Elasticsearch学习笔记(六)核心概念和分片shard机制
一、核心概念
1、近实时(Near Realtime NRT)
(1)从写入数据到数据可以被搜索到有一个小延迟(大概1秒);
(2)基于es执行搜索和分析可以达到秒级
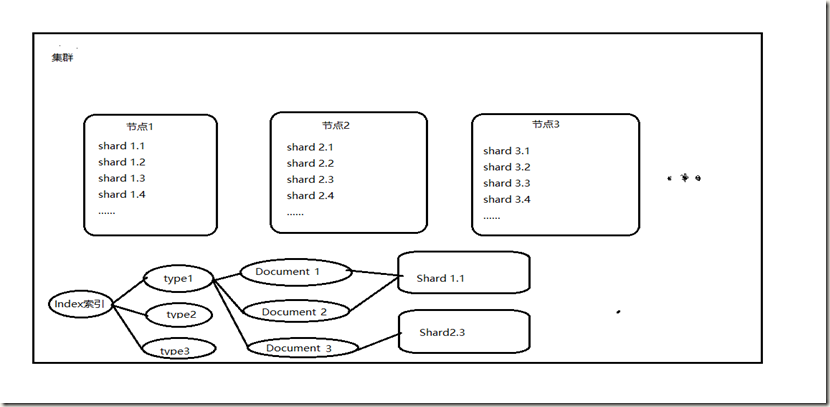
2、集群(Cluster)
一个集群下有多个节点。集群名称,默认是elasticsearch
3、节点(Node)
集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时 候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
节点通过配置集群名称加入指定的集群
4、索引(Index)
包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
5、类型(Type)
类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
6、文档和字段(Document 和 field)
文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
7、shard
单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard(一个index包含多个shard ),分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
shard分为:
(1)primary shard:主分片
(2)replica shard :备份分片,是primary shard的副本,负责容错,以及承担读请求负载
任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。增减节点时,shard会自动在nodes中负载均衡。
primary shard(建立索引时一次设置,不能修改,默认5个),
replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改(primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard )
primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
设置索引的primary shard 和replica shard 的数量
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
二、shard 机制
1、shard的负载均衡
2、master的选举
3、replica容错
primary shard宕机后,新master将某个replica shard提升为primary shard。重启宕机node,master copy replica到该node,使用原有的shard并同步宕机后的修改。原有的primary shard降级为replica shard
4、读写请求
Elasticsearch学习笔记(六)核心概念和分片shard机制的更多相关文章
- Elasticsearch学习之基本核心概念
在Elasticsearch中有许多术语和概念 1. 核心概念 Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包 ...
- Docker 学习笔记之 核心概念
Docker核心概念: Docker Daemon Docker Container Docker Registry Docker Client 通过rest API 和Docker Daemon进程 ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- java之jvm学习笔记六-十二(实践写自己的安全管理器)(jar包的代码认证和签名) (实践对jar包的代码签名) (策略文件)(策略和保护域) (访问控制器) (访问控制器的栈校验机制) (jvm基本结构)
java之jvm学习笔记六(实践写自己的安全管理器) 安全管理器SecurityManager里设计的内容实在是非常的庞大,它的核心方法就是checkPerssiom这个方法里又调用 AccessCo ...
- Elasticserach学习笔记-01基础概念
本文系本人根据官方文档的翻译,能力有限.水平一般,如果对想学习Elasticsearch的朋友有帮助,将是本人的莫大荣幸. 原文出处:https://www.elastic.co/guide/en/e ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- elasticsearch学习笔记--原理介绍
前言:上一篇中我们对ES有了一个比较大概的概念,知道它是什么,干什么用的,今天给大家主要讲一下他的工作原理 介绍:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户 ...
- Linux学习笔记(六) 进程管理
1.进程基础 当输入一个命令时,shell 会同时启动一个进程,这种任务与进程分离的方式是 Linux 系统上重要的概念 每个执行的任务都称为进程,在每个进程启动时,系统都会给它指定一个唯一的 ID, ...
- Docker:学习笔记(1)——基础概念
Docker:学习笔记(1)——基础概念 Docker是什么 软件开发后,我们需要在测试电脑.客户电脑.服务器安装运行,用户计算机的环境各不相同,所以需要进行各自的环境配置,耗时耗力.为了解决这个问题 ...
随机推荐
- Java基础(二)面向对象(上)
面向对象基础知识 面向对象是相对面向过程而言的 面向对象和面向过程都是一种思想 面向过程强调的是功能行为 面向对象将功能封装进对象,强调具备了功能的对象 面向对象是基于面向过程的 面向对象的特征: 封 ...
- 生成网上下载的EF项目对应的数据库
生成网上下载的EF项目对应的数据库 网上下载的用EF做的小项目,结果没有配有数据库的,用VS打开来看了一下,看到Migrations文件夹,应该可以用EF命令来生成这个数据库了 打开appsettin ...
- 每天学习一个Linux命令-目录
在工作中总会零零散散使用到各种Linux命令,从今天开始详细的学习一下linux常用命令,坚持每天一个命令,学习的主要参考资料为: 1.竹子-博客(https://www.cnblogs.com/pe ...
- [转]Kindeditor图片粘贴上传(chrome)
原文地址:https://www.cnblogs.com/jsper/p/7608004.html 首先要赞一下kindeditor,一个十分强大的国产开源web-editor组件. kindedit ...
- Windows server 2008普通用户不能远程登录问题
1.查登录权限 如果文件服务器没有为用户授权,那么用户自然就不能远程登录服务器系统了,为此笔者决定先仔细检查一下文件服务器系统是否为自己使用的登录账号,授予了远程登录权限.在进行这种检查时,笔者先是在 ...
- jenkins GitHub 自动触发
jenkins GitHub 自动触发 转载请注明出处: 转载自Bin's Blog: jenkins GitHub 自动触发( http://www.wenbin.cf/post/54/ ) 需要 ...
- 解决stackoverflow打开慢的问题
Stack Overflow是国外一个与程序相关的IT技术问答网站.类似于国内的segmentfault.程序员们对于这2个网站应该都不陌生.但是我们打开stackoverflow的时候,会发现打开速 ...
- CentOS安装和配置Mysql
1. Centos 默认的yum 是没有Mysql5.7 所以需要配置下,从官网获取最新的RPM包 在MySQL官网中下载YUM源rpm安装包:https://dev.mysql.com/downlo ...
- 解决JS(Vue)input[type='file'] change事件无法上传相同文件的问题
Html <input id="file" type="file" accept=".map" onchange="uplo ...
- 11.1 vue(2)
2018-11-1 19:41:00 2018年倒数第二个月! 越努力越幸运!!!永远不要高估自己! python视频块看完了!还有30天吧就结束了! 今天老师讲的vue 主要是看官网文档 贴上连接 ...