golang 爬取百度贴吧绝地求生页面
package main import (
"github.com/antchfx/htmlquery"
"io"
"net/http"
"os"
"strconv"
) func main() {
base_url := "https://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&ie=utf-8&pn=" var start ,end int start = 1
end = 20 for i:=start;i<=end;i++{
url := base_url + strconv.Itoa((i-1)*50)
result := download(url) list := parse(result)
f,_ := os.Create( strconv.Itoa(i) +".html") for _,v := range list{
f.WriteString(v+"\n")
}
f.Close()
} } func download(url string) (result io.Reader) {
resp,_ := http.Get(url) return resp.Body
} func parse(resp io.Reader) (result[]string ) {
doc,_ := htmlquery.Parse(resp)
list := htmlquery.Find(doc, "//div[@class='t_con cleafix']") slice := make([]string, 5) for _,n := range list {
//number := htmlquery.FindOne(n,".//span[contains(@class,'num')]/text()")
title := htmlquery.FindOne(n,".//a/@title")
//numstring := htmlquery.InnerText(number)
titlestring := htmlquery.SelectAttr(title,"title") slice = append(slice, titlestring)
} return slice
}
效果
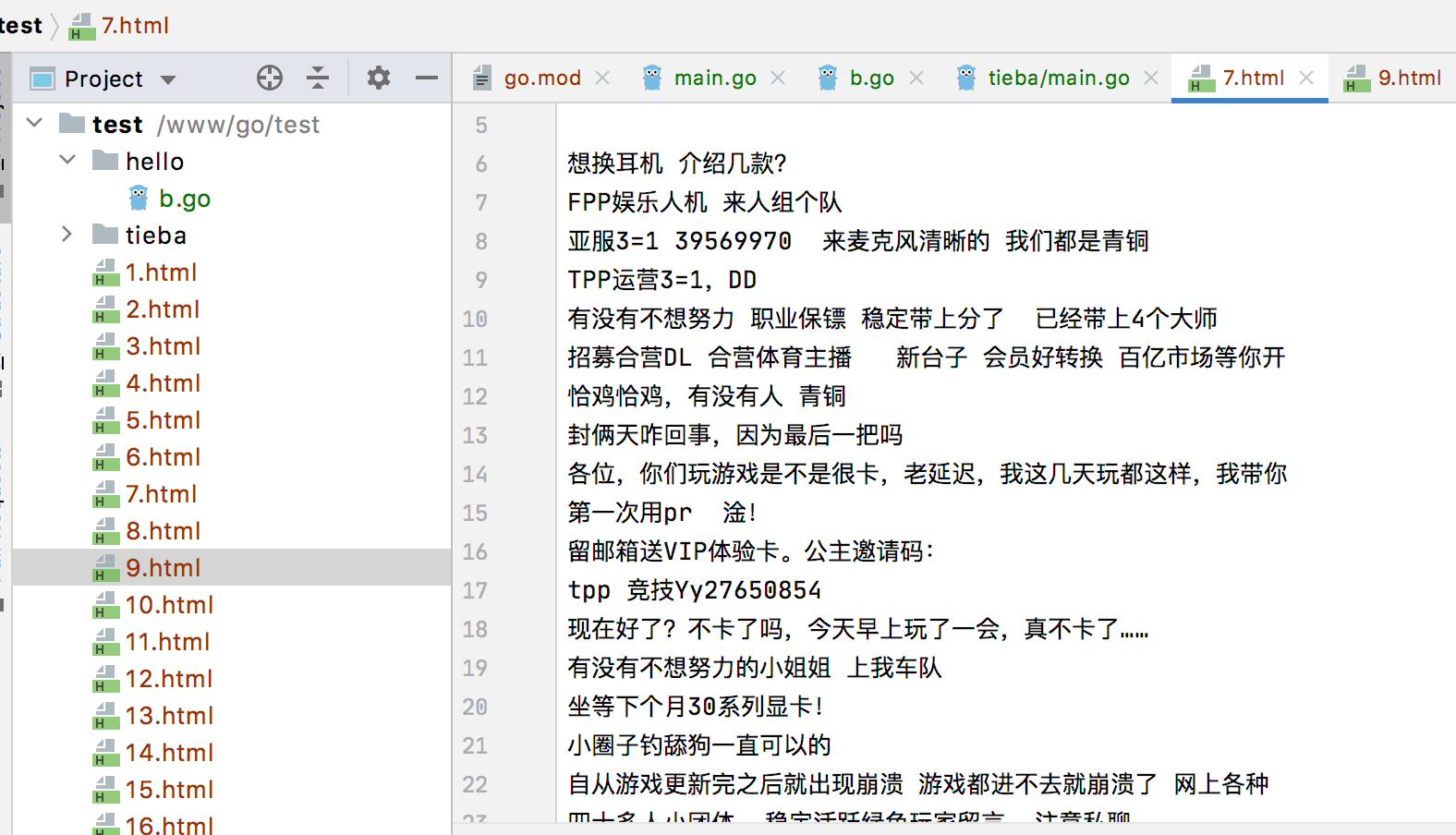
golang 爬取百度贴吧绝地求生页面的更多相关文章
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- 利用python的爬虫技术爬取百度贴吧的帖子
在爬取糗事百科的段子后,我又在知乎上找了一个爬取百度贴吧帖子的实例,为了巩固提升已掌握的爬虫知识,于是我打算自己也做一个. 实现目标:1,爬取楼主所发的帖子 2,显示所爬去的楼层以及帖子题目 3,将爬 ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- requests+xpath+map爬取百度贴吧
# requests+xpath+map爬取百度贴吧 # 目标内容:跟帖用户名,跟帖内容,跟帖时间 # 分解: # requests获取网页 # xpath提取内容 # map实现多线程爬虫 impo ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- scrapy关键字爬取百度图库(一)
刚入门学习python的菜鸟,如有错误,还望指教 爬取百度图库需要知道百度图库的加载方式是通过下拉加载的,所以我们需要分析Ajax请求来爬取每一页的数据信息 表述不清直接上图片 图片一是刷新页面后加载 ...
