Python爬虫(四)——开封市58同城数据模型训练与检测
前文参考:
Python爬虫(二)——对开封市58同城出租房数据进行分析
Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析
数据的构建
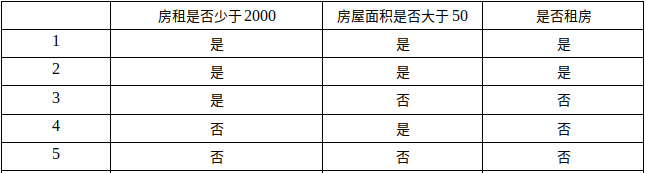
在这张表中我们可以发现这里有5个数据,这里有两个特征(房租是否少于2000,房屋面积是否大于50)来划分这5个出租房是否租借。
现在我们要做的就是是要根据第一个特征,第二个特征还是第三个特征来划分数据,进行分类。
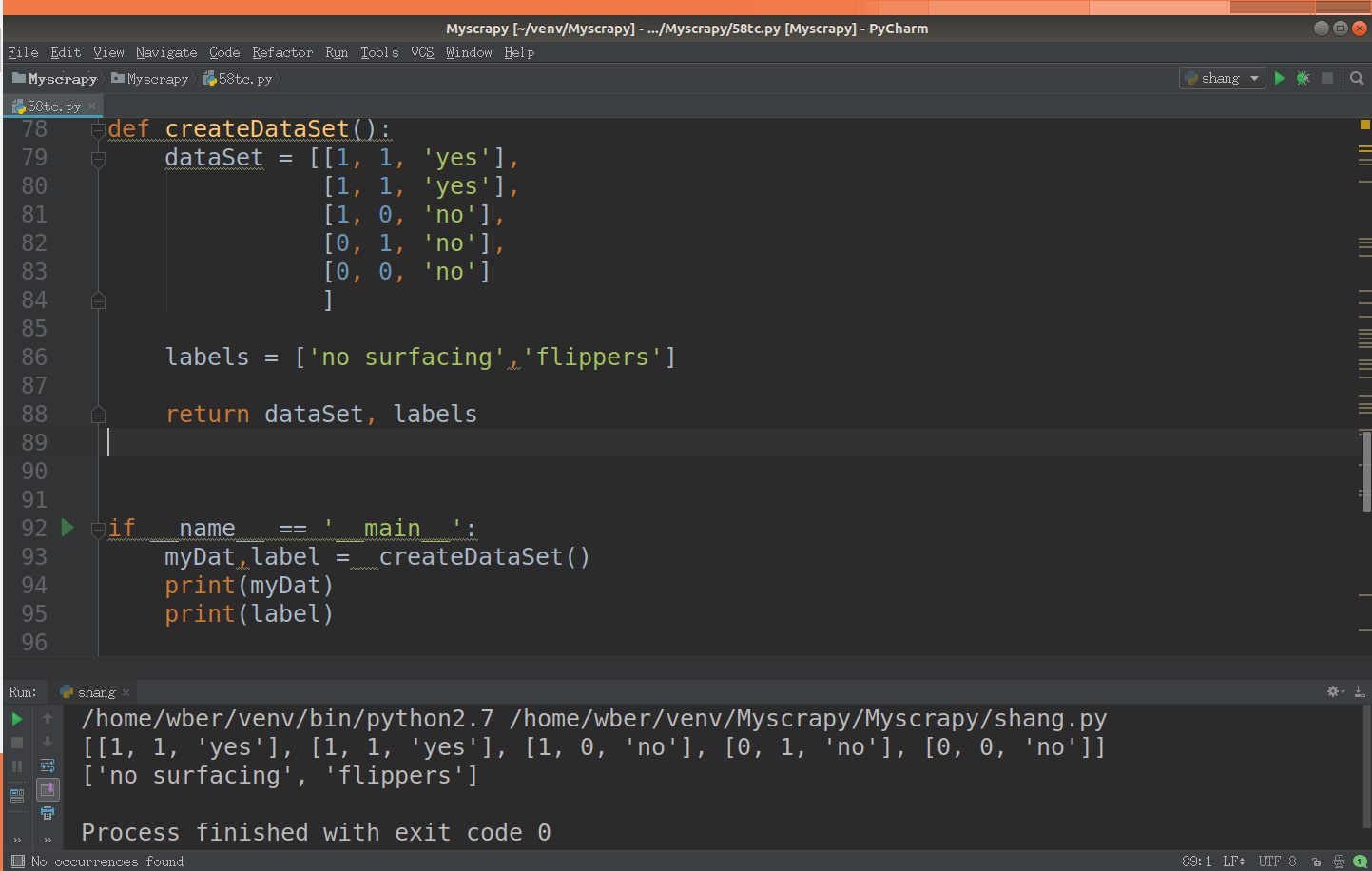
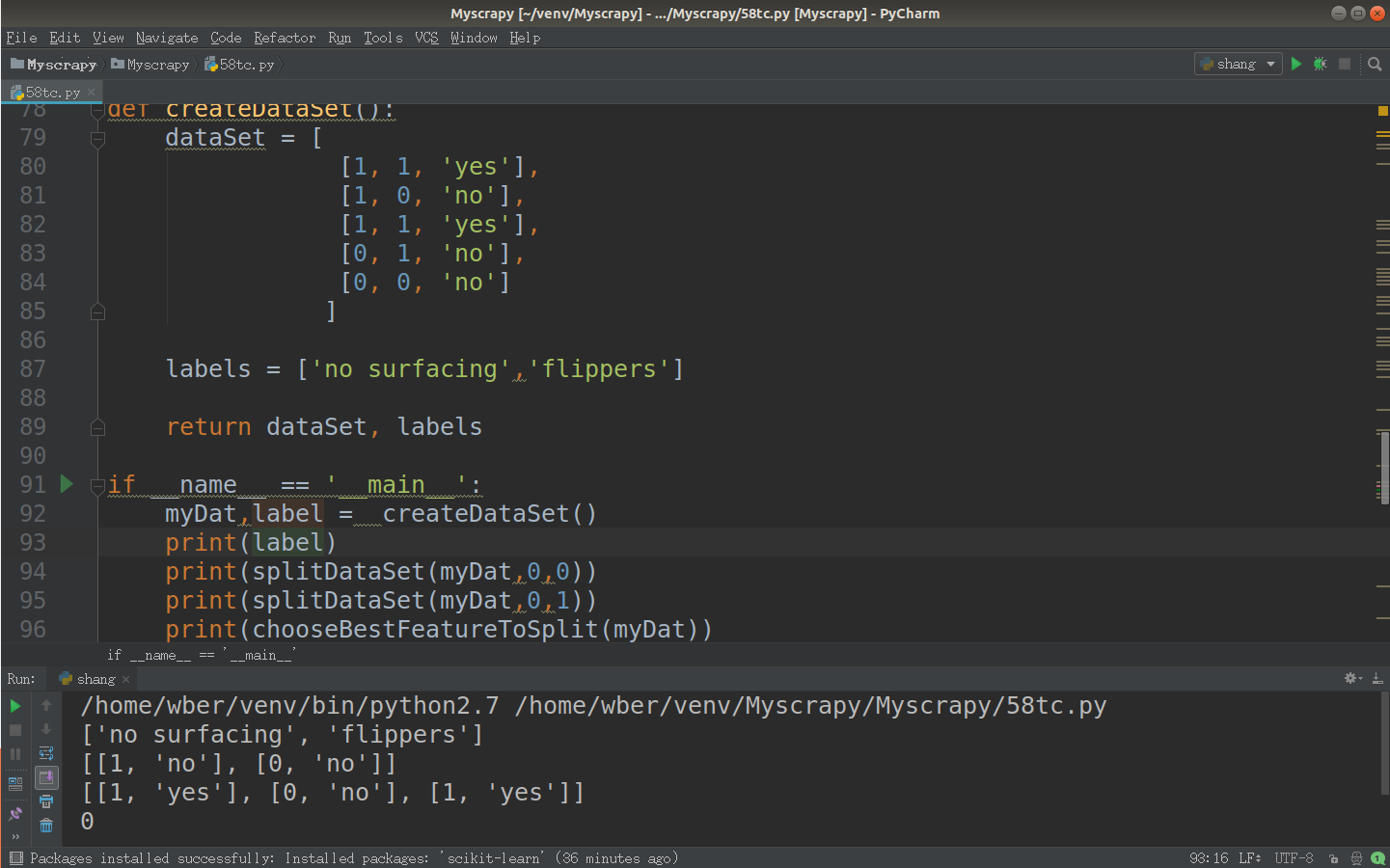
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 0, 'no']
] labels = ['no surfacing','flippers'] return dataSet, labels
计算给定数据的信息熵
根据信息论的方法找到最合适的特征来划分数据集。在这里,我们首先要计算所有类别的所有可能值的香农熵,根据香农熵来我们按照取最大信息增益的方法划分数据集。
