标注-隐马尔可夫模型HMM的探究
1.1 定义
1.2 观测序列生成过程
1.3 HMM的三个问题
2 概率计算算法
2.1 直接计算算法
2.2 前向算法forward algorithm
2.3 后向算法
2.4 一些概率与期望值的计算
3 学习算法
3.1 监督学习
3.2 非监督学习——Baum-Welch算法
3.3 Baum-Welch模型参数估计公式
4 预测算法
4.1 近似算法
4.2 维特比算法Viterbi algorithm
隐马尔可夫模型(hidden Markov model,HMM)是可用于标注问题的统计学习模型,描述由隐藏马尔科夫链随机生成的观测序列的过程,属于生成模型。在语音识别,自然语言处理,生物信息,模式识别有广泛的应用。
1 HMM基本概念
1.1 定义
马尔可夫链的定义:随机过程中出现的字符,每个字符出现的概率不是独立的而是依赖于此前的状态,称为——。与之相对应的是独立链,即每个字符出现的概率是独立的。
参考链接:马尔可夫和马尔可夫链
HMM是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列称为状态序列(state sequence)。每个状态生成一个观测,由此产生的观测的随机序列称为观测序列(observation sequence)。序列的每个位置可以看做是一个时刻。
很多术语:
设Q是所有可能状态的集合,V是所有可能观测的集合。Q={q1,q2,…,qN},V={v1,v2,…,vM}, N是可能的状态数,M是可能的观测数。
I是长度为T的状态序列,O是对应的观测序列,I=(i1,i2,…,iT),O=(ν1,ν2,…,νT)
A是状态转移概率矩阵,A=[aij]NXN,αij=P(it+1=qj|it=qi),i=1,2,..,N;j=1,2,..N,表明时刻t处于状态qi的条件下t+1转移状态的概率qj。
更好的理解状态转移概率:知乎PHD-Tasi的回答

B是观测概率矩阵,B=[bj(k)]NXM,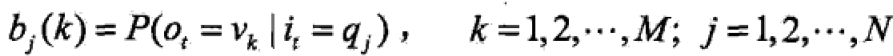 表明时刻t处于状态qj条件下生成的观测νk的概率。
表明时刻t处于状态qj条件下生成的观测νk的概率。
π是初始状态向量,π=(πi),其中,πi=P(i1=qi),i=1,2…,N表示时刻t=1时处于状态qi的概率。
HMM由初始状态概率向量π,状态转移概率矩阵A和观测概率矩阵B决定,π和A决定状态序列,B决定观测序列,因此HMM用λ的三元符号表示为:λ=(A,B,π),称为HMM的三要素。
从定义出发,发现HMM作了两个基本假设:
- 齐次马尔可夫假设:隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关。
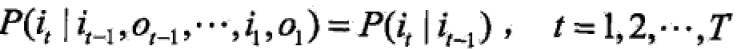
- 观测独立性假设:假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。
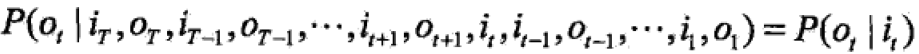
HMM可用于标注,这时状态对应着标记,标注问题是给定观测的序列与其对应的标记序列。假设标注问题的数据由HMM生成,这样可用HMM的学习与预测算法进行标注。
1.2 观测序列生成过程
算法:

