Mind the Box: $\ell_1$-APGD for Sparse Adversarial Attacks on Image Classifiers
概
以往的\(\ell_1\)攻击, 为了保证
\]
其是通过两步投影的方式完成的, 即
\]
其中\(B_1\)表示1范数球, 而\(H\)表示\([0, 1]^d\)的空间.
本文直接
\]
主要内容
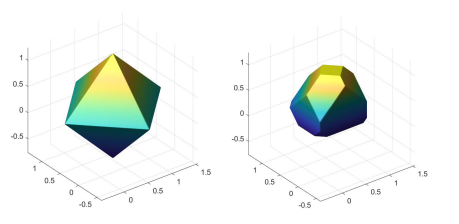
上图展示了1范数球和\(S\), 可以发现, 差别还是很大的.
正因如此, 和\(\ell_{\infty}, \ell_2\)不同, 基于二步投影的\(\ell_1\)攻击非常低效.
于是乎, 作者直接投影到\(S\), 即考虑如下的优化问题:
\mathrm{s.t.} \: \|z - x\|_1 \le \epsilon, \: z \in [0, 1]^d.
\]
不妨令\(\tilde{w} = z - x\), 则
\mathrm{s.t.} \: \|\tilde{w}\|_1 \le \epsilon, \: \tilde{w} + x \in [0, 1]^d.
\]
再令\(w = \mathrm{sign}(u-x) \tilde{w}\), 此时有
\mathrm{s.t.} \: \|w\|_1 \le \epsilon, \: \mathrm{sign}(u-x)w+ x \in [0, 1]^d.
\]
显然, \(w\)非负(否则徒增消耗罢了).
为此, 我们可以归结为上述问题为下述类型问题:
\mathrm{s.t.} \: \sum_i z_i \le \epsilon, \: z_i \ge 0, \: \mathrm{sign}(u)z + x \in [0, 1]^d.
\]
约束条件可以进一步改写为
z_i \in [0, \gamma_i], \\
\gamma_i = \max \{-x\mathrm{sign} (u), (1 - x)\mathrm{sign}(u) \}.
\]
注: 这是从这篇论文中学到的一个很有趣的技巧:
& a \le \mathrm{sign}(u)z + x \le b \\
\Leftrightarrow&
\mathrm{sign}(u) a \le z + \mathrm{sign}(u) x \le \mathrm{sign}(u)b \\
or & \mathrm{sign}(u) b \le z + \mathrm{sign}(u) x \le \mathrm{sign}(u)a \\
\Leftrightarrow&
z \in [(a - x)\mathrm{sign}(u), (b - x)\mathrm{sign}(u)].
\end{array}
\]
下面通过拉格朗日乘子法求解(既然是个凸问题, 假设\(\gamma > 0\)):
\]
由此可得KKT条件:
\lambda (\sum_i z_i - \epsilon) = 0; \\
\alpha_i z_i = 0, \beta_i (z_i - \gamma_i) = 0; \\
\lambda, \alpha_i, \beta_i \ge 0.
\]
故
\]
我们再来具体分析:
1.
\Rightarrow z_i = \gamma_i > 0 \Rightarrow \alpha_i = 0.
\]
故
\]
\]
故
\]
于是
\begin{array}{ll}
0, & \lambda > |u_i| \\
|u_i| - \lambda, & |u_i| - \gamma_i \le \lambda \le |u_i| \\
\gamma_i, & \lambda < |u_i| - \gamma_i.
\end{array}
\right .
\]
其中\(\lambda\)是下列方程的解:
\]
其有一个特殊的表达方式:
\]
故
\]
若\(\lambda=0\)时:
\]
则此时\(\lambda=0\)恰为最优解, 否则需要通过
\]
求解出\(\lambda\).
因为\(\sum_i \max(0, \min(\gamma_i, |u_i| - \lambda))\)关于\(\lambda\)是单调递减的, 作者给了一个方便的算法求解(虽然我对这个算法的表述有一点点疑惑).
除了投影之外, 作者还给出了一个最速下降方向, 证明是类似的.
作者关于\(\ell\)攻击的分析感觉很通透, 不错的文章啊.
