RDD的运行机制
1. RDD 的设计与运行原理
Spark 的核心是建立在统一的抽象 RDD 之上,基于 RDD 的转换和行动操作使得 Spark 的各个组件可以无缝进行集成,从而在同一个应用程序中完成大数据计算任务。
在实际应用中,存在许多迭代式算法和交互式数据挖掘工具,这些应用场景的共同之处在于不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。而 Hadoop 中的 MapReduce 框架都是把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销,并且通常只支持一些特定的计算模式。而 RDD 提供了一个抽象的数据架构,从而让开发者不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同 RDD 之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销。
一个 RDD 就是一个分布式对象集合,提供了一种高度受限的共享内存模型,其本质上是一个只读的分区记录集合,不能直接修改。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段,并且一个 RDD 的不同分区可以保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD 提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定 RDD 之间的相互依赖关系。RDD 提供的转换接口都非常简单,都是类似 map 、filter 、groupBy 、join 等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD 比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如 Web 应用系统、增量式的网页爬虫等。
RDD 的典型的执行过程如下:
读入外部的数据源(或者内存中的集合)进行 RDD 创建;
RDD 经过一系列的 “转换” 操作,每一次都会产生不同的 RDD,供给下一个转换使用;
最后一个 RDD 经过 “行动” 操作进行处理,并输出指定的数据类型和值。
RDD 采用了惰性调用,即在 RDD 的执行过程中,所有的转换操作都不会执行真正的操作,只会记录依赖关系,而只有遇到了行动操作,才会触发真正的计算,并根据之前的依赖关系得到最终的结果。
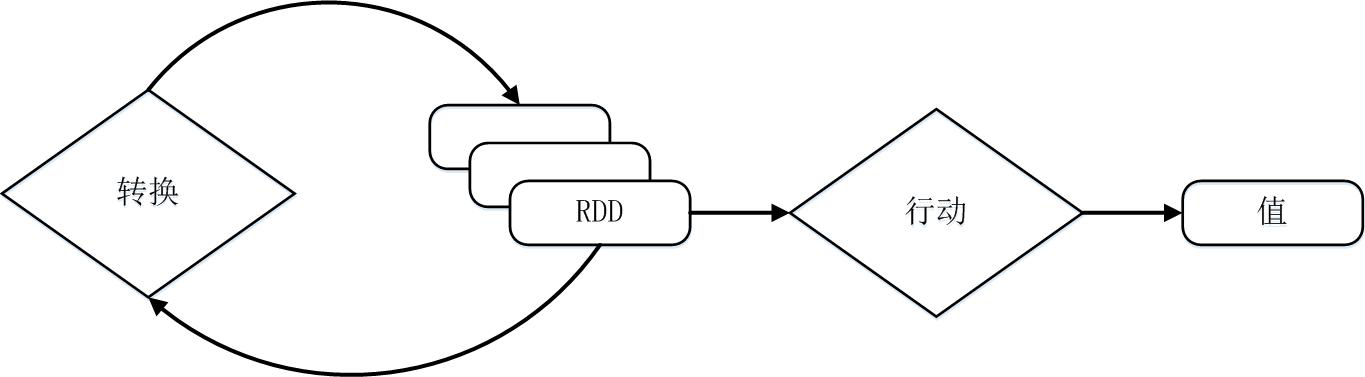
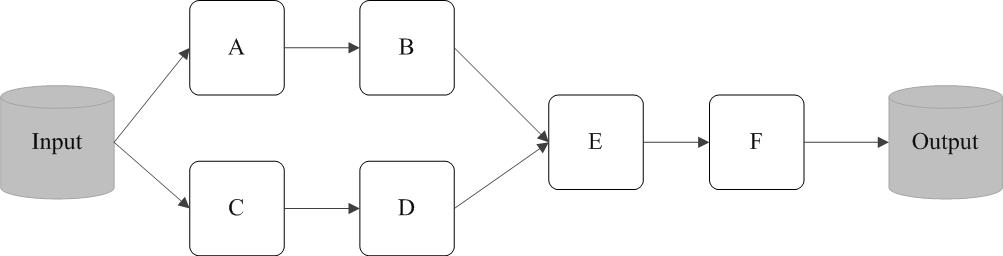