1.3 HMM的三个问题
- 概率计算的问题:给定模型λ=(A,B,π)和观测序列O=(o1,o2,…,ot),计算在模型λ下观测序列O出现的概率P(O|λ)。
- 学习问题:已知观测序列O=(o1,o2,…,oT),估计模型λ=(A,B,π)参数,使得在该模型下观测序列的概率P(O|λ)最大,即用极大似然估计方法估计参数。
- 预测问题:也称解码(decoding),已知模型λ=(A,B,π)和观测序列O,求对给定观测序列条件概率P(I|O)最大的状态序列I。即给定观测序列求最有可能的对应的状态序列。
2 概率计算算法
计算观测序列的概率的算法。
2.1 直接计算算法
给定模型λ=(A,B,π)和观测序列O=(o1,o2,…oT),计算观测序列O出现的概率P(O|λ)。最直接的方法是按照概率公式直接计算。通过列举所有可能的长度为T的状态序列I=(i1,i2,…,iT),求各个状态序列I与观测序列O的联合概率P(O,I|λ),然后对所有可能的状态序列求和(边缘概率)得到P(O|λ)。
状态序列I的概率是: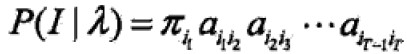
对固定状态序列I,观测序列O的概率是:
O,I同时出现的联合概率为: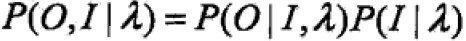

然后对所有可能的状态I求和得到要求的概率:
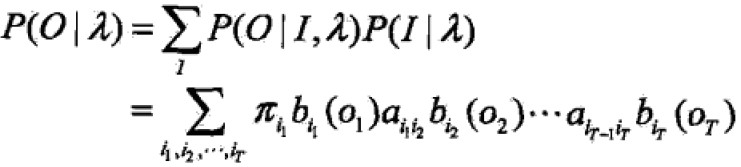
但是计算量极大,是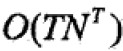 阶的。
阶的。
2.2 前向算法forward algorithm
前向概率:给定HMM模型λ,定义到时刻t部分观测序列为o1,o2,…,oT且状态为qi的概率为——
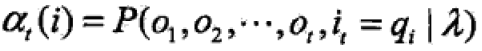
可以递推的求前向概率及观测概率P(O|λ)。
算法:


步骤1中,初始化前向概率,是初始时刻的状态i1=qi和观测o1的联合概率;
步骤2中,是前向概率的递推公式,计算到时刻t+1部分观测序列为o1,o2,…,ot+1且时刻t+1处于状态qi的前向概率;
步骤3中,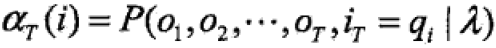 ,所有求和,这里和上面直接求解的加和一个意思。
,所有求和,这里和上面直接求解的加和一个意思。
2.3 后向算法
后向概率:给定HMM的λ,定义时刻t状态为qi的条件下,从t+1到T的部分观测序列为ot+1,… ,oT,称为——
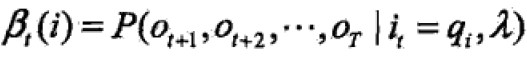
同样用递推的方法来求。
算法:

因为前向算法和后向算法思路是一致的,所以统一写成:
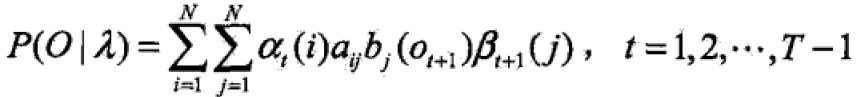
2.4 一些概率与期望值的计算
利用前向,后向概率可以得到单个状态和两个状态概率的计算公式。
- 给定模型λ和观测O,在时刻t处于状态qi的概率:

由前向概率可得:
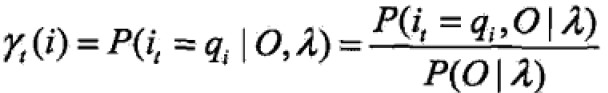
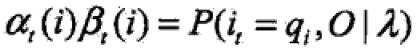
于是,
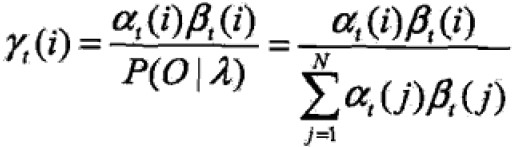
- 给定模型λ和观测O,在时刻t处于状态qi且在时刻t+1处于状态qj的概率为:
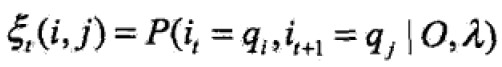
由前向后向概率可得:

而

因此,
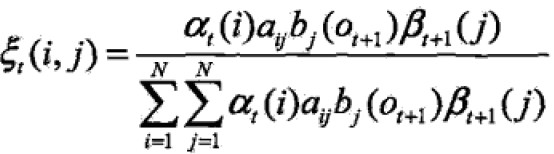
- 将1,2结合可对各个时刻t求和,得到一些有用的期望值
- 观测O下状态i出现的期望值:
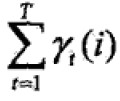 ;
; - 观测O下状态i转移的期望值:
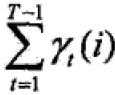 ;
; - 观测O下状态i转移到j的期望值:
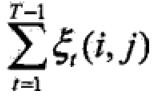
3 学习算法
根据训练数据是包括观测序列和对应状态序列还是只有观测序列分为监督学和非监督学习实现。
3.1 监督学习
假设已知训练数据包含S个长度相同的观测序列和对应的状态序列{(O1,I1),(O2,I2),……,(Os,Is)},那么就可以利用极大似然估计来估计HMM的参数。具体方法如下,
- 转移概率aij的估计
设样本中时刻t处于状态i,时刻t+1转移到状态j的频数为Aij,那么转移状态概率估计为
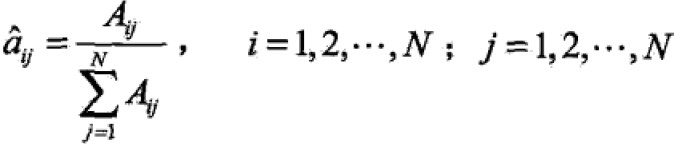
- 观测概率bj(k)的估计
设样本中状态为j并观测为k的频数为Bjk,那么状态为j观测为k的概率为估计为

