ubuntu 16.0安装 hadoop2.8.3
环境:ubuntu 16.0
需要软件:jdk ssh
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
2.8.3
安装 jdk并配置环境变量
安装ssh和rshync,主要设置免密登录
sudo apt-get install ssh
sudo apt-get install rshync
sh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh
安装hadoop
root@hett-virtual-machine:/usr/local/hadoop# tar -xzvf /home/hett/Downloads/hadoop-2.8.3.tar.gz
root@hett-virtual-machine:/usr/local/hadoop# mv hadoop-2.8.3 hadoop
root@hett-virtual-machine:/usr/local# cd hadoop/
root@hett-virtual-machine:/usr/local/hadoop# mkdir tmp
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs/data
root@hett-virtual-machine:/usr/local/hadoop# mkdir hdfs/name
root@hett-virtual-machine:/usr/local/hadoop# nano /etc/profile
配置
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/local/jdk1.8.0_151
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:$HADOOP_HOME/bin
root@hett-virtual-machine:/usr/local/hadoop# source /etc/profile
root@hett-virtual-machine:/usr/local/hadoop# cd etc/hadoop/
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop# ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop#
root@hett-virtual-machine:/usr/local/hadoop/etc/hadoop# nano hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151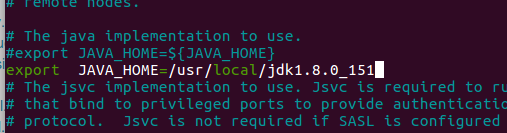
配置yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_151
3)配置core-site.xml
添加如下配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>4),配置hdfs-site.xml
添加如下配置
<configuration>
<!—hdfs-site.xml-->
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>5),配置mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>6),配置yarn-site.xml
添加如下配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.241.128:8099</value>
</property>
</configuration>4,Hadoop启动
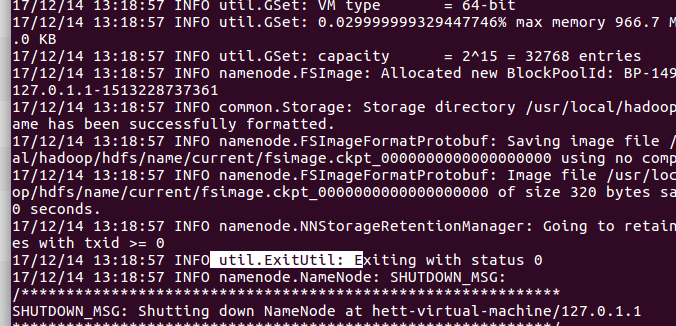
1)格式化namenode
$ bin/hdfs namenode –format
2)启动NameNode 和 DataNode 守护进程
$ sbin/start-dfs.sh3)启动ResourceManager 和 NodeManager 守护进程
$ sbin/start-yarn.sh

- $ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
- $ ssh-keygen -t rsa # 会有提示,都按回车就可以
- $ cat id_rsa.pub >> authorized_keys # 加入授权

root@hett-virtual-machine:~# cd /usr/local/hadoop/
root@hett-virtual-machine:/usr/local/hadoop# sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hett-virtual-machine.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hett-virtual-machine.out
........
5,启动验证
1)执行jps命令,有如下进程,说明Hadoop正常启动
# jps
6097 NodeManager
11044 Jps
7497 -- process information unavailable
8256 Worker
5999 ResourceManager
5122 SecondaryNameNode
8106 Master
4836 NameNode
4957 DataNode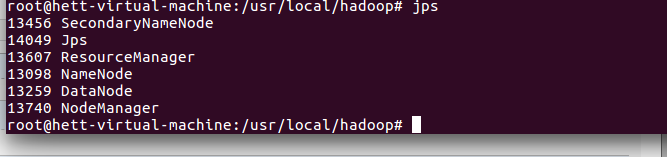
ubuntu 16.0安装 hadoop2.8.3的更多相关文章
- Ubuntu 16.04安装Vim8.0
Ubuntu 16.04安装Vim8.0 https://www.aliyun.com/jiaocheng/131859.html sudo add-apt-repository ppa:jonath ...
- Ubuntu 16.04 安装Mysql 5.7 踩坑小记
title:Ubuntu 16.04 安装Mysql 5.7 踩坑小记 date: 2018.02.03 安装mysql sudo apt-get install mysql-server mysql ...