Mind the Box: $\ell_1$-APGD for Sparse Adversarial Attacks on Image Classifiers的更多相关文章
- Defending Adversarial Attacks by Correcting logits
目录 概 主要内容 实验 Li Y., Xie L., Zhang Y., Zhang R., Wang Y., Tian Q., Defending Adversarial Attacks by C ...
- DEFENSE-GAN: PROTECTING CLASSIFIERS AGAINST ADVERSARIAL ATTACKS USING GENERATIVE MODELS
目录 概 主要内容 Samangouei P, Kabkab M, Chellappa R, et al. Defense-GAN: Protecting Classifiers Against Ad ...
- Towards Deep Learning Models Resistant to Adversarial Attacks
目录 概 主要内容 Note Madry A, Makelov A, Schmidt L, et al. Towards Deep Learning Models Resistant to Adver ...
- 论文阅读 | Real-Time Adversarial Attacks
摘要 以前的对抗攻击关注于静态输入,这些方法对流输入的目标模型并不适用.攻击者只能通过观察过去样本点在剩余样本点中添加扰动. 这篇文章提出了针对于具有流输入的机器学习模型的实时对抗攻击. 1 介绍 在 ...
- Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2001.01587v1 [cs.NE] 1 Jan 2020 Abstract 脉冲神经网络(SNN)被广泛应用于神经形态设 ...
- Adversarial Detection methods
目录 Kernel Density (KD) Local Intrinsic Dimensionality (LID) Gaussian Discriminant Analysis (GDA) Gau ...
- Adversarial Examples Are Not Bugs, They Are Features
目录 概 主要内容 符号说明及部分定义 可用特征 稳定可用特征 可用不稳定特征 标准(standard)训练 稳定(robust)训练 分离出稳定数据 分离出不稳定数据 随机选取 选取依赖于 比较重要 ...
- Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks
目录 概 主要内容 算法 一些有趣的指标 鲁棒性定义 合格的抗干扰机制 Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, Ananthram ...
- Adversarial Examples Improve Image Recognition
Xie C, Tan M, Gong B, et al. Adversarial Examples Improve Image Recognition.[J]. arXiv: Computer Vis ...
随机推荐
- day19 进程管理
day19 进程管理 什么是进程,什么是线程 1.什么是程序 一般情况下,代码,安装包等全部都是应用程序 2.什么是进程 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进 ...
- 【1】Embarrassingly Parallel(易并行计算问题)
1.什么是Embarrassingly Parallel(易并行计算问题) 易并行计算问题:A computation that can be divided into a number of co ...
- JDK1.8新特性(一): 接口的默认方法default
前言 今天在学习mysql分区优化时,发现一个博客专家大神,对其发布的文章简单学习一下: 一:简介 我们通常所说的接口的作用是用于定义一套标准.约束.规范等,接口中的方法只声明方法的签名,不提供相应的 ...
- zabbix之故障自治愈和分层报警
在agent端修改配置文件 root@ubuntu:~# vim /etc/sudoers zabbix ALL=(ALL) NOPASSWD:ALL#:重启服务root@ubuntu:~# syst ...
- delete() and free() in C++
In C++, delete operator should only be used either for the pointers pointing to the memory allocated ...
- RunLoop基础知识以及GCD
- 1.1 字面意思 a 运行循环 b 跑圈 - 1.2 基本作用(作用重大) a 保持程序的持续运行(ios程序因而能一直活着不会死) b 处理app中的各种事件(比如触摸事件 ...
- 【Linux】【Shell】【Basic】字符串操作
1. 字符串切片: ${var:offset:number} 取字符串的子串: 取字符趾的最右侧的几个字符:${ ...
- maven常用命令(待补充)
1.mvn clean 删除已经编译好的信息 2.mvn compile 编译src/main/java目录下的.java文件 3.mvn test 编译src/main/java和src/test/ ...
- 【C/C++】例题3-6 环状序列/算法竞赛入门经典/数组和字符串
[字典序比较] 对于两个字符串,比较字典序,从第一个开始,如果有两位不一样的出现,那么哪个的ASCII码小,就是字典序较小.如果都一样,那么短的小. [题目] 输入一个环状串,输出最小的字典序序列. ...
- 自动执行Python脚本
一.自动执行Python脚本(前提条件是电脑已安装对应的Python程序) 1.1.win+R-输入cmd在输入where python查看Python的安装位置 C:\Users\ASUS\AppD ...