Spark MLlib FPGrowth关联规则算法
一.简介
FPGrowth算法是关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。在算法中使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构。FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。
相关术语:
1.项与项集
这是一个集合的概念,以购物车为例,一件商品就是一项【item】,若干项的集合为项集,如{特步鞋,安踏运动服}为一个二元项集。
2.关联规则
关联规则用于表示数据内隐含的关联性,例如买了新鞋的客户也往往会买袜子。
3.支持度
支持度是指在所有项集中{x,y}出现的可能性,即项集中同时出现含有x和y的概率。该指标作为建立强关联规则的第一个门槛,衡量了所考察关联规则在“量”上的多少。
4.置信度
表示在先决条件x发生的情况下,关联结果y发生的概率。这是生成强关联规则的第二个门槛,衡量了所考察的关联规则在“质”上的可靠性。
5.提升度
表示在含有x的条件下同时含有y的可能性与没有x的条件下项集含有y的可能性之比。
二.测试数据
r z h k p
z y x w v u t s
s x o n r
x z y m t s q e
z
x z y r q t p
三.代码实现
package big.data.analyse.mllib
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.{SparkContext, SparkConf}
/**
* 关联规则
* Created by zhen on 2019/4/11.
*/
object FPG {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("fpg")
conf.setMaster("local[2]")
val sc = new SparkContext(conf)
/**
* 加载数据
*/
val data = sc.textFile("data/mllib/sample_fpgrowth.txt")
val data_spl = data.map(row => row.split(" ")).cache()
/**
* 创建模型
*/
val minSupport = 0.2
val numPartition = 10
val model = new FPGrowth()
.setMinSupport(minSupport)
.setNumPartitions(numPartition)
.run(data_spl)
/**
* 打印结果
*/
println("Number of frequent itemsets : " + model.freqItemsets.count())
model.freqItemsets.collect.foreach{itemset =>
println(itemset.items.mkString("[", ",", "]") + " ==> " + itemset.freq)
}
}
}
四.结果
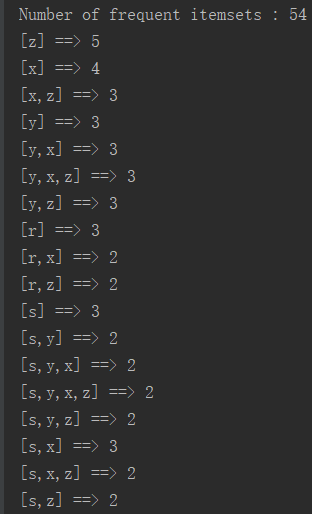 .......
.......
五.精简测试数据
y z
z y x
x
x z y
z
x z
六.二次开发代码实现
package big.data.analyse.mllib
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkContext, SparkConf}
/**
* 关联规则
* Created by zhen on 2019/4/11.
*/
object FPG {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("fpg")
conf.setMaster("local[2]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
/**
* 加载数据
*/
val data = sc.textFile("data/mllib/sample_fpgrowth.txt")
val data_spl = data.map(row => row.split(" ")).cache()
/**
* 创建模型
*/
val minSupport = 0.2
val numPartition = 10
val model = new FPGrowth()
.setMinSupport(minSupport)
.setNumPartitions(numPartition)
.run(data_spl)
/**
* 打印结果
*/
//println("Number of frequent itemsets : " + model.freqItemsets.count())
model.freqItemsets.collect.foreach{itemset =>
println(itemset.items.mkString("[", "-", "]") + " ==> " + itemset.freq)
}
/**
* 把结果数据转换为Map
*/
val map = model.freqItemsets
.map{row =>
var map : Map[String,Double] = Map()
map += (row.items.mkString("-") -> row.freq.toDouble)
map
}.collect().flatten.toMap
val list = map.keysIterator.toList
/**
* 拆分比较,计算概率
*/
var mid_result : Map[String, Double] = Map()
for(i <- 0 until list.length){
for(j <- 0 until list.length){
if(i != j){
if(list(i).contains(list(j))){ // xy -> xyz
var key = ""
if(list(i).indexOf(list(j)) == 0){ // 子串位于母串开头
key = list(j) + "_" + list(i).replace(list(j) + "-", "")