下面以一个实例来描述 RDD 的实际执行过程,如下图所示,开始从输入中创建了两个 RDD,分别是 A 和 C,然后经过一系列的转换操作,最终生成了一个 F,这也是一个 RDD。注意,这些转换操作的执行过程中并没有执行真正的计算,基于创建的过程也没有执行真正的计算,而只是记录的数据流向轨迹。当 F 执行了行为操作并生成输出数据时,Spark 才会根据 RDD 的依赖关系生成有向无环图(DAG),并从起点开始执行真正的计算。正是 RDD 的这种惰性调用机制,使得转换操作得到的中间结果不需要保存,而是直接管道式的流入到下一个操作进行处理。
总体而言,Spark 采用 RDD 以后能够实现高效计算的主要原因如下:
高效的容错性。在 RDD 的设计中,只能通过从父 RDD 转换到子 RDD 的方式来修改数据,这也就是说我们可以直接利用 RDD 之间的依赖关系来重新计算得到丢失的分区,而不需要通过数据冗余的方式。而且也不需要记录具体的数据和各种细粒度操作的日志,这大大降低了数据密集型应用中的容错开销。
中间结果持久化到内存。数据在内存中的多个 RDD 操作之间进行传递,不需要在磁盘上进行存储和读取,避免了不必要的读写磁盘开销;
存放的数据可以是 Java 对象,避免了不必要的对象序列化和反序列化开销。
RDD 中的不同的操作会使得不同 RDD 中的分区会产生不同的依赖关系,主要分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency)。其中,窄依赖表示的是父 RDD 和子 RDD 之间的一对一关系或者多对一关系,主要包括的操作有 map、filter、union 等;而宽依赖则表示父 RDD 与子 RDD 之间的一对多关系,即一个父 RDD 转换成多个子 RDD,主要包括的操作有 groupByKey、sortByKey 等。
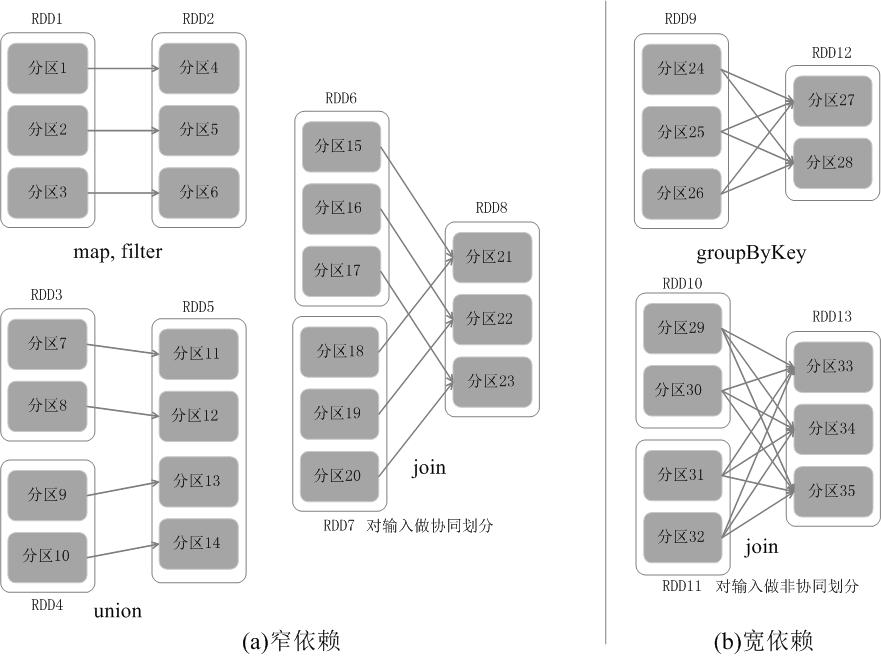
对于窄依赖的 RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的 RDD,则通常伴随着 Shuffle 操作,即首先需要计算好所有父分区数据,然后在节点之间进行 Shuffle。因此,在进行数据恢复时,窄依赖只需要根据父 RDD 分区重新计算丢失的分区即可,而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父 RDD 分区,开销较大。此外,Spark 还提供了数据检查点和记录日志,用于持久化中间 RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark 会对数据检查点开销和重新计算 RDD 分区的开销进行比较,从而自动选择最优的恢复策略。