以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。信息熵是用来衡量一个随机变量出现的期望值。如果信息的不确定性越大,熵的值也就越大,出现的各种情况也就越多。
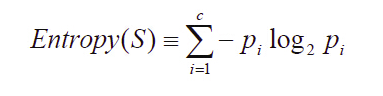
其中,S为所有事件集合,p为发生概率,c为特征总数。注意:熵是以2进制位的个数来度量编码长度的,因此熵的最大值是log2C。
信息增益(information gain)是指信息划分前后的熵的变化,也就是说由于使用这个属性分割样例而导致的期望熵降低。也就是说,信息增益就是原有信息熵与属性划分后信息熵(需要对划分后的信息熵取期望值)的差值,具体计算法如下:

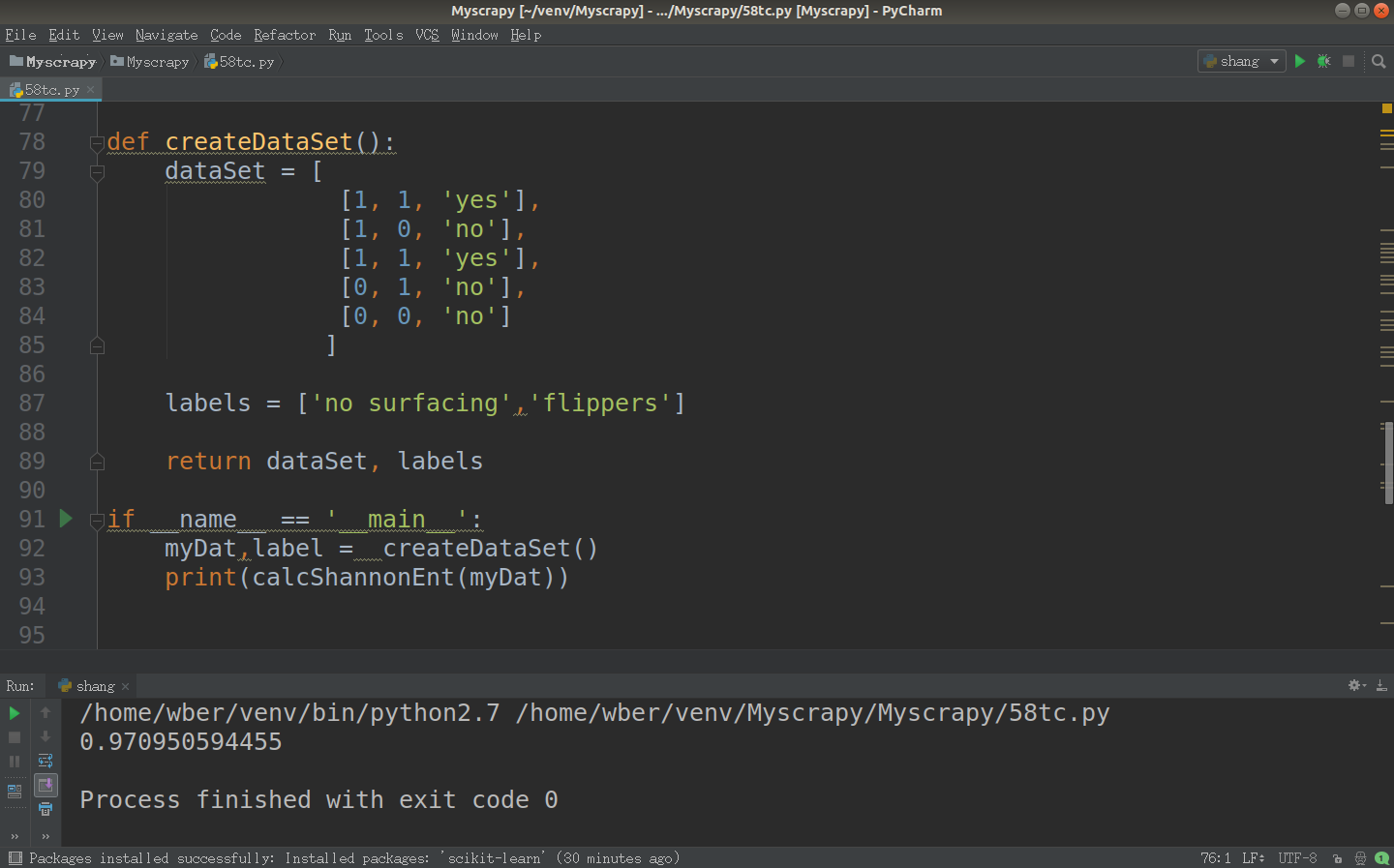
def calcShannonEnt(dataSet):
countDataSet = len(dataSet)
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
getshang = 0.0 for key in labelCounts:
prob = float(labelCounts[key])/countDataSet
