3.1-3.3 HBase Shell创建表
一、HBase Shell创建表
1、HBASE shell命令
##
hbase(main):001:0> create_namespace 'ns1' //创建命名空间:ns1
hbase(main):002:0> list_namespace //查看命名空间 ##
hbase(main):003:0> create 'ns1:t1', 'cf' //创建一个表t1,属于ns2命名空间,列族:cf hbase(main):005:0> create 'ns1:t2',{NAME =>'f1'},{NAME =>'f2'},{NAME =>'f3'} //创建一张表,有三个列族f1 f2 f3
hbase(main):009:0> create 'ns1:t3', 'f1', 'f2', 'f3' hbase(main):010:0> list_namespace_tables 'ns1' //查看命名空间下的表 hbase(main):011:0> describe 'ns1:t2' //查看命名空间下的表的结构
二、HBase表创建时的预分区
1、预分区
HBase默认建表时有一个region,这个region的rowkey是没有边界的,即没有startkey和endkey,在数据写入时,所有数据都会写入这个默认的region,
随着数据量的不断 增加,此region已经不能承受不断增长的数据量,会进行split,分成2个region。在此过程中,会产生两个问题:
1.数据往一个region上写,会有写热点问题。
2.region split会消耗宝贵的集群I/O资源。
基于此我们可以控制在建表的时候,创建多个空region,并确定每个region的起始和终止rowky,这样只要我们的rowkey设计能均匀的命中各个region,
就不会存在写热点问题。自然split的几率也会大大降低。当然随着数据量的不断增长,该split的还是要进行split。像这样预先创建hbase表分区的方式,称之为预分区;
2、预分区方式1
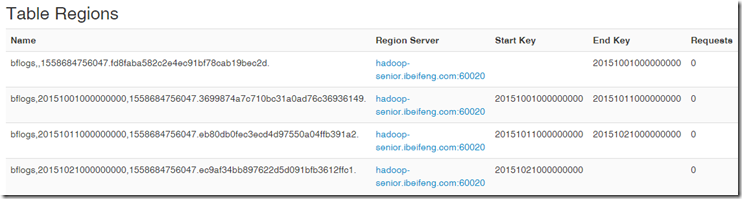
hbase(main):015:0> create 'bflogs', 'info', SPLITS => ['20151001000000000', '20151011000000000', '20151021000000000']
指定预估rowkey(年月日时分秒毫秒):
’20151001000000000’
’20151011000000000’
’20151021000000000’
生成了4个region:
3、预分区方式2
##
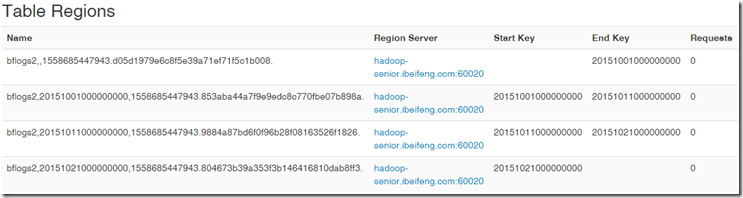
可以把预估rowkey,放到文件中 [root@hadoop-senior datas]# cat bflogs-split.txt
20151001000000000
20151011000000000
20151021000000000 ##建表
hbase(main):016:0> create 'bflogs2', 'info', SPLITS_FILE => '/opt/datas/bflogs-split.txt'
生成了4个region:
4、预分区方式3
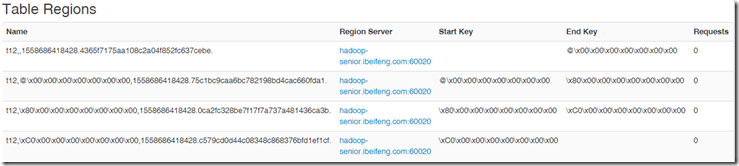
##自动生成预分区rowkey,不常用 ##方式1
hbase(main):017:0> create 't11', 'f11', {NUMREGIONS => 2, SPLITALGO => 'HexStringSplit'} //生成两个rowkey ##方式2
hbase(main):018:0> create 't12', 'f12', {NUMREGIONS => 4, SPLITALGO => 'UniformSplit'} //生成4个rowkey
方式1

方式2
3.1-3.3 HBase Shell创建表的更多相关文章
- HBase之创建表
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; impo ...