Spark 通过分析各个 RDD 的依赖关系生成了 DAG ,再通过分析各个 RDD 中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在 DAG 中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。例如在下图中,首先根据数据的读取、转化和行为等操作生成 DAG。然后在执行行为操作时,反向解析 DAG,由于从 A 到 B 的转换和从 B、F 到 G 的转换都属于宽依赖,则需要从在宽依赖处进行断开,从而划分为三个阶段。把一个 DAG 图划分成多个 “阶段” 以后,每个阶段都代表了一组关联的、相互之间没有 Shuffle 依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给 Executor 运行。
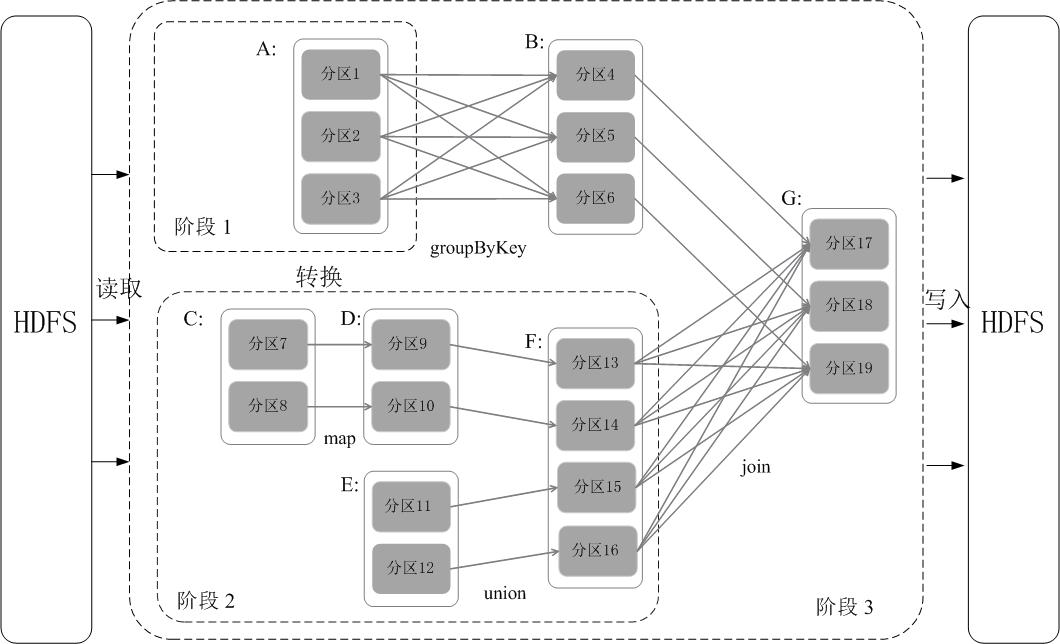
通过上述对 RDD 概念、依赖关系和阶段划分的介绍,结合之前介绍的 Spark 运行基本流程,这里再总结一下 RDD 在 Spark 架构中的运行过程(如下图所示):
创建 RDD 对象;
SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG;
DAGSchedule 负责把 DAG 图反向解析成多个阶段,每个阶段中包含多个任务,每个任务会被任务调度器分发给工作节点上的 Executor 上执行。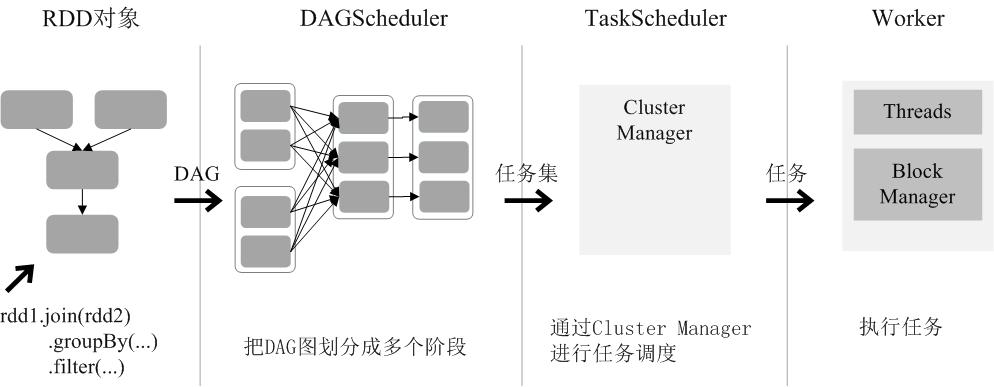
RDD的运行机制的更多相关文章
- Spark 中 RDD的运行机制
1. RDD 的设计与运行原理 Spark 的核心是建立在统一的抽象 RDD 之上,基于 RDD 的转换和行动操作使得 Spark 的各个组件可以无缝进行集成,从而在同一个应用程序中完成大数据计算任务 ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- Spark Streaming揭秘 Day19 架构设计和运行机制
Spark Streaming揭秘 Day19 架构设计和运行机制 今天主要讨论一些SparkStreaming设计的关键点,也算做个小结. DStream设计 首先我们可以进行一个简单的理解:DSt ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- 【Spark 深入学习 04】再说Spark底层运行机制
本节内容 · spark底层执行机制 · 细说RDD构建过程 · Job Stage的划分算法 · Task最佳计算位置算法 一.spark底层执行机制 对于Spark底层的运行原理,找到了一副很好的 ...
- 2.Spark Streaming运行机制和架构
1 解密Spark Streaming运行机制 上节课我们谈到了技术界的寻龙点穴.这就像过去的风水一样,每个领域都有自己的龙脉,Spark就是龙脉之所在,它的龙穴或者关键点就是SparkStreami ...
- (十三)Maven插件解析运行机制
