hbase 预分区与自动分区
我们知道,HBASE在创建表的时候,会自动为表分配一个Region,
当一个Region过大达到默认的阈值时(默认10GB大小),HBase中该Region将会进行split,分裂为2个Region,以此类推。
表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。
所以,HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。
假设我们初始给它10个Region,那么导入大量数据的时候,就会均衡到10个里面,显然比1个Region要好很多。
可是我们应该创建多少个Region呢?显然没有具体答案,要结合业务,根据表的rowkey进行设计。
一.强制拆分
预分区方法:
1.hbase shell 预分区
建立分区前,要先了解表的rowkey格式,rowkey为:两位随机数+时间戳+客户id
两位随机数的范围从00-99,划分范围:小于10,10-20,20-30,30-40,40-50,50-60,60-70,70-80,90+
hbase(main):001:0> create 'log1', 'cf1', SPLITS => ['10','20','30','40','50','60','70','80','90']
启动webUI
vi hbase-site.xml
添加
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
浏览器中:
http://h201:60010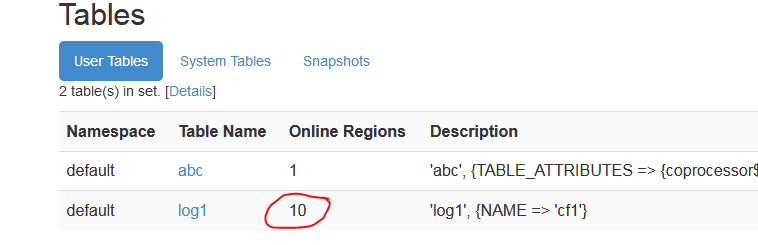
通过配置文件加载
[hadoop@h201 ~]$ cat rs.txt
10
20
30
40
50
60
70
80
90
hbase(main):003:0> create 'log2', 'cf1', SPLITS_FILE =>'/home/hadoop/rs.txt'
2.HBASE API 预分区
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.util.Bytes; public class Cp {
public static void main(String[] args) {
HBaseConfiguration config = new HBaseConfiguration();
config.set("hbase.zookeeper.quorum", "h201,h202,h203");
String tablename = new String("ctest1");
try{
HBaseAdmin admin = new HBaseAdmin(config);
if (admin.tableExists(tablename)) {
admin.disableTable(tablename);
admin.deleteTable(tablename);
} HTableDescriptor tableDesc = new HTableDescriptor(tablename);
tableDesc.addFamily(new HColumnDescriptor("cf1")); byte[][] splitKeys = {
Bytes.toBytes("10"),
Bytes.toBytes("20"),
Bytes.toBytes("30")
}; admin.createTable(tableDesc, splitKeys);
admin.close();
}catch(IOException e) {
e.printStackTrace();
}
}
}
验证:
webUI查看
ctest1有4个 预分区
====================================================
二.自动拆分(Auto splitting)
1.
0.94 版本之前采用的是 ConstantSizeRegionSplitPolicy 策略。
这个策略非常简单,从名字上就可以看出这个策 略就是按照固定大小来拆分Region。它唯一用到的参数是: hbase.hregion.max.filesize, 默认值是 10G, 也就是当 Region 的大小达到 10G 的时候, 会自动拆分成两个 Region.
2.
0.94 版本之后,有了 IncreasingToUpperBoundRegionSplitPolicy 策略。并且默认使用的这种策略。这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。
这种策略使用的最大store file size依据 Min(R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”),R代表同一台Region Server节点上的region的个数。比如,在默认memstore flush size为128MB且默认的max store size为10G时。(R为region的个数)
第一次拆分大小为:min(10G,1*1*128M)=128M
第二次拆分大小为:min(10G,3*3*128M)=1152M
第三次拆分大小为:min(10G,5*5*128M)=3200M
第四次拆分大小为:min(10G,7*7*128M)=6272M
第五次拆分大小为:min(10G,9*9*128M)=10G
第五次拆分大小为:min(10G,11*11*128M)=10G
可以看到,只有在第四次之后的拆分大小才为10G
hbase 预分区与自动分区的更多相关文章
- Hive静态分区和动态分区
一.静态分区 1.创建分区表 hive (default)> create table order_mulit_partition( > order_number string, > ...
- Hbase预分区种子生成
提前生成Hbase预分区种子,在创建Hbase表时也进行相应的预分区,同时设置预分区的个数,预分区的范围对应Hbase监控页面的Region Server的start key与End key,从而使数 ...
