redis源码学习之slowlog

背景
redis虽说是一个基于内存的KV数据库,以高性能著称,但是依然存在一些耗时比较高的命令,比如keys *,lrem等,更有甚者会在lua中写一些比较耗时的操作,比如大循环里面执行命令等,鉴于此,本篇将从源码角度分析redis慢日志的记录原理,并给出一些自己的看法。
环境说明
win10+redis v2.8.9,对本地调试redis源码感兴趣的可以参考我另一篇文章redis源码学习之工作流程初探。
redis执行命令流程
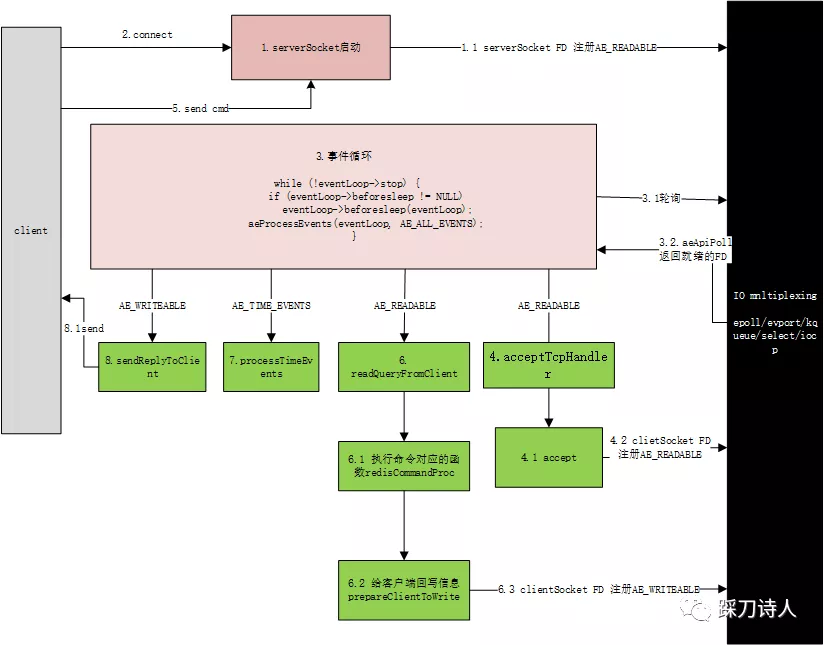
在这里就不重复redis的执行流程了,不清楚的可以参考我之前的文章redis源码学习之工作流程初探,这里重点说一下6.1,这一步是真实执行redis命令的地方,redis记录慢日志也是这一步实现的。
记录slowlog源码分析
1.执行redis 命令之前获取当前时间;
2.执行redis 命令之后计算耗时;
3.如果开启了记录slowlog而且耗时大于设置的阈值就将slowlog记录下来;
4.如果slowlog数目大于了设置的最大记录数,就移除最早插入的slowlog;
redis.c
/* Call() is the core of Redis execution of a command */
void call(redisClient *c, int flags) {
...
/* Call the command. */
c->flags &= ~(REDIS_FORCE_AOF|REDIS_FORCE_REPL);
redisOpArrayInit(&server.also_propagate);
dirty = server.dirty;
//执行命令前获取当前时间
start = ustime();
//执行命令对应的commandProc
c->cmd->proc(c);
//命令执行完成计算耗时,单位为ms
duration = ustime()-start;
dirty = server.dirty-dirty;
//记录slowlog
if (flags & REDIS_CALL_SLOWLOG && c->cmd->proc != execCommand)
slowlogPushEntryIfNeeded(c->argv,c->argc,duration);
}
slowlog.c
/* Push a new entry into the slow log.
* This function will make sure to trim the slow log accordingly to the
* configured max length. */
void slowlogPushEntryIfNeeded(robj **argv, int argc, long long duration) {
//如果slowlog_log_slower_than 小于0,说明不需要记录
if (server.slowlog_log_slower_than < 0) return; /* Slowlog disabled */
//耗时大于 slowlog_log_slower_than,说明需要记录,
//slowlog_log_slower_than默认为10ms
if (duration >= server.slowlog_log_slower_than)
listAddNodeHead(server.slowlog,slowlogCreateEntry(argv,argc,duration));
//slowlog记录数大于slowlog_max_len,就移除最早的那条slowlog
/* Remove old entries if needed. */
while (listLength(server.slowlog) > server.slowlog_max_len)
listDelNode(server.slowlog,listLast(server.slowlog));
}
/* Create a new slowlog entry.