这里给大家详细说一下Maven的运行机制,让大家不仅知其然,更知其所以然. 1.插件保存在哪里? 与我们所依赖的构件一样,插件也是基于坐标保存在我们的Maven仓库当中的.在用到插件的时候会先从本地仓 ...
随机推荐
- lua之自索引
Father={ a=100, b=200 } function Father:dis() print(self.a,self.b) end Father.__index=Father Son= { ...
- 网络支持IPV6地址测试校验与思考
概述 大背景:随着移动端的快速扩张,互联网的规模越来越广阔,早于2011年耗尽的IPV4地址越来越无法满足互联网的网络地址需求,IPV6地址推广进入快车道.实际情况:近期公司应上级部门邀请对公司的主域 ...
- JavaWeb后端工程师技能图
- linux正则表达式(全面解析)
目录 一:linux正则表达式介绍 二:普通正则表达式 三:扩展正则 一:linux正则表达式介绍 1.正则表达式的分类(grep) 1.普通正则表达式 2.扩展正则表达式 二:普通正则表达式 ^ : ...
- Ubuntu 18.04 安装教程
准备材料 Ubuntu安装U盘 足够的硬盘空间 未初始化的硬盘需要提前初始化 注意事项 Ubuntu安装盘的制作请参考我的另外一个博客,里面写清楚了怎么制作Ubuntu安装盘,步骤非常简单 请将要拿给 ...
- SpringBoot集成druid数据库连接池的简单使用
简介 Druid是阿里巴巴旗下Java语言中最好的数据库连接池.Druid能够提供强大的监控和扩展功能. 官网: https://github.com/alibaba/druid/wiki/常见问题 ...
- Java数组问题:Array constants can only be used in initializers
感谢大佬:https://www.cnblogs.com/fanerwei222/p/11491571.html 感谢大佬:https://blog.csdn.net/weixin_42591732/ ...
- git每次操作都要输入账号密码 解决方案
1.执行命令: git config --global credential.helper store git pull 2.输入用户名密码,以后就不会再次要求用户名密码了
- java篇之JDBC原理和使用方法
JDBC学过但又属于很容易忘记的那种,每次要用到,都要看下连接模式.每次找又很费时间,总之好麻烦呀呀呀,所以写篇博客,总结下原理和常用接口,要是又忘了可以直接来博客上看,嘿嘿. 一.什么是JDBC 1 ...
- Java使用DOM方式读写XML
一.DOM读取 import ***; public class ReadXML { public static void main(String[] args) { try { //DOM Docu ...