MovibleNet
MobileNet
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNetV2: Inverted Residuals and Linear Bottlenecks
背景
自从AlexNet在2012年赢得ImageNet大赛的冠军一来,卷积神经网络就在计算机视觉领域变得越来越流行,一个主要趋势就是为了提高准确率就要做更深和更复杂的网络模型,然而这样的模型在规模和速度方面显得捉襟见肘,在许多真实场景,比如机器人、自动驾驶、增强现实等识别任务及时地在一个计算力有限的平台上完成,这是我们的大模型的局限性所在。
目前针对这一问题的研究主要是从两个方面来进行的:
对复杂模型采取剪枝、量化、权重共享等方法,压缩模型得到小模型;
直接设计小模型进行训练。
MobileNet系列就属于第二种情况。
MobileNet V1核心在于使用深度可分离卷积取代了常规的卷积。
MobileNet V2在MobileNet V1的基础山进行了如下改进:
- 去掉了bottleneck的非线性激活层
- 使用Inverted residual block
深度可分离卷积
深度可分离卷积可分为两部分:
- 深度卷积(depthwise convolution)
- 逐点卷积(pointwise convolution)
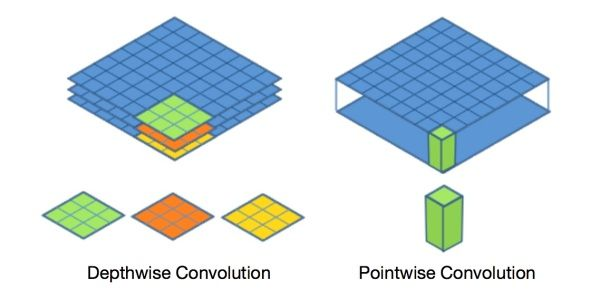
在进行深度卷积的时候,每个卷积核只关注单个通道的信息,而在逐点卷积中,每个卷积核可以联合多个通道的信息。以下我们通过一个具体的例子说明常规卷积与深度可分离卷积的区别。
以下讨论均基于padding=same的情况。
常规卷积操作如下图:
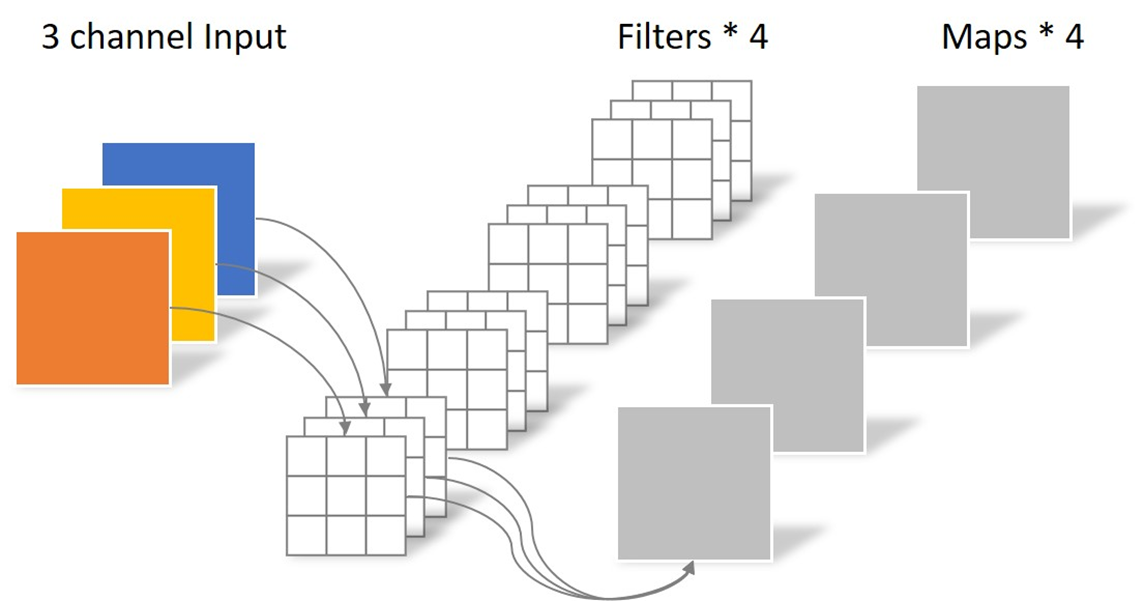
假设输入层为一个大小为64×64像素、三通道彩色图片。经过一个包含4个卷积核的卷积层,卷积核尺寸为3×3×3。最终则会输出4个Feature Map,且尺寸与输入图像尺寸相同。
深度可分离卷积操作中深度卷积如下图:
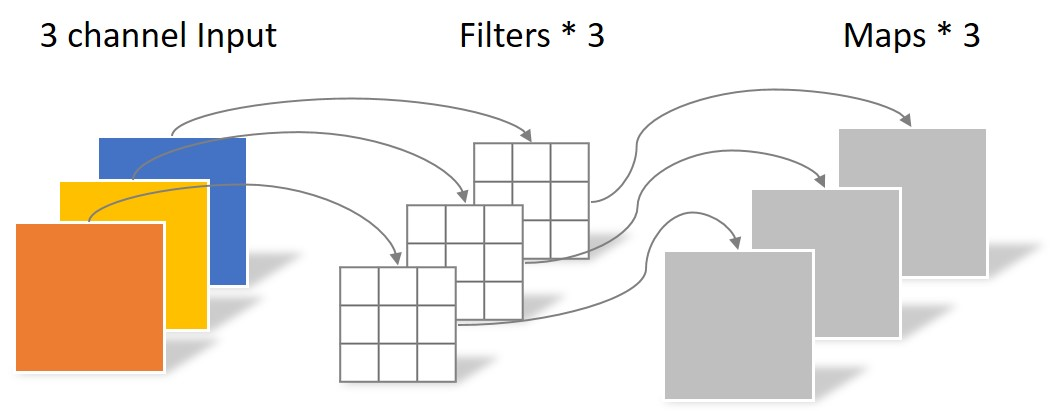
图中深度卷积使用的是3个尺寸为3×3的卷积核,经过该操作之后,输出的特征图尺寸为64×64×3。
深度可分离卷积操作中逐点卷积如下图:
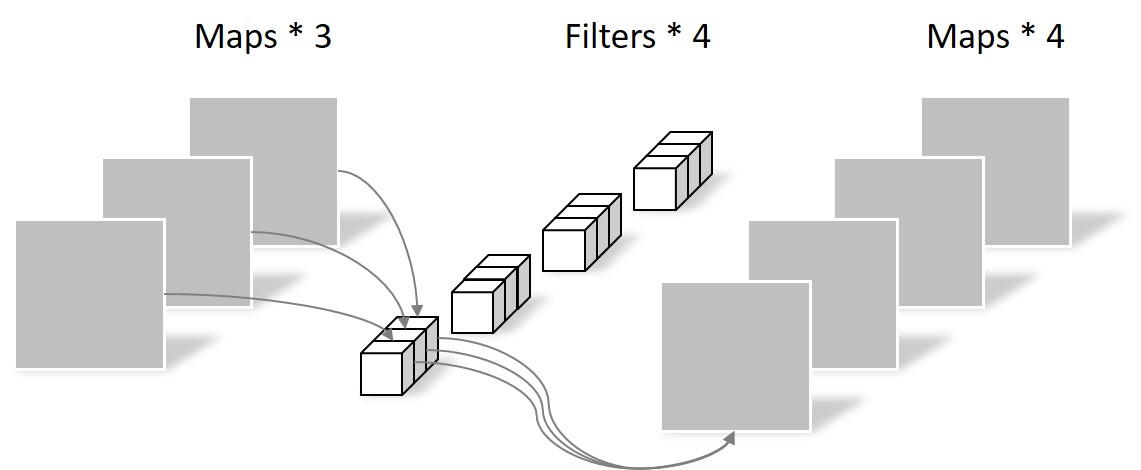
图中逐点卷积使用的是4个尺寸为1×1×3的卷积核,经过该操作之后,输出的特征图尺寸就为64×64×4。
那么可分离卷积相对于常规卷积计算量有多少降低呢?