- ubuntu 16.04 安装 tensorflow-gpu 包括 CUDA ,CUDNN,CONDA
ubuntu 16.04 安装 tensorflow-gpu 包括 CUDA ,CUDNN,CONDA 显卡驱动装好了,如图: 英文原文链接: https://github.com/williamFa ...
- Ubuntu 16.04 安装 VMware Tools(解决windows和Ubuntu之间不能互相复制粘贴文件的问题)
Ubuntu 16.04安装虚拟工具VMware Tools,指的是在虚拟机VMWare安装Ubuntu 16.04后再安装VMware Tools的过程.很多人接触Linux都是从虚拟机开始,而安装 ...
- Ubuntu 16.04 安装Mysql数据库
系统环境 Ubuntu 16.04; 安装步骤 1.通过以下环境安装mysql服务端与客户端软件 sudo apt-get install mysql-server apt-get isntall m ...
- Ubuntu 16.04安装sogou 拼音输入法
一.更换为国内的软件源 安装搜狗输入法之前请先更换为国内的软件源,否则无法解决依赖问题.首先,用以下命令打开源列表: sudo gedit /etc/apt/sources.list #用文本编辑器打 ...
- ubuntu 16.04 安装Tensorflow
ubuntu 16.04 安装Tensorflow(CPU) 安装python ubuntu 16.04自带python2.7,因此可以略过这一步 安装pip sudo apt-get install ...
- Ubuntu 16.04安装tensorflow_gpu的方法
参考资料: Ubuntu 16.04安装tensorflow_gpu 1.9.0的方法 装Tensorflow,运行项目报错: module compiled against API version ...
- ubuntu 16.04 安装pycharm
Ubuntu16.04下安装Cuda8.0+Caffe+TensorFlow-gpu+Pycharm过程(Simple) ubuntu 16.04 安装pycharm 1.安装java jdk 直接 ...
随机推荐
- 20个Flutter实例视频教程-第09节: 保持页面状态-2
视频地址:https://www.bilibili.com/video/av39709290/?p=9 博客地址:https://jspang.com/post/flutterDemo.html#to ...
- shell脚本函数与数组
前言 之前写过一篇关于shell脚本流程控制总结,这次继续写关于shell脚本的问题.本篇文章主要包含shell脚本中的函数以及数组的用法介绍.同时也涵盖了一些字符串处理以及shell脚本比较使用的小 ...
- Win10 VC++运行库集合|VC++ 2005 2008 2010 2012 2015
在Win10系统中很多朋友在运行一些软件时会遇到缺少.DLL的情况,主要是没有安装VC++运行库下面小编收集了Win10 VC++运行库集合,大家安装上去就可以了~ 微软常用软件运行库合集(vc201 ...
- 利用jstack定位典型性能问题实例
此文已由作者朱笑天授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 问题的起因是笔者在一轮性能测试的中,发现某协议的响应时间很长,去观察哨兵监控里的javamethod监控可以 ...
- html实现点击图片放大功能
话不多说,直接上代码 <html> <head> <style> .over {position: fixed; left:0; top:0; width:100% ...
- hdoj1253
一题简直模板的 BFS,只是三维遍历而已. #include <stdio.h> #include <iostream> #include <sstream> #i ...
- mongodb c# 序列化时 , Id引起的问题
1. c# 序列化时,如果没有指名_id , 如果class,struct有MemberName为 Id ,_id , 则自动识别为Id . 如果此时,这个"Id"是只读属性,就 ...
- jzoj5989. 【北大2019冬令营模拟2019.1.6】Forest (set)
题面 题解 为了一点小细节卡了一个下午--我都怕我瞎用set把电脑搞炸-- 观察一次\(1\)操作会造成什么影响,比如说把\(A[i]\)从\(x\)改成\(y\): \(D[x]\)会\(-1\), ...
- MySQL索引的学习
MySQL索引的学习 关于使用mysql索引的好处,合理的设计并使用mysql索引能够有效地提高查询效率.对于没有索引的表,单表查询可能几十万数据就是平静,在大型网站单日可能会产生几十万甚至几百万的数 ...
- Date类学习一