python爬取北京政府信件信息02
在爬取详细信息页面中,又遇到了问题,就是标签内的信息爬取,用re的正则表达式没有找到解决办法,只能又去网上搜索解决办法
用bs4来解决,用
soup = BeautifulSoup(text,"html.parser")#解析text中的HTML
来进行分析,虽说这样会有标签信息附着,从网上找到解决办法,
第一种方法
调用find(text=True).strip()
第二种方法
调用stripped_strings
第三种方法
.get_text().lstrip().rstrip()
个人感觉第三种很好用,在实践之后特意添加
经过测试,不是很理想,对于简单的,只有div标签的很容易,对于第一种,好多p标签的就不好用了,正在寻找更加实用的代码
for add in ad:
r = add
address_ = "http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=%s" % add
print(address_)
# 爬取子页面的网页
html2 = requests.get(address_,headers = head2).text
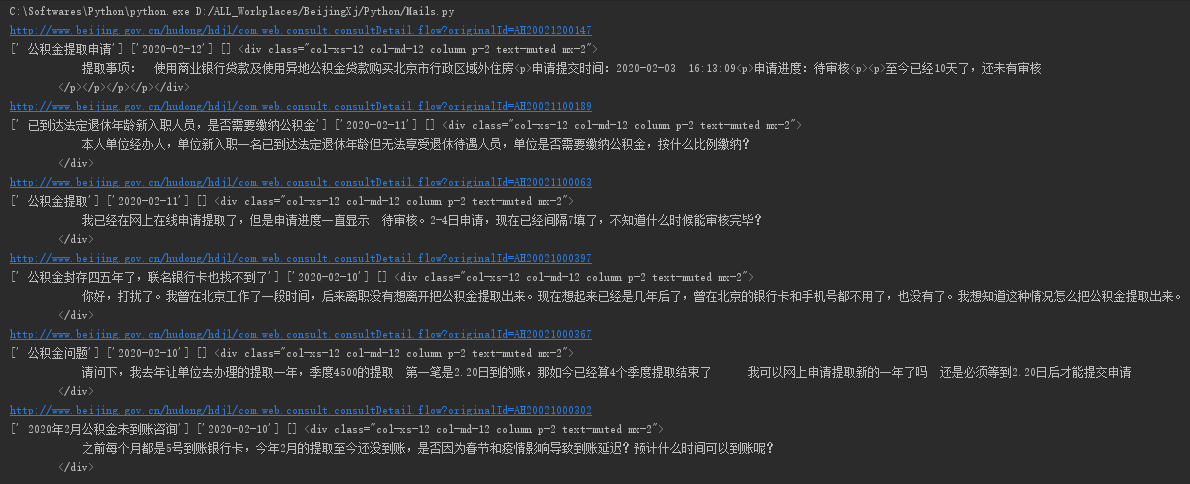
reqname = re.findall(r'<div class="col-xs-10 col-sm-10 col-md-10 o-font4 my-2"><strong>(.*?)</strong></div>',html2)
reqtime = re.findall(r'<div class="col-xs-5 col-lg-3 col-sm-3 col-md-3 text-muted ">时间:(.*?)</div>',html2)
reqcontent = re.findall(r'<div class="col-xs-12 col-md-12 column p-2 text-muted mx-2">(.*?)</div>',html2)
# resname = re.findall(r'<strong>[官方回答]:</strong>(.*?)</div>',html2)
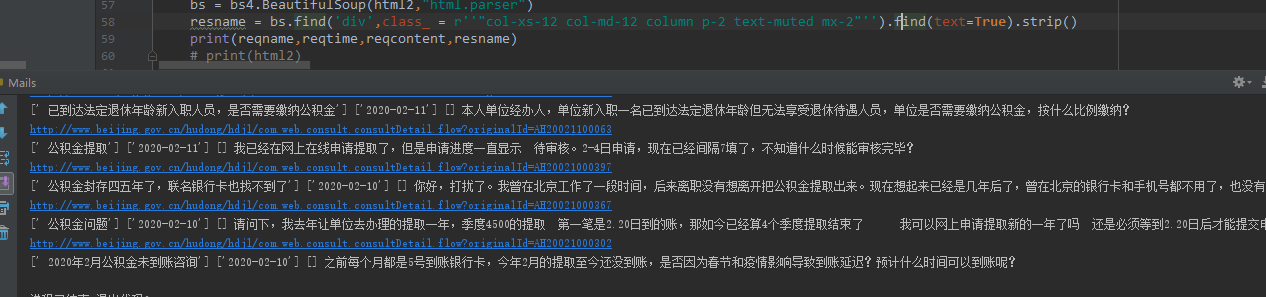
bs = bs4.BeautifulSoup(html2,"html.parser")
resname = bs.find('div',class_ = r''"col-xs-12 col-md-12 column p-2 text-muted mx-2"'')
print(reqname,reqtime,reqcontent,resname)
# print(html2)
python爬取北京政府信件信息02的更多相关文章
- python爬取北京政府信件信息01
python爬取,找到目标地址,开始研究网页代码格式,于是就开始根据之前学的知识进行爬取,出师不利啊,一开始爬取就出现了个问题,这是之前是没有遇到过的,明明地址没问题,就是显示网页不存在,于是就在百度 ...