}else{// 子串位于母串的中间或者末尾
key = list(j) + "_" + list(i).replace("-" + list(j), "")
}
val left = map(list(j))
val right = map(list(i))
val value = right / left
mid_result += (key -> value)
}else{// TODO 分开包含的也要加进行,比较顺序不一定一致,例如:xy -> xzy
val left_key = list(i).split("-")
val right_key = list(j).split("-")
var isno = true
for(x <- 0 until right_key.length){
if(!left_key.contains(right_key(x))){
isno = false
}
}
if(isno){ // 包含
var mid_key = "" // 拼接key
for(y <- 0 until left_key.length){
if(!right_key.contains(left_key(y))){
mid_key += left_key(y) + "-"
}
}
if(mid_key != ""){ // 清除末尾多余的-
mid_key = mid_key.substring(0, mid_key.length-1)
}
val key = list(j) + "_" + mid_key
val left = map(list(j))
val right = map(list(i))
val value = right / left
mid_result += (key -> value)
}
}
}
}
}
/**
*平衡标签先后顺序对概率的影响
*/
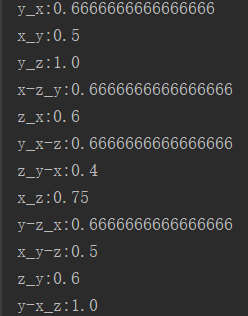
var result : List[String] = List()
val keys = mid_result.keysIterator.toList
for(i <- 0 until keys.length){
println(keys(i) +":"+ mid_result(keys(i)))
}
for(i <- 0 until keys.length){
for(j <- 0 until keys.length){
if(i != j){
val left = keys(i).split("_")
val right = keys(j).split("_")
if(left(0) == right(1) && left(1) == right(0)){
val value = ((mid_result(keys(i)) + mid_result(keys(j)))/2).formatted("%.2f") // 保留两位小数
if(left(0) < left(1)){
result = result.:+(left(0) + "_" + left(1) + "_" + value)
}else{
result = result.:+(left(1) + "_" + left(0) + "_" + value)
}
}
}
}
}
result = result.distinct // 去重
/*for(i <- 0 until result.length){
println(result(i))
}*/
/**
* 转换为rdd
*/
val result_rdd = sc.parallelize(result).map(row => {
val Array(left, right, probability) = row.split("_")
Row(left, right, probability.toDouble)
})
/**
* 定义结构
*/
val structType = new StructType(Array(
StructField("left", StringType, true),
StructField("right", StringType, true),
StructField("probability", DoubleType, true)
))
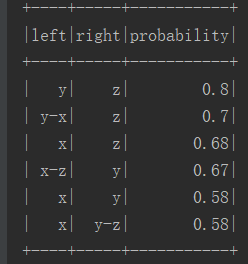
val result_df = sqlContext.createDataFrame(result_rdd, structType)
import org.apache.spark.sql.functions._
result_df.orderBy(desc("probability")).show()
}
}
七.结果
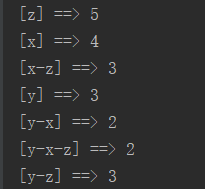
八.备注
集群模式出现以下异常【local模式无异常】;
can not set final scala.collection.mutable.ListBuffer field org.apache.spark.mllib.fpm.FPTree$Summary.nodes to scala.collection.mutable.ArrayBuffer
解决方案:
配置:conf.set("spark.serializer", "org.apache.spark.serializer.JavaSerializer")
Spark MLlib FPGrowth关联规则算法的更多相关文章
- Spark MLlib KMeans 聚类算法
一.简介 KMeans 算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把分类样本点分到各个簇.然后按平均法重新计算各个簇的质心,从而确定新的簇心.一直迭代,直到簇心的移动距离小于某个给定的值. ...
- Spark MLlib协同过滤算法
算法说明 协同过滤(Collaborative Filtering,简称CF,WIKI上的定义是:简单来说是利用某个兴趣相投.拥有共同经验之群体的喜好来推荐感兴趣的资讯给使用者,个人透过合作的机制给予 ...
- Spark mllib 随机森林算法的简单应用(附代码)
此前用自己实现的随机森林算法,应用在titanic生还者预测的数据集上.事实上,有很多开源的算法包供我们使用.无论是本地的机器学习算法包sklearn 还是分布式的spark mllib,都是非常不错 ...
