能的) A.oracle的sql语句的条件是从右 ...
- SQL优化笔记一:索引和explain
目录 为什么需要优化SQL SQL优化的重点 索引 索引的结构 索引的优缺点总结: 索引的分类 索引操作 B树 实战 问题 数据库方面,我会使用MySQL来讲解 为什么需要优化SQL 性能低,执行时间 ...
随机推荐
- Python下的图像处理库,你选哪个?
奥里给~ 转载:https://blog.csdn.net/chen801090/article/details/105795068/ 在进行数字图像处理时,我们经常需要对图像进行读取.保存.缩放.裁 ...
- 洛谷P1450 [HAOI2008]硬币购物 背包+容斥
无限背包+容斥? 观察数据范围,可重背包无法通过,假设没有数量限制,利用用无限背包 进行预处理,因为实际硬币数有限,考虑减掉多加的部分 如何减?利用容斥原理,减掉不符合第一枚硬币数的,第二枚,依次类推 ...
- 【linux-centos】安装ifstat!
1.卸载原装ifstat find / -name *ifstat* 把/usr/sbin/ifstat.ifstat的man目录的.gz文件删除 2.下载安装 wget http://gael.ro ...
- 题解:SDOI2017 新生舞会
题解:SDOI2017 新生舞会 Description 学校组织了一次新生舞会,Cathy 作为经验丰富的老学姐,负责为同学们安排舞伴. 有 \(n\) 个男生和 \(n\) 个女生参加舞会.一个男 ...
- pytest文档51-内置fixture之cache使用
前言 pytest 运行完用例之后会生成一个 .pytest_cache 的缓存文件夹,用于记录用例的ids和上一次失败的用例. 方便我们在运行用例的时候加上--lf 和 --ff 参数,快速运行上一 ...
- IE下文件上传, SCRIPT5: 拒绝访问 问题
最近遇到一个比较奇葩的问题,某些ie浏览器在页面中上传文件时,无法上传.查看控制台报错: SCRIPT5: 拒绝访问. jquery-3.2.1.min.js, 行4 字符5725 .并且我的最新版I ...
- centos8安装sersync为rsync实现实时同步
一,查看本地centos的版本: [root@localhost lib]# cat /etc/redhat-release CentOS Linux release 8.1.1911 (Core) ...
- centos8平台基于iftop监控网络流量
一,iftop的作用: 基于ip统计外部机器与本机之间的网络流量, 可以方便的查看各客户端是否有非正常的到本机的访问 说明:刘宏缔的架构森林是一个专注架构的博客,地址:https://www.cnbl ...
- 在VMware虚拟机Ubuntu使用traceroute
Linux traceroute命令用于显示数据包到主机间的路径 traceroute指令让你追踪网络数据包的路由途径,预设数据包大小是40Bytes,用户可另行设置. Ubuntu命令行输入: 后面 ...
- Dubbo源码本地运行demo遇到的问题
从github上拉下来的Dubbo源码,运行Dubbo项目的demo工程,报如下错误(Dubbo版本为2.7.6): Exception in thread "main" java ...