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- python爬取 “得到” App 电子书信息
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 静觅 崔庆才 PS:如有需要Python学习资料的小伙伴可以加点击下 ...
- Python爬取房天下二手房信息
一.相关知识 BeautifulSoup4使用 python将信息写入csv import csv with open("11.csv","w") as csv ...
- 这价格看得我偷偷摸了泪——用python爬取北京二手房数据
如果想了解更多关于python的应用,可以私信我,或者加群,里面到资料都是免费的 http://t.cn/A6Zvjdun 近期,有个朋友联系我,想统计一下北京二手房的相关的数据,而自己用Excel统 ...
- 【python】用python爬取中科院院士简介信息
018/07/09 23:43 项目名称:爬取中科院871个院士的简介信息 1.爬取目的:中科院871个院士的简介信息 2.爬取最终结果: 3.具体代码如下: import re # 不用安装(注意! ...
- Python 爬取赶集网租房信息
代码已久,有可能需要调整 #coding:utf-8 from bs4 import BeautifulSoup #有这个bs4不用正则也可以定位要爬取的内容了 from urlparse impor ...
- 利用python爬取贝壳网租房信息
最近准备换房子,在网站上寻找各种房源信息,看得眼花缭乱,于是想着能否将基本信息汇总起来便于查找,便用python将基本信息爬下来放到excel,这样一来就容易搜索了. 1. 利用lxml中的xpath ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
随机推荐
- 同一个Controller里的同一个Service实例,在当前的Controller里的不同方法中状态不一致
直接上代码如下: @Controller@RequestMapping("/views/information")public class PubContentController ...
- Python_Selenium 之以login_page为例实现对basepage封装好的方法调用和对common中公共方法的调用
目的:简化代码,提供框架该有的东西每一个函数 -提供了一个功能 - 公共的功能有了basepage,在PageObjects当中直接调用元素操作. 以下以login_page 为例,实现从配置文件中读 ...
- Linux基础_vim命令
简介:Vim是从 vi 发展出来的一个文本编辑器.代码补完.编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用. vi/vim 共分为三种模式,分别是命令模式(Command mode)也叫 ...
- 端午总结Vue3中computed和watch的使用
1使用计算属性 computed 实现按钮是否禁用 我们在有些业务场景的时候,需要将按钮禁用. 这个时候,我们需要使用(disabled)属性来实现. disabled的值是true表示禁用.fals ...
- 性能监控之常见 Java Heap Dump 方法
一.前言 在本文中,我们总结下抓 Java dump 的几种不同方法. Java Heap Dump 是特定时刻 JVM 内存中所有对象的快照.它们对于解决内存泄漏问题和分析 Java 应用程序中的内 ...
- 【题解】Luogu P1011 车站
题目描述 火车从始发站(称为第1站)开出,在始发站上车的人数为a,然后到达第2站,在第2站有人上.下车,但上.下车的人数相同,因此在第2站开出时(即在到达第3站之前)车上的人数保持为a人.从第3站起( ...
- Linux命令(磁盘的卸载与挂载)
一.光盘挂载与卸载: 1.将光盘CD-ROM(hdc)安装到文件系统的/mnt/cdrom目录下的命令是 C . A mount /mnt/cdrom B mount /mnt/cdrom /dev ...
- Luat Demo | 一文读懂,如何使用Cat.1开发板实现Camera功能
让万物互联更简单,合宙通信高效便捷的二次开发方式Luat,为广大客户提供了丰富实用的Luat Demo示例,便于项目开发灵活应用. 本期采用合宙全新推出的VSCode插件LuatIDE,为大家演示如何 ...
- Go语言Slice作为函数参数详解
Go语言Slice作为函数参数详解 前言 首先要明确Go语言中实质只有值传递,引用传递和指针传递是相对于参数类型来说. 个人认为上诉的结论不对,把引用类型看做对指针的封装,一般封装为结构体,结构体是值 ...
- 7、openstack安装
1.openstack配置架构图: 2.主机设置: (1)两台主机名分别是controller和compute1: hostnamectl set-hostname controller hostna ...