* Incrementing the ref count of all the objects retained is up to
* this function. */
slowlogEntry *slowlogCreateEntry(robj **argv, int argc, long long duration) {
slowlogEntry *se = zmalloc(sizeof(*se));
int j, slargc = argc;
if (slargc > SLOWLOG_ENTRY_MAX_ARGC) slargc = SLOWLOG_ENTRY_MAX_ARGC;
//参数数量
se->argc = slargc;
//具体参数
se->argv = zmalloc(sizeof(robj*)*slargc);
for (j = 0; j < slargc; j++) {
/* Logging too many arguments is a useless memory waste, so we stop
* at SLOWLOG_ENTRY_MAX_ARGC, but use the last argument to specify
* how many remaining arguments there were in the original command. */
if (slargc != argc && j == slargc-1) {
se->argv[j] = createObject(REDIS_STRING,
sdscatprintf(sdsempty(),"... (%d more arguments)",
argc-slargc+1));
} else {
/* Trim too long strings as well... */
if (argv[j]->type == REDIS_STRING &&
argv[j]->encoding == REDIS_ENCODING_RAW &&
sdslen(argv[j]->ptr) > SLOWLOG_ENTRY_MAX_STRING)
{
sds s = sdsnewlen(argv[j]->ptr, SLOWLOG_ENTRY_MAX_STRING);
s = sdscatprintf(s,"... (%lu more bytes)",
(unsigned long)
sdslen(argv[j]->ptr) - SLOWLOG_ENTRY_MAX_STRING);
se->argv[j] = createObject(REDIS_STRING,s);
} else {
se->argv[j] = argv[j];
incrRefCount(argv[j]);
}
}
}
//发生时间
se->time = time(NULL);
//耗时
se->duration = duration;
//slowlog id,server.slowlog_entry_id自增
se->id = server.slowlog_entry_id++;
return se;
}
制造一条slowlog
为了讲解方便我使用断点的方式制造一条slowlog,方式如下:
1.连接redis,执行get 1;
2.ide 断点在redis.c 的Call函数c->cmd->proc处
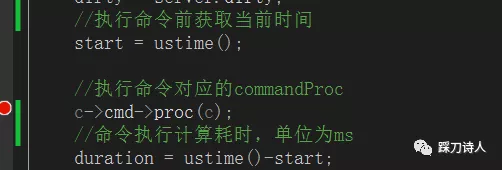
3.等待10s+以后继续执行,即可产生一条例slowlog;
4.查看slowlog
127.0.0.1:6379> slowlog get
1) 1) (integer) 0 #slowlog 标识,从0开始递增
2) (integer) 1606033532 #slowlog产生时间,unix时间戳格式
3) (integer) 28049157 #执行命令耗时
4) 1) "get" # 执行的命令
2) "1"
slowlog分析
通过前面的章节对slowlog的写入过程有了一个初步的了解,其中有这么几点我要重点提一下:
1.slowlog如何开启
slowlog默认情况下是开启的,主要受限于slowlog-log-slower-than的设置,如果其大于0意味着开始slowlog,默认值为10ms,可以通过修改redis配置文件或者使用CONFIG SET这种方式,单位为微秒;
2.slowlog数量限制
默认情况下只会存储128条记录,超过128会丢弃最早的那条记录,可以通过修改redis配置文件或者使用CONFIG SET slowlog-max-len这种方式;
3.slowlog中的耗时的含义
耗时只包括执行命令的时间,不包括等待、网络传输的时间,这个不难理解,从redis的工作模型可知,redis执行命令采用单线程方式,所以内部有排队机制,如果之前的命令非常耗时,只会影响redis整体的吞吐量,但不一定会影响当前命令的执行时间,比如client执行一条命令整体耗时20s,但是slowlog记录的耗时只有10s;
4.slowlog中时间戳的含义
切记这个时间戳是redis产生slowlog的时间,不是执行redis命令的时间。
自己的一些思考
如果开发人员反馈redis响应变慢了,我们应该从哪些方面去排查呢?
1.查看slowlog分析是否有慢查情况,比如使用使用了keys *等命令;
2.slowlog中没有慢日志,可以结合应用程序中一些埋点来分析,可能是网络问题,找运维协助查看网络是否丢包、带宽是否被打满等问题;
3.如果排除网络问题,那可能是redis机器本身负载过高,排查内存、swap、负载等情况;
4.任何以高性能著称的组件都不是银弹,使用时一定要了解其api,比如keys命令,作者已经明确的说了其时间复杂度为O(N)数据量大时会有性能问题。

推荐阅读
Redis常见延迟问题排查手册
redis源码学习之工作流程初探
来我的公众号与我交流

redis源码学习之slowlog的更多相关文章
- Redis源码学习:字符串
Redis源码学习:字符串 1.初识SDS 1.1 SDS定义 Redis定义了一个叫做sdshdr(SDS or simple dynamic string)的数据结构.SDS不仅用于 保存字符串, ...