getshang -= prob * log(prob,2) return getshang
划分数据集
在度量数据集的无序程度的时候,分类算法除了需要测量信息熵,还需要划分数据集,度量花费数据集的熵,以便判断当前是否正确的划分了数据集。
我们将对每个特征数据集划分的结果计算一次信息熵,然后判断按照那个特征划分数据集是最好的划分方式。
也就是说,我们依次选取我们数据集当中的所有特征作为我们划定的特征,然后计算选取该特征时的信息增益,当信息增益最大时我们就选取对应信息增益最大的特征作为我们分类的最佳特征。
dataSet = [
[1, 1, 'yes'],
[1, 0, 'no'],
[1, 1, 'yes'],
[0, 1, 'no'],
[0, 0, 'no']
]
在这个数据集当中有三个特征,就是每个样本的第一列和第二列,最后一列是它们所属的分类。
我们划分数据集是为了计算根据那个特征我们可以得到最大的信息增益,那么根据这个特征来划分数据就是最好的分类方法。
因此我们需要遍历每一个特征,然后计算按照这种划分方式得出的信息增益。信息增益是指数据集在划分数据前后信息的变化量。

计算信息增益
依次遍历每一个特征,在这里我们的特征只有两个,就是房租是否少于2000,房屋面积是否大于50。然后计算出根据每一个特征划分产生的数据集的熵,和初始的数据集的熵比较,我们找出和初始数据集差距最大的。那么这个特征就是我们划分时最合适的分类特征。
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain =0.0
bestFeature = -1 for i in range(numFeatures):
featList = [sample[i] for sample in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet) infoGain = baseEntropy - newEntropy if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i return bestFeature
数据检测
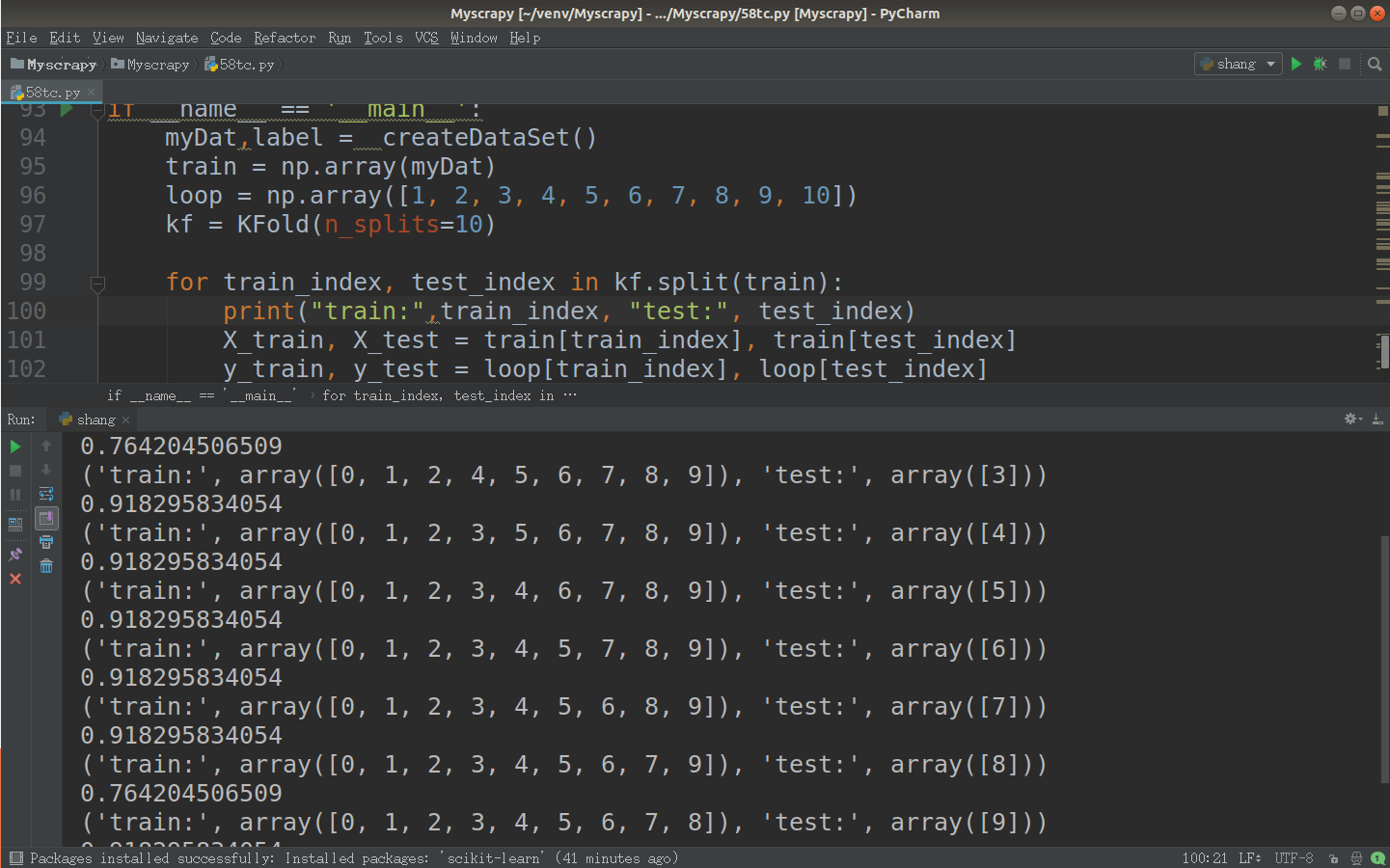
sklearn实现交叉验证十折交叉验证流程
将数据集随机地切分为S个互不相交的大小相同的子集
然后挑选其中S-1个子集作为训练集,训练模型,用剩下的一个子集作测试集,获得测试误差或者评测指标
将上面过程对所有可能的S种选择重复进行,即每次都是用不同的测试集
最后对S次实验所得的数据(测试误差或者评测指标)取均值。
train = np.array(myDat)
loop = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
kf = KFold(n_splits=10) for train_index, test_index in kf.split(train):
print("train:",train_index, "test:", test_index)
X_train, X_test = train[train_index], train[test_index]
y_train, y_test = loop[train_index], loop[test_index]
print(calcShannonEnt(train[train_index]))
Python爬虫(四)——开封市58同城数据模型训练与检测的更多相关文章
- Python爬虫(三)——开封市58同城出租房决策树构建
决策树框架: # coding=utf-8 import matplotlib.pyplot as plt decisionNode = dict(boxstyle=') leafNode = dic ...
