MobileNet系列之MobileNet_v2
Inception系列之Batch Normalization
导言:
MobileNet_v2提出了一些MobileNet_v1存在的一些问题,并在此基础上提出了改进方案。其主要贡献为提出了线性瓶颈(Linear Bottlenecks)和倒残差(Inverted Residuals)。
关注公众号CV技术指南,及时获取更多计算机视觉技术总结文章。
01Linear Bottlenecks


如上图所示,MobileNet_v2提出ReLU会破坏在低维空间的数据,而高维空间影响比较少。因此,在低维空间使用Linear activation代替ReLU。如下图所示,经过实验表明,在低维空间使用linear layer是相当有用的,因为它能避免非线性破坏太多信息。

此外,如果输出是流形的非零空间,则使用ReLU相当于是做了线性变换,将无法实现空间映射,因此MobileNet_v2使用ReLU6实现非零空间的非线性激活。
上方提出使用ReLU会破坏信息,这里提出ReLU6实现非零空间的非线性激活。看起来有些难以理解。这里提出我自己的理解。
根据流形学习的观点,认为我们所观察到的数据实际上是由一个低维流形映射到高维空间的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上这些数据只要比较低的维度的维度就能唯一的表示。

图像分布是在高维空间,神经网络中使用非线性激活函数实现将高维空间映射回低维流形空间。而这里提出使用ReLU6即增加了神经网络对非零空间的映射,否则,在非零空间使用ReLU相当于线性变换,无法映射回流形低维空间。而前文提出的使用线性激活函数来代替ReLU是在已经映射后的流形低维空间。
区别就是ReLU6是在将高维空间映射到流形低维空间时使用,Linear layer是在映射后的流形低维空间中使用。
其使用的如下表所示


02 Inverted Residuals
MobileNet_v1中的结构如下左图,MobileNet_v2如下右图。、
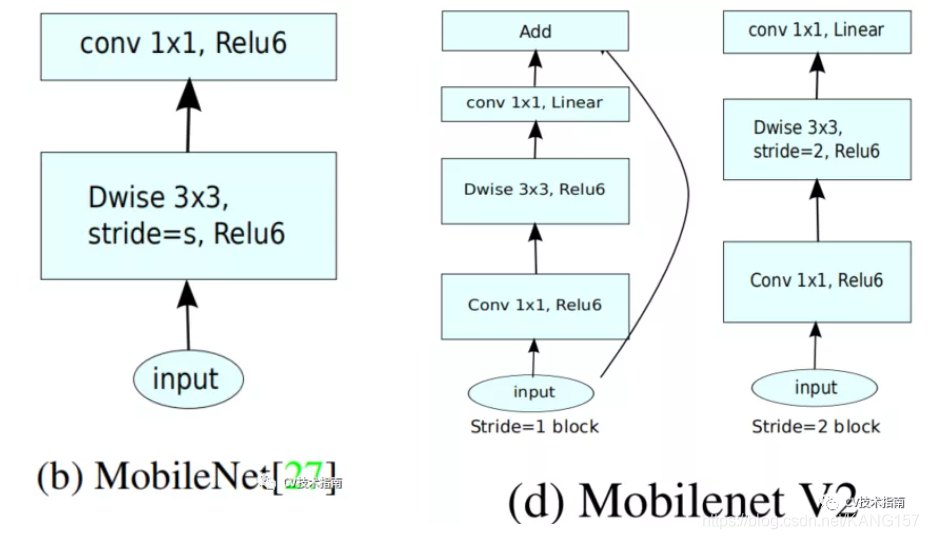
MobileNet_v2是在2018年发表的,此时ResNet已经出来了,经过几年的广泛使用表明,shortcut connection和Bottlenck residual block是相当有用的。MobileNet_v2中加入了这两个结构。

但不同的是,ResNet中的bottleneck residual是沙漏形的,即在经过1x1卷积层时降维,而MobileNet_v2中是纺锤形的,在1x1卷积层是升维。这是因为MobileNet使用了Depth wise,参数量已经极少,如果使用降维,泛化能力将不足。
此外,在MobileNet_v2中没有使用池化来降维,而是使用了步长为2的卷积来实现降维,此外如上图所示,步长为2的block没有使用shortcut connection。

这里的t是膨胀因子,取6。
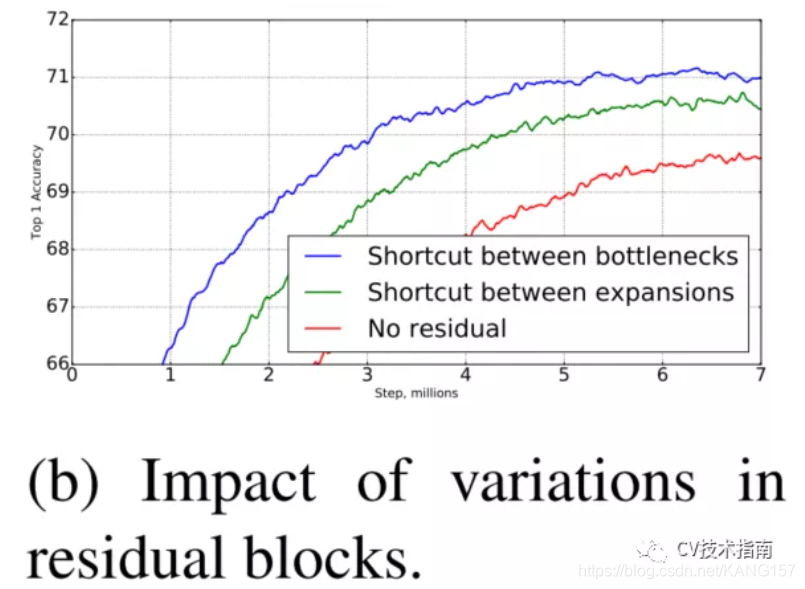
Inverted residuals block 与ResNet中的residuals block对比如下图所示:

图来源于网络
ResNet中residual block是两端大,中间小。而MobileNet_v2是中间大,两端小,刚好相反,作者把它取名为Inverted residual block。
整体结构如下图所示:

论文里提到Bottleneck有19层,但其给出的结构图中却只有17层。
MobileNet_v2相比与MobileNet_v1,参数量有所增加,主要增加在于Depth wise前使用1x1升维。此外,在CPU上的推理速度也比后者慢,但精度更高。

本文来源于公众号 CV技术指南 的模型解读系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取以下文章的汇总pdf。

其它文章
MobileNet系列之MobileNet_v2的更多相关文章
- MobileNet系列
最近一段时间,重新研读了谷歌的mobilenet系列,对该系列有新的认识. 1.MobileNet V1 这篇论文是谷歌在2017年提出了,专注于移动端或者嵌入式设备中的轻量级CNN网络.该论文最大的 ...
- 卷积神经网络学习笔记——轻量化网络MobileNet系列(V1,V2,V3)
完整代码及其数据,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote 这里结合网络的资料和Mo ...
- 轻量化模型之MobileNet系列
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 计算机视觉--CV技术指南文章汇总
前言 本文汇总了过去本公众号原创的.国外博客翻译的.从其它公众号转载的.从知乎转载的等一些比较重要的文章,并按照论文分享.技术总结三个方面进行了一个简单分类.点击每篇文章标题可阅读详细内容 欢迎关注 ...
- MovibleNet
MobileNet MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications MobileN ...
- MobileNetV1/V2/V3简述 | 轻量级网络
MobileNet系列很重要的轻量级网络家族,出自谷歌,MobileNetV1使用深度可分离卷积来构建轻量级网络,MobileNetV2提出创新的inverted residual with line ...
- 深度学习论文翻译解析(十九):Searching for MobileNetV3
论文标题:Searching for MobileNetV3 论文作者:Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Che ...
- CNN结构演变总结(一)经典模型
导言: 自2012年AlexNet在ImageNet比赛上获得冠军,卷积神经网络逐渐取代传统算法成为了处理计算机视觉任务的核心. 在这几年,研究人员从提升特征提取能力,改进回传梯度更新效果 ...
- 旷视MegEngine核心技术升级
旷视MegEngine核心技术升级 7 月 11 日,旷视研究院在 2020 WAIC · 开发者日「深度学习框架与技术生态论坛」上围绕 6 月底发布的天元深度学习框架(MegEngine)Beta ...
随机推荐
- 5分钟让你理解K8S必备架构概念,以及网络模型(下)
写在前面 在这用XMind画了一张导图记录Redis的学习笔记和一些面试解析(源文件对部分节点有详细备注和参考资料,欢迎关注我的公众号:阿风的架构笔记 后台发送[导图]拿下载链接, 已经完善更新): ...
- java基础——初识面向对象
面向对象 面向过程&面向对象 面向过程思想 步骤请简单:第一步做什么,第一步做什么 面向过程适合处理一些较为简单的东西 面向对象思想 物以类聚,分类的思维模式,思考的问题首先会解决问题需要哪些 ...
- 用JIRA管理你的项目——(二)JIRA语言包支持及插件支持
昨天兴奋地把JIRA环境搭好,瞅了一眼管理界面--全英文,真是汗! 尚且不说全中文版管理界面让人操作起来多少会有困难,更别说是全英文! 昨天赞叹JIRA语言包支持丰富,今天终于找到了号称100%的语言 ...
- HTML中的全局属性
一.全局属性和局部属性 每种元素都有自己规定的属性,这种属性成为局部属性.还有另外一种属性,他可以用来配置所有元素的共有行为,这种属性成为称为全局属性.全局属性可以用在任何一个元素身上,但是不一定会带 ...
- Linux_yum工具基本概述
一.什么是yum 1️⃣:yum是yellowdog update manager的简称,它能够实现rpm管理的所有操作,并能够自动解决各rpm包之间的依赖关系. 2️⃣:yum是rpm的前端工具,是 ...
- linux基础之权限管理
本节内容 1. 权限类别 属主(owner) 属组(group) 其他人(other) 2. 查看权限 ls -l 十位: 第一位文件类型-,d,l, 3. 设置权限 chmod 选项 权限模式 fi ...
- mysql基础之mysql主从架构
一.概念 主从多用于网站架构,因为主从的同步机制是异步的,数据的同步有一定延迟,也就是说有可能会造成数据的丢失,但是性能比较好,因此网站大多数用的是主从架构的数据库,读写分离必须基于主从架构来搭建 二 ...
- JavaEE 前后端分离以及优缺点
前端概念 前端是一切直接与用户交互的页面或软件(用户看得见.摸得着)的统称,比如各种网站网页.andorid 手机各种 App.苹果手机各种 app.微信小程序.网络游戏客户端等.所以,普通人使用计算 ...
- 常用数据库连接池配置及使用(Day_11)
世上没有从天而降的英雄,只有挺身而出的凡人. --致敬,那些在疫情中为我们挺身而出的人. 运行环境 JDK8 + IntelliJ IDEA 2018.3 优点: 使用连接池的最主要的优点是性能.创 ...
- JAVA基础语法-day02
五.变量.常量.作用域 静态量(类变量)只能写在类中,不能在外面,用static修饰. final修饰的变量为常量. 六.运算符 Math类是一个工具类,用于复杂数学运算,它的构造器被定义成priva ...