- Redis源码学习:Lua脚本
Redis源码学习:Lua脚本 1.Sublime Text配置 我是在Win7下,用Sublime Text + Cygwin开发的,配置方法请参考<Sublime Text 3下C/C++开 ...
- 柔性数组(Redis源码学习)
柔性数组(Redis源码学习) 1. 问题背景 在阅读Redis源码中的字符串有如下结构,在sizeof(struct sdshdr)得到结果为8,在后续内存申请和计算中也用到.其实在工作中有遇到过这 ...
- __sync_fetch_and_add函数(Redis源码学习)
__sync_fetch_and_add函数(Redis源码学习) 在学习redis-3.0源码中的sds文件时,看到里面有如下的C代码,之前从未接触过,所以为了全面学习redis源码,追根溯源,学习 ...
- redis源码学习之工作流程初探
目录 背景 环境准备 下载redis源码 下载Visual Studio Visual Studio打开redis源码 启动过程分析 调用关系图 事件循环分析 工作模型 代码分析 动画演示 网络模块 ...
- redis源码学习之lua执行原理
聊聊redis执行lua原理 从一次面试场景说起 "看你简历上写的精通redis" "额,还可以啦" "那你说说redis执行lua脚本的原理&q ...
- Redis源码学习-Master&Slave的命令交互
0. 写在前面 Version Redis2.2.2 Redis中可以支持主从结构,本文主要从master和slave的心跳机制出发(PING),分析redis的命令行交互. 在Redis中,serv ...
- redis源码学习-skiplist
1.初步认识跳跃表 图中所示,跳跃表与普通链表的区别在于,每一个节点可以有多个后置节点,图中是一个4层的跳跃表 第0层: head->3->6->7->9->12-> ...
- Redis源码学习1-sds.c
https://github.com/huangz1990/redis-3.0-annotated/blob/unstable/src/sds.c#L120 /* SDSLib, A C dynami ...
随机推荐
- ps 批量kill进程
Linux下批量kill掉进程 ps -ef|grep java|grep -v grep|cut -c 9-15|xargs kill -9 管道符"|"用来隔开两个命令,管 ...
- Python之for循环和列表
for循环: 有限循环 基本语法: for 变量 in 可迭代对象: 循环体 也可使用break,continue,for else list列表初识: 列表可放任意数据类型:[int,str,boo ...
- C# 获取两点(经纬度表示)间的距离
#region 获取两点(经纬度表示)间的距离 /// <summary> /// 获取两点(经纬度表示)间的距离 /// </summary> /// <param n ...
- Anderson《空气动力学基础》5th读书笔记导航
没错,在2018年,我正式启程了安德森教授这本空气动力学圣经的阅读,为了深入理解概念,特写此刊,边读边写,2020年一定写完,写不完我就/¥@%¥---! 以下是导航: 第一章任务图: 第一章思维导图 ...
- 图的全部实现(邻接矩阵 邻接表 BFS DFS 最小生成树 最短路径等)
1 /** 2 * C: Dijkstra算法获取最短路径(邻接矩阵) 3 * 6 */ 7 8 #include <stdio.h> 9 #include <stdlib.h> ...
- Volley获取json对象
url必须返回一个json文本,由于网上没有找到返回json的url,我用Tomcat写了一个json文件, 在这个文件夹下见一个以json后缀的json文件,内容是json文本,然后输入浏览器输入h ...
- Spring Boot打包部署
date: 2018-11-19 15:30:11 updated: 2018-11-21 08:28:37 Spring Boot打包部署 第一种方式 打包成jar包部署在服务器上 1.1 添加插件 ...
- router-view组件在app.vue中渲染不出来怎么办
1.在app.vue使用router-view组件直接渲染 页面什么都没显示,可能问题出在路由配置上了,检查路由是否配置完好,路由挂载那里必须使用routes属性 2.在app.vue中router- ...
- C# 中的只读结构体(readonly struct)
翻译自 John Demetriou 2018年4月8日 的文章 <C# 7.2 – Let's Talk About Readonly Structs>[1] 在本文中,我们来聊一聊从 ...
- Excel基础—为什么学习Excel
吾生也有涯,而知也无涯 点赞再看,养成习惯 自从个人计算机开始普及以后,Excel就得到了广泛的传播,工作学习生活中不处不存在Excel的影子,不论是考勤,工资还是其他的统计等等,都离不开Excel. ...