- 十二、spark MLlib的scala示例
简介 spark MLlib官网:http://spark.apache.org/docs/latest/ml-guide.html mllib是spark core之上的算法库,包含了丰富的机器学习 ...
- Spark Mllib里如何生成KMeans的训练样本数据、生成线性回归的训练样本数据、生成逻辑回归的训练样本数据和其他数据生成
不多说,直接上干货! 具体,见 Spark Mllib机器学习(算法.源码及实战详解)的第2章 Spark数据操作
- Spark Mllib里的向量标签概念、构成(图文详解)
不多说,直接上干货! Labeled point: 向量标签 向量标签用于对Spark Mllib中机器学习算法的不同值做标记. 例如分类问题中,可以将不同的数据集分成若干份,以整数0.1.2,... ...
- 基于Spark的FPGrowth算法的运用
一.FPGrowth算法理解 Spark.mllib 提供并行FP-growth算法,这个算法属于关联规则算法[关联规则:两不相交的非空集合A.B,如果A=>B,就说A=>B是一条关联规则 ...
- FP-Growth in Spark MLLib
并行FP-Growth算法思路 上图的单线程形成的FP-Tree. 分布式算法事实上是对FP-Tree进行分割,分而治之 首先,假设我们只关心...|c这个conditional transactio ...
- spark mllib k-means算法实现
package iie.udps.example.spark.mllib; import java.util.regex.Pattern; import org.apache.spark.SparkC ...
随机推荐
- 1.JAVA-Hello World
1.Java开发介绍 J2SE:Java 2 Platform Standard Edition(2005年之后更名为JAVA SE). 包含构成Java语言核心的类.比如:数据库连接.接口定义.数据 ...
- Vue.js 学习笔记 第5章 内置指令
本篇目录: 5.1 基本指令 5.2 条件渲染指令 5.3 列表渲染指令 v-for 5.4 方法与事件 5.5 实战:利用计算属性.指令等知识开发购物车 回顾一下第2.2节,我们己经介绍过指令(Di ...
- android Fragment中使用Toolbar
在Activity中可以直接使用 setSupportActionBar(toolbar); 就可以重写 onCreateOptionsMenu 和 onOptionsItemSelected 方法: ...
- eShopOnContainers 知多少[1]:总体概览
引言 在微服务大行其道的今天,Java阵营的Spring Boot.Spring Cloud.Dubbo微服务框架可谓是风水水起,也不得不感慨Java的生态圈的火爆.反观国内.NET阵营,微服务却不愠 ...
- 机器学习 ML.NET 发布 1.0 RC
ML.NET 是面向.NET开发人员的开源和跨平台机器学习框架(Windows,Linux,macOS),通过使用ML.NET,.NET开发人员可以利用他们现有的工具和技能组,为情感分析,推荐,图像分 ...
- JQuery 常用的那些东西
CDN Google CDN Microsoft CDN CDNJS CDN jsDelivr CDN 选择器 jQuery 元素选择器和属性选择器允许您通过标签名.属性名或内容对 HTML 元素进行 ...
- CAS机制与自旋锁
CAS(Compare-and-Swap),即比较并替换,java并发包中许多Atomic的类的底层原理都是CAS. 它的功能是判断内存中某个地址的值是否为预期值,如果是就改变成新值,整个过程具有原子 ...
- AI - 深度学习之美十四章-概念摘要(8~14)
原文链接:https://yq.aliyun.com/topic/111 本文是对原文内容中部分概念的摘取记录,可能有轻微改动,但不影响原文表达. 08 - BP算法双向传,链式求导最缠绵 反向传播( ...
- 日吞吐万亿,腾讯云时序数据库CTSDB解密
一.背景 随着移动互联网.物联网.大数据等行业的高速发展,数据在持续的以指数级的速度增长,比如我们使用手机访问互网络时的行为数据,各种可穿戴设备上报的状态数据,工厂中设备传感器采集的指标数据,传统互联 ...
- python接口自动化(一)--什么是接口、接口优势、类型(详解)
简介 经常听别人说接口测试,接口测试自动化,但是你对接口,有多少了解和认识,知道什么是接口吗?它是用来做什么的,测试时候要注意什么?坦白的说,笔者之前也不是很清楚.接下来先看一下接口的定义. 定义 接 ...