- 初始状态概率πi的估计πi hat 为S个样本中初始状态为qi的频率
由于监督学习的算法需要训练数据,而人工标注的代价很大,所以有时候需要非监督学习的方法,如下节。
3.2 非监督学习——Baum-Welch算法
假设给定训练数据只包含S个,长度为T的观测序列{O1,O2,…,Os}而没对应的状态序列,目标是学习HMM的λ=(A,B,π)的参数。将观测序列看做测试数据O,状态序列数据看做不可观测的隐数据I,实际上HMM是一个含有隐变量的概率模型: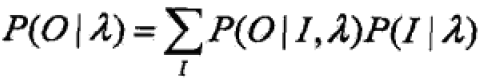 可以由EM算法实现。
可以由EM算法实现。
- 确定完全数据的对数似然函数
所有观测数据写成O=(o1,o2,…,oT),所有隐数据写成I=(i1,i2,…,iT),完全数据是(O,I)=(o1,o2,…,oT,i1,i2,…,iT),完全数据的对数似然函数是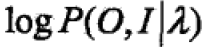 。
。 - EM算法的E步:求Q函数
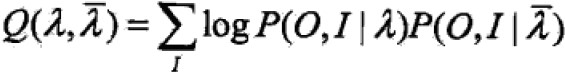
其中,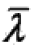 是HMM当前参数的估计值,λ是要极大化的HMM参数。
是HMM当前参数的估计值,λ是要极大化的HMM参数。
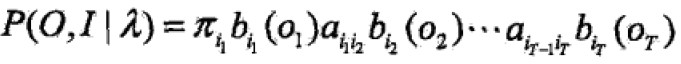
那么Q函数可化为:
 求和是因为对所有序列总长度为T的训练数据上进行的。
求和是因为对所有序列总长度为T的训练数据上进行的。 - EM算法的M步:极大化Q函数求模型参数A,B,π
观察Q函数最后的化简结果可发现,三个参数分别单独出现在三项中,故只需对三项分别极大化。
第一项:
 ,πi的约束条件是
,πi的约束条件是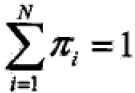 ,利用拉格朗日乘数法,写出拉格朗日函数:
,利用拉格朗日乘数法,写出拉格朗日函数:
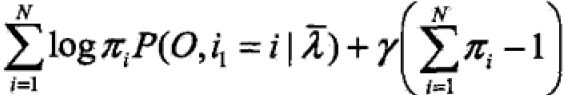 求偏导并令结果为0,得
求偏导并令结果为0,得
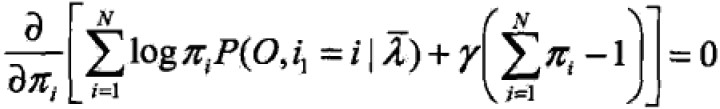 ==>
==>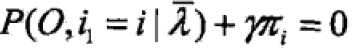
对i求和,得到γ,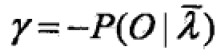
回代得到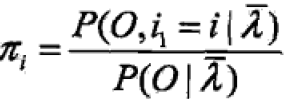 ;
;
第二项:
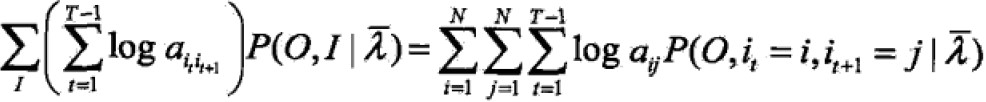 ,类似第一项约束条件
,类似第一项约束条件 ,利用拉格朗日乘数法求得:
,利用拉格朗日乘数法求得:
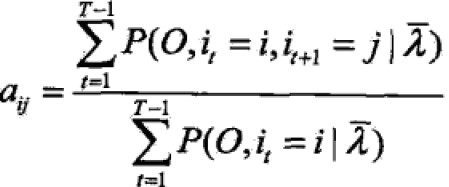
第三项:
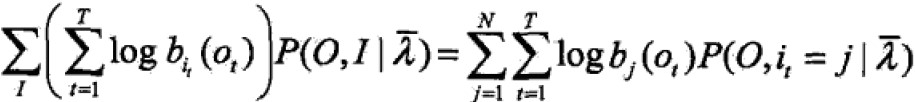 ,约束条件
,约束条件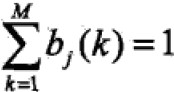 ,利用拉格朗日乘数法,得到:
,利用拉格朗日乘数法,得到:
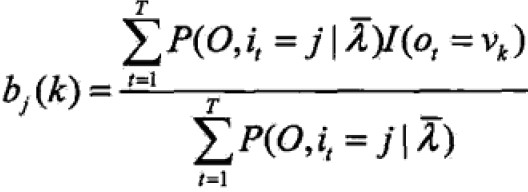
注意:只有在ot=νk时,bj(ot)对bj(k)的偏导才不为0,以I(ot=νk)表示。
3.3 Baum-Welch模型参数估计公式
三个公式: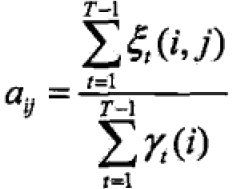 ;
;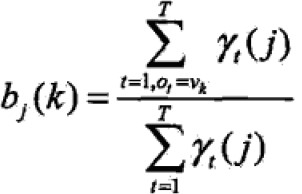 ;
; ;
;
BW算法:


4 预测算法
这是HMM最后一个问题:已知模型λ=(A,B,π)和观测序列O,求对给定观测序列条件概率P(I|O)最大的状态序列I。即给定观测序列求最有可能的对应的状态序列。
4.1 近似算法
思想是:在每个时刻t选择在该时刻最有可能出现的状态it从而得到一个状态序列 ,将它作为预测结果。
,将它作为预测结果。
给定HMM的λ和观测序列O,在此时刻t处于状态qi的概率为:
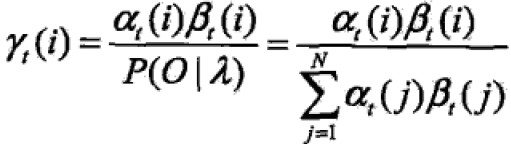
每一时刻最有可能的状态是 ,从而得到状态序列I。
,从而得到状态序列I。
近似算法的优点是计算简单,缺点是不能保证预测的状态序列整体上是最有可能的状态序列,因为预测的状态序列可能实际有不发生的部分。此方法得到的序列有可能存在转移概率为0的相邻状态。
4.2 维特比算法Viterbi algorithm
实际上是运用动态规划(dynamic programming)求解HMM问题。即动态规划求概率最大路径(最优路径)。这时一条路径对应一个状态序列。
什么是动态规划
根据动态规划原理,最优路径特性:时刻t通过的结点到最终结点时,对于所有其他可能的路径来说一定是最优的,如果不是,那么则出现另外一条最优的,与假设本路径最优矛盾,因此,我们只需,从时刻t=1开始,递推的计算在时刻t状态为i的各条部分路径的最大概率,直到得到t=T状态为i的各条路径的最大概率。时刻t=T的最大概率即为最优路径的概率P,最优路径的终结点iT同时得到。为了找到最优路径的各个结点,从iT开始,由后向前逐步求得结点得到最优路径I, ,这就是Viterbi算法。
,这就是Viterbi算法。
定义在时刻t状态为i的所有单个路径(i1,i2,…,iT)中概率最大值为: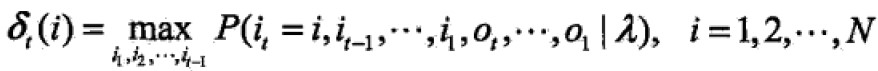
可得变量δ的递推公式:
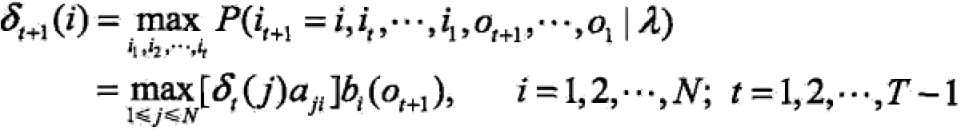
时刻t状态为i的所有单个路径概率最大的路径中第t-1个结点为: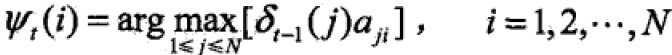
Viterbi 算法:
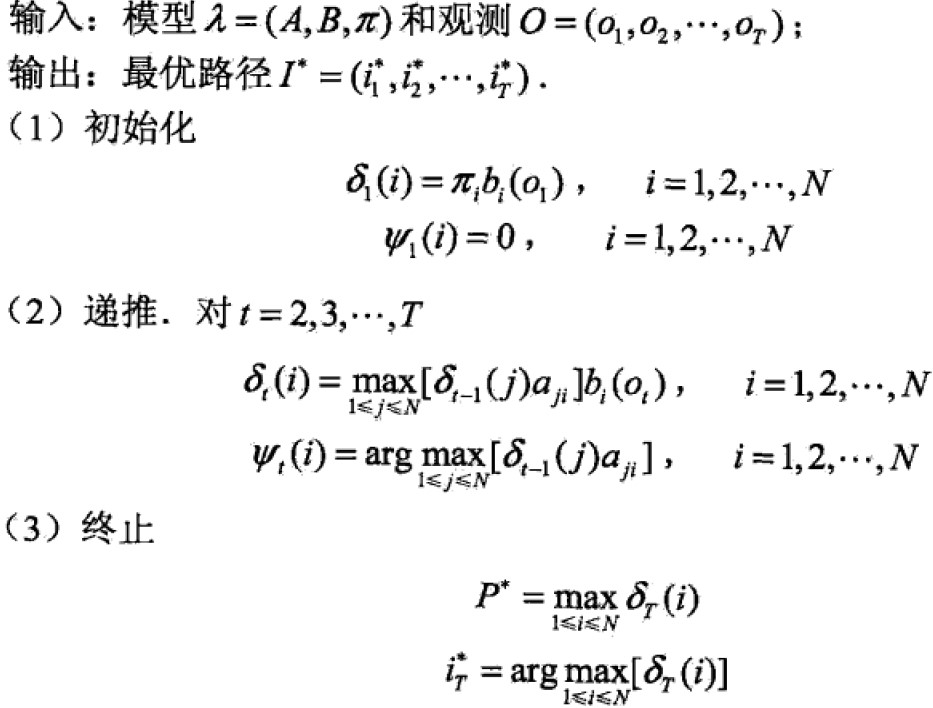