- 大数据量场景下storm自定义分组与Hbase预分区完美结合大幅度节省内存空间
前言:在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗.大量的预分 ...
- storm自定义分组与Hbase预分区结合节省内存消耗
Hbas预分区 在系统中向hbase中插入数据时,常常通过设置region的预分区来防止大数据量插入的热点问题,提高数据插入的效率,同时可以减少当数据猛增时由于Region split带来的资源消耗. ...
- fedora22切换用户windows分区不能自动挂载
新建立一个用户后,然后登陆后,再次登出,登陆原来的账户windows分区不能自动挂载
- ubuntu server下建立分区表/分区/格式化/自动挂载(转)
link:http://www.thxopen.com/linux/2014/03/30/Linux_parted.html 流程为:新建分区-->格式化分区-->挂载分区 首先弄明白分区 ...
- MySql自动分区
自动分区需要开启MySql中的事件调度器,可以通过如下命令查看是否开启了调度器 show variables like '%scheduler%'; 如果没开启的话通过如下指令开启 ; 1.创建一个分 ...
- 为已有表快速创建自动分区和Long类型like 的方法-Oracle 11G
对上一篇文章进行实际的运用.在工作中遇到有一张大表(五千万条数据),在开始的时候忘记了创建自动分区,导致现在使用非常不方便,查询的速度非常的满,所以就准备重新的分区表,最原始方法是先创建新的分区表,然 ...
- Oracle12c:创建主分区、子分区,实现自动分区插入效果
单表自动单个分区字段使用方式,请参考:<Oracle12c:自动分区表> 两个分区字段时,必须一个主分区字段和一个子分区字段构成(以下代码测试是在oracle12.1版本): create ...
随机推荐
- 11个不常被提及的JavaScript小技巧
这次我们主要来分享11个在日常教程中不常被提及的JavaScript小技巧,他们往往在我们的日常工作中经常出现,但是我们又很容易忽略. 1.过滤唯一值 Set类型是在 ES6中新增的,它类似于数组,但 ...
- idea解决Maven jar依赖冲突(四)
首先点击右侧的MavenProjects打开以下界面: 这个界面是maven的命令界面: 点击这个图标会进入如下界面: 左上角可以缩放,点击线可以取消冲突依赖,红色线为冲突依赖. 上图为无依赖冲突的s ...
- Python之路【第五篇】:Python基础之文件处理
阅读目录 一.文件操作 1.介绍 计算机系统分为:计算机硬件,操作系统,应用程序三部分. 我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操 ...
- Storm入门(十二)Twitter Storm: DRPC简介
作者: xumingming | 可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明网址: http://xumingming.sinaapp.com/756/twitter-stor ...
- aspnetcore.webapi实战k8s健康探测机制 - kubernetes
1.浅析k8s两种健康检查机制 Liveness k8s通过liveness来探测微服务的存活性,判断什么时候该重启容器实现自愈.比如访问 Web 服务器时显示 500 内部错误,可能是系统超载,也可 ...
- iOS可视化动态绘制连通图(Swift版)
上篇博客<iOS可视化动态绘制八种排序过程>可视化了一下一些排序的过程,本篇博客就来聊聊图的东西.在之前的博客中详细的讲过图的相关内容,比如<图的物理存储结构与深搜.广搜>.当 ...
- Android开发:APK的反编译(获取代码和资源文件)
一.反编译工具: 1.APKTool: APKTool是由GOOGLE提供的APK编译工具,能够完成反编译及回编译apk的工作.同时,它也有着安装反编译系统apk所需要的framework-res框架 ...
- Python编程Day1——计算机组成与操作系统
一..计算机基础 二.编程与编程的目的 1.什么是语言? 一种事物与另外一种事物沟通的介质 编程语言是程序员与计算机沟通的介质 2.什么是编程? 程序员把自己想要让计算机做的事用编程语言表达出来,编程 ...
- numpy操作
python中使用了numpy的一些操作,特此记录下来: 生成矩阵,替换值 import numpy as np # 生成一行10列的矩阵 dataset = np.zeros((1, 10)) # ...
- Python3+Flask+uwsgi部署
python3 按照常规的方式安装即可: wget https://www.python.org/ftp/python/3.5.4/Python-3.5.4.tgz tar zxvf Python-3 ...