假设输入图像尺寸为\(D_F * D_F * M\),标准卷积核尺寸为\(D_K * D_K * M * N\),其中\(M\)为通道数,\(N\)为卷积核个数。
采用标准卷积核进行卷积时,输出尺寸为\(D_F * D_F * N\),计算量为\(D_K * D_K * M * N * D_F * D_F\)。
采用可分离卷积的计算量为:
\(D_K * D_K * M * D_F * D_F + M * N * D_F * D_F\)
前半部分为尺寸为\(D_F * D_F * M\)的原图经过\(M\)个\(D_K * D_K\)的卷积核的计算量,后半部分为尺寸为\(D_F * D_F * M\)的特征图经过\(N\)个\(1 * 1 * M\)的卷积核的计算量。
则,可分离卷积相对常规卷积的计算量对比为:
\(\frac{D_K * D_K * M * D_F * D_F + M * N * D_F * D_F}{D_K * D_K * M * N * D_F * D_F} = \frac{1}{N} + \frac{1}{D_K^2}\)
卷积核的个数一般比较大,在此可以忽略,而最常使用的卷积核尺寸为\(3 * 3\),这样,可分离卷积相对常规卷积,计算量就降为了\(\frac{1}{9}\)。
V2版本相对于V1版本,主要是针对激活函数进行了思考,并且引入了残差连接。
使用如\(ReLU\)之类的激活函数能够给神经网络带来如下好处:1. 压缩模型参数,这可有效地使得模型计算量变小;2. 给神经网络引入非线性变化,使得模型能够拟合任意复杂的函数。
作者首先使用矩阵\(T\)将原始数据\(X_m\)映射到高维空间,之后使用\(ReLU\)函数将高维数据进行压缩,然后使用矩阵\(T\)的逆矩阵\(T^{-1}\)将高维数据映射回原空间,变化函数如下:
\[
Y = ReLU(T * X_m)
\\
X_m^{-1} = T^{-1} * Y
\]
下图展示了原始数据特征以及将原始数据映射到高维空间之后再映射回来之后的特征。

可见,将原始数据映射到的高维空间维度较少时,映射回来的数据与原来的数据差距很大,当高维空间维度大时,映射回来的数据与原数据差距要更小。作者认为当将数据映射的高维空间维度不足时,非线性激活函数的使用会使得数据特征大量丢失,因此在其设计的\(MovibleNet V2\)版中,在\(bottleneck\)构造块的最后使用了线性激活函数取代了非线性激活。除此之外,作者也并没有直接使用ReLU激活函数,而是使用了ReLU6激活函数,ReLU6激活函数相对于ReLU的区别就是,对于激活值加了一个6的上限。该操作可以使得模型的参数范围进行进一步压缩,以让模型存储和计算量进一步降低。
除了激活函数使用的变化之外,作者引入了残差连接。
我们知道,对于神经网络而言,更深更复杂的构造理论上总会带来更好的性能。但是,深度神经网络存在着梯度消失、梯度爆炸等的原因使得模型训练很困难,而残差连接就是针对该问题而进行设计的。
常规的残差块如下图:
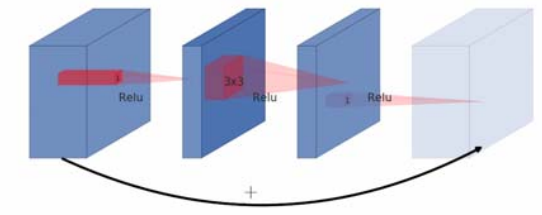
为了降低计算量,首先使用\(1*1\)的卷积核将原始数据特征维度进行降低,然后再通过常规卷积层,最后又使用\(1*1\)卷积核将特征进行升维,最后将前后特征进行相加。因为是先降维再升维的操作,该结构称为宽,窄,宽结构。
\(MobileNet V2\)使用的残差连接结构如下:
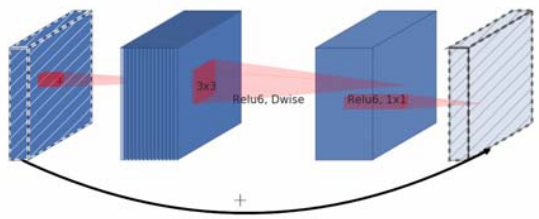