- 证明,为什么HBase在创建表时,列簇是必须要,列可不要?
若是删除不存在的列修饰符,看下会是什么情况 package zhouls.bigdata.HbaseProject.Test1; import javax.xml.transform.Result; ...
- 关于HBase Shell命令基本操作示例
HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase Shell”. HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建. ...
- 通过HBase Shell与HBase交互
出处:http://www.taobaotest.com/blogs/1604 业务开发测试HBase之旅二:通过HBase Shell与HBase交互 yedu 发表于:2011-10-11 浏览: ...
- HBase shell 命令创建表及添加数据操作
创建表,表名hbase_1102,HBase表是由Key-Value组成的,此表中Key为NAME 此表有两个列族,CF1和CF2,其中CF1和CF2下分别有两个列name和gender,Chin ...
- hbase java API跟新数据,创建表
package hbaseCURD; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import o ...
- 云计算与大数据实验:Hbase shell操作用户表
[实验目的] 1)了解hbase服务 2)学会hbase shell命令操作用户表 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件存储系统,利用Ha ...
- 云计算与大数据实验:Hbase shell操作成绩表
[实验目的] 1)了解hbase服务 2)学会hbase shell命令操作成绩表 [实验原理] HBase是一个分布式的.面向列的开源数据库,它利用Hadoop HDFS作为其文件存储系统,利用Ha ...
- 使用hbase的api创建表时出现的异常
/usr/lib/jvm/java-7-openjdk-amd64/bin/java -Didea.launcher.port=7538 -Didea.launcher.bin.path=/usr/l ...
随机推荐
- vs2010音频文件压缩 调用lame_enc.dll将WAV格式转换成MP3
/* //My_lame.h */ #pragma once#include "stdafx.h"#include <windows.h>#include <st ...
- angular 复选框checkBox多选的应用
应用场景是这样的,后台返回的数据在页面上复选框的形式repeat出来 可能会有两种需求: 第一:后台返回的只有项,而没有默认选中状态(全是待选状态) 这种情况相对简单只要repeat出相应选项 第二: ...
- C#Soket组播
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.N ...
- JS中小数如何转化为百分数并能四舍五入
<script type="text/javascript">//n表示百分数保留的位数 function toPercent(n){ n = n || 2; retu ...
- ajax跨域请求的问题
使用getJson跨域请求,需要向服务器发送一个参数callback=? $.getJSON("http://appcenter.mobitide.com/admin/appSearch.p ...
- EasyDarwin开源云平台接入海康威视EasyCamera摄像机之快照获取与上传
本文转自EasyDarwin团队成员Alex的博客:http://blog.csdn.net/cai6811376 EasyCamera开源摄像机拥有获取摄像机实时快照并上传至EasyDarwin云平 ...
- javascript 获取当前日期 月份 时间
<script type="text/javascript"> function getDate() { var date = new Date(); //得到当前日期 ...
- Linux环境下安装MySQL(yum方式)
1.下载mysql源安装包shell> wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm 安装my ...
- machine learning for hacker记录(2) 数据分析
本章主要讲了对数据的一些基本探索,常见的six numbers,方差,均值等 > data.file <- file.path('data', '01_heights_weights_ge ...
- ThinkPHP Widget模块开发流程
初识ThinkPHP的Widget,现把模块开发的流程发布如下,也方便以后自己查阅: 一.新建数据库表self_modules,sql代码如下 CREATE TABLE `self_modules` ...