- Python爬虫(一)——开封市58同城租房信息
代码: # coding=utf-8 import sys import csv import requests from bs4 import BeautifulSoup reload(sys) s ...
- Python爬虫(四)——豆瓣数据模型训练与检测
前文参考: Python爬虫(一)——豆瓣下图书信息 Python爬虫(二)——豆瓣图书决策树构建 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 在这张表中我们可以发现 ...
- 用Python写爬虫爬取58同城二手交易数据
爬了14W数据,存入Mongodb,用Charts库展示统计结果,这里展示一个示意 模块1 获取分类url列表 from bs4 import BeautifulSoup import request ...
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
- python3爬虫-爬取58同城上所有城市的租房信息
from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, dat ...
- Python爬虫(二)——对开封市58同城出租房数据进行分析
出租房面积(area) 出租房价格(price) 对比信息 代码 import matplotlib as mpl import matplotlib.pyplot as plt import pan ...
- python爬虫(四)_urllib2库的基本使用
本篇我们将开始学习如何进行网页抓取,更多内容请参考:python学习指南 urllib2库的基本使用 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地.在Python中有很 ...
- Python 爬虫四 基础案例-自动登陆github
GET&POST请求一般格式 爬取Github数据 GET&POST请求一般格式 很久之前在讲web框架的时候,曾经提到过一句话,在网络编程中“万物皆socket”.任何的网络通信归根 ...
随机推荐
- GO语言-基础语法:条件判断
1. IF判断(aa.txt内容:asdfgh.bb.txt内容:12345) package main import ( "io/ioutil" "fmt" ...
- J - Printer Queue 优先队列与队列
来源poj3125 The only printer in the computer science students' union is experiencing an extremely heav ...
- mysql 计算两点经纬度之间的直线距离(具体sql语句)
文章转载地址 http://blog.sina.com.cn/s/blog_7bbfd5fd01017d1e.html 新增sql语句具体实现 计算距离(单位 m)并排序 longitude 经度 l ...
- HTML load事件和DOMCOntentLoaded事件
JS高程 p14 “异步脚本一定会在页面的load事件前执行,但可能会在DOMContentLoaded事件触发之前或之后执行” 普通script标签会阻塞DOM的解析 DOMcontentLoa ...
- 网站favicon图标的显示问题
今天在微信开发者工具发现一个错误,说是找不到favicon.ico这个文件. 这个就是标签式浏览器显示在页面title前面的小图标,移动端也没什么用,所以一直没在意,今天有空就研究了一下,发现还是有点 ...
- 日志系统的 ELK 的搭建
https://www.cnblogs.com/yuhuLin/p/7018858.html 快速搭建ELK日志分析系统 一.ELK搭建篇 官网地址:https://www.elastic.co/cn ...
- Java编程基础篇第四章
循环结构 循环结构的分类 for循环,while循环,do...while()循环 for循环 注意事项: a:判断条件语句无论简单还是复杂结果是boolean类型 b:循环体语句如果是一条语句,大括 ...
- vb中的除法
“\”:在Integer类型中,如果商带小数,则直接舍去小数部分,只保留整数部分.“/”:在Integer类型中,如果商带小数,则把小数部分以0.5为界限,小数部分大于0.5,则返回的整数部分+1:如 ...
- F#周报2019年第2期
新闻 Rider上的拼写助手,对未使用引用的代码分析及更多F#相关特性的更新 .NET开源革命开始 ML.NET 0.9发布记录 测试驱动的集成开发环境 Giraffe在GitHub上超过了1000个 ...
- Python------excel读、写、拷贝
#-----------------------读excel-----------------#1 打开方式 索引.名字#2 获取行数据 sheet.row_values(0):获取某行第n到m列(n ...