因为深度可分离卷积的存在已经使得模型的计算量降低,因此,作者认为,这里不需要将数据进行降维,取而代之的是,为了提高模型的性能,作者在这里使用\(1*1\)卷积核来先将数据进行升维,然后又进行可分离卷积操作之后,又使用\(1*1\)卷积核进行降维操作,最后,将前后特征进行相加。因为是先升维,再降维的操作,该结构称为窄,宽,窄的结构,作者将该构造结构称之为\(Inverted \ residual \ block\)。
\(MovibleNet \ V2\)的构造块如下图:
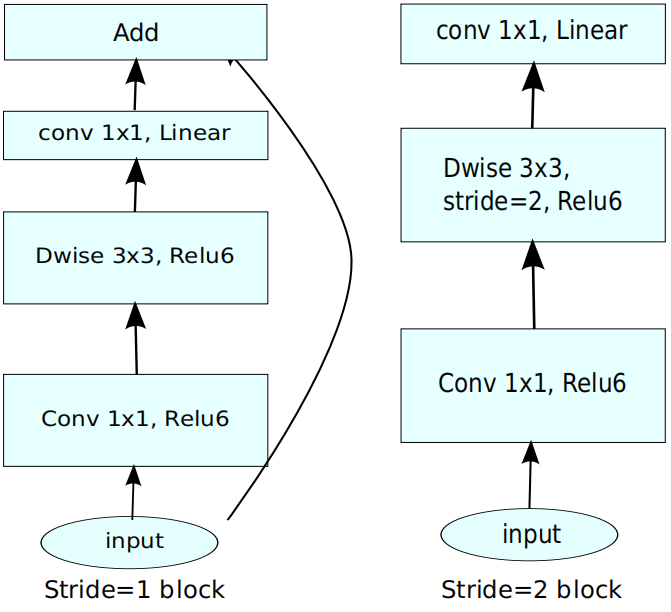
模型的配置如下:

MovibleNet的更多相关文章
随机推荐
- 详解k8s中的liveness和readiness的原理和区别
liveness与readiness的探针工作方式源码解析 liveness和readiness作为k8s的探针,可以对应用进行健康探测. 二者支持的探测方式相同.主要的探测方式支持http探测,执行 ...
- presto-mysql/elasticsearch6.0.0安装部署测试,异种数据源关联查询入门实践
本文简单记录一次实践使用过程,涉及presto-mysql,presto-elasticsearch,文中参数未做注释,请参考官方文档,希望能帮到大家 1 下载安装 presto-0.228 < ...
- kali linux 开启配置ssh服务
1. 一.配置SSH参数 修改sshd_config文件,命令为: vi /etc/ssh/sshd_config 将#PasswordAuthentication no的注释去掉,并且将NO修 ...
- Flask:Flask-script插件
Flask-Script插件扩展提供向Flask插入外部脚本的功能,包括一个开发用的服务器,一个定制的python shell,设置数据库的脚本,cronjobs,及其它运行在web应用之外的命令行任 ...
- Bash 通配符、正则表达式、扩展正则表达式
BASH中的通配符(wildcard) *:任意长度的任意字符. ?:任意单个字符 []:匹配范围 [^]:排除匹配范围 [:alnum:]:所有字母和数字 [:alpha:]:所有字母 [:digi ...
- 【CF696D】Legen...(AC自动机)(矩阵快速幂)
题目描述 Barney was hanging out with Nora for a while and now he thinks he may have feelings for her. Ba ...
- Windows Server 搭建企业无线认证(Radius认证方案)
认证协议介绍: 扩展认证协议EAP(Extensible Authentication Protocol) 是一个在无线网络或点对点连线中普遍使用的认证框架.它被定义在RFC 3748中,并且使RFC ...
- Cpython和Jython的对比介绍
CPython 当我们从Python官方网站下载并安装好Python 3.x后,我们就直接获得了一个官方版本的解释器:CPython.这个解释器是用C语言开发的,所以叫CPython.在命令行下运行p ...
- 《计算机网络 自顶向下方法》 第8章 计算机网络中的安全 Part2
SSL(使 TCP 连接安全) SSL(Secure Socket Layer),即安全套接字层,是对 TCP 的强化 HTTPS 使用 SSL,而 HTTP 不使用 SSL 通过采用机密性.数据完整 ...
- 微信小程序引入全局或公共样式
在开发的过程中,总会遇到很多可复用性的样式,为了代码更加的简洁和减少微不住道的文件体积,我抽取了一部分的公共样式,并全局引入,不知是否妥当,如有更好的想法,欢迎一起探讨 在app.wxss中引入 然后 ...