- python爬取百度贴吧帖子
最近偶尔学下爬虫,放上第二个demo吧 #-*- coding: utf-8 -*- import urllib import urllib2 import re #处理页面标签类 class Too ...
随机推荐
- path.resolve和path.join的区别
// test.js const path = require('path') let x1 = path.resolve('/目录1/目录2', '/目录3/目录4/') let x2 = path ...
- 2020年 .NET ORM 完整比较、助力选择
.NET ORM 前言 为什么要写这篇文章? 希望针对 SEO 优化搜索引擎,让更多中国人知道并且使用.目前百度搜索 .NET ORM 全是 sqlsugar,我个人是无语的,每每一个人进群第一件事就 ...
- 乔悟空-CTF-i春秋-Web-SQL
2020.09.05 是不是有些题已经不能做了--费了半天,到最后发现做不出来,和网上大神的方法一样也不行,最搞笑的有个站好像是别人运营中的,bug好像被修复了-- 做题 题目 题目地址 做题 尝试简 ...
- [LeetCode]301. 删除无效的括号(DFS)
题目 题解 step1. 遍历一遍,维护left.right计数器,分别记录不合法的左括号.右括号数量. 判断不合法的方法? left维护未匹配左括号数量(增,减)(当left为0遇到右括号,则交由r ...
- 浅入 ABP 系列(4):事件总线
浅入 ABP 系列(4):事件总线 版权护体作者:痴者工良,微信公众号转载文章需要 <NCC开源社区>同意. 目录 浅入 ABP 系列(4):事件总线 事件总线 关于事件总线 为什么需要这 ...
- docker部署LAMP架构并部署上线wordpress博客系统
第一步:直接在镜像仓库拉取LAMP镜像 [root@ken-node3 ken]# docker pull tutum/lamp 第二步:查看已经获取到的镜像 [root@ken-node3 ken] ...
- 基于MAXIMO的发电行业EAM解决方案
1. 行业背景 随着我国以“厂网分开,竞价上网”为特点的电力市场的起步和发展,发电厂.发电集团成为独立企业参与市场竞争,原有的“生产型”管理模式已经不再适应市场的需求.发电企业在重视安全质量.保证电力 ...
- redis命令和RedisTemplate操作对应表
redis命令和RedisTemplate操作对应表 redisTemplate.opsForValue();//操作字符串 redisTemplate.opsForHash();//操作hash r ...
- Redis中有序列表(ZSet)相关命令
redis语序集合和集合set是一样内部value为string类型的集合,有序不允许重复元素 但是,zset的每个元素有一个double类型的分数(score).redis正是靠这个分数对元素从小到 ...
- Centos-网络下载文件-wget
wget 指定URL从网络上下载某个文件,需要网络连接 相关选项 -nc 不覆盖同名文件 -q 安静下载,无输出 -v 显示下载详情 -O 指定保存目录或重命名下载文件名 -c 断点续 ...