标注-隐马尔可夫模型HMM的探究的更多相关文章
- 隐马尔可夫模型HMM
隐马尔可夫模型HMM的探究 1 HMM基本概念1.1 定义1.2 观测序列生成过程1.3 HMM的三个问题2 概率计算算法2.1 直接计算算法2.2 前向算法forward algorithm2.3 ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 猪猪的机器学习笔记(十七)隐马尔科夫模型HMM
隐马尔科夫模型HMM 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十七次课在线笔记.隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来 ...
- 机器学习之隐马尔科夫模型HMM(六)
摘要 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔科夫过程.其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步 ...
- 隐马尔科夫模型 HMM(Hidden Markov Model)
本科阶段学了三四遍的HMM,机器学习课,自然语言处理课,中文信息处理课:如今学研究生的自然语言处理,又碰见了这个老熟人: 虽多次碰到,但总觉得一知半解,对其了解不够全面,借着这次的机会,我想要直接搞定 ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(一)HMM模型
隐马尔科夫模型HMM(一)HMM模型基础 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
随机推荐
- LeetCode - 627. Swap Salary
Given a table salary, such as the one below, that has m=male and f=female values. Swap all f and m v ...
- Mac 系统安装 oh my zsh
先来张图感受一下: 安装oh my zsh: 1.克隆这个项目到本地(前提是你得有装git) git clone git://github.com/robbyrussell/oh-my-zsh.git ...
- 并行执行 Job - 每天5分钟玩转 Docker 容器技术(134)
有时,我们希望能同时运行多个 Pod,提高 Job 的执行效率.这个可以通过 parallelism 设置. 这里我们将并行的 Pod 数量设置为 2,实践一下: Job 一共启动了两个 Pod,而且 ...
- 5、flask之信号和mateclass元类
本篇导航: flask实例化参数 信号 metaclass元类解析 一.flask实例化参数 instance_path和instance_relative_config是配合来用的:这两个参数是用来 ...
- Java经典编程题50道之二十七
求100之内的素数. public class Example27 { public static void main(String[] args) { prime(); } ...
- IE兼容swiper
swiper3能完美运用在移动端,但是运用在PC端,特别是IE浏览器上不能兼容,没有效果,要使IE兼容Swiper的话必须使用swiper2,也就是idangerous.swiper.js, 下载地址 ...
- JS原生Ajax&Jquery的Ajax技术&Json
1.介绍Ajax Ajax = 异步 JavaScript 和 XML Ajax是一种创建快速动态网页的技术 通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意味着可以不用整个 ...
- java线程优先级
java的线程优先级分为1-10 这10个等级 1为最强,最优先 10为最弱 如果大于10或者小于1则会抛异常 源代码为: public final void setPriority(int newP ...
- hql语句中的select字句和from 字句
package com.imooc.model; import java.util.List; import java.util.Map; import org.hibernate.Query; im ...
- ./init的含义
.代表当前目录,./后往往会跟上要运行的脚本文件.相关的例子,..代表上一级目录.