“卷积神经网络(Convolutional Neural Network,CNN)”之问
目录
Q1:CNN 中的全连接层为什么可以看作是使用卷积核遍历整个输入区域的卷积操作?
A1:以 AlexNet 为例,AlexNet 最后 3 层为全连接层,第一个全连接层的输入层是由卷积层做拉伸而得。对于第一个全连接层中的任一个神经元 \(FC_i^{(1)}\),其都和输入层中所有神经元相连,如果我们将输入层神经元排列成 6×6×256,即对输入层不进行拉伸,那么神经元 \(FC_i^{(1)}\) 就相当于对输入层乘以一个 6×6×256 的 filter(即 filter 的大小和 feature map 是一样的),经激活函数后得到的就是该神经元 \(FC_i^{(1)}\) 的输出。如果有 4096 个 filter,那么第一个全连接层就会有 1×1×4096 个神经元。
之后情况类似,用 4096 个 1×1×4096 的 fiter 进行卷积即可得到第二层全连接层(1×1×4096),用 1000 个 1×1×4096 的 fiter 进行卷积即可得到第三层全连接层(1×1×1000)。所以全连接层也可以看成是卷积核遍历整个输入区域的卷积操作。

Q2:1×1 的卷积核(filter)怎么理解?
A2:首先需要搞清楚,1×1 的 filter 都干了些什么。
1)不改变 feature map 的大小。即当 stride 和 padding 分别为 1 和 0 时,使用 1×1 的 filter 对大小为 6×6 的 feature map 进行卷积,并不会改变 feature map 的大小。
2)会改变 channel 的数量,以此来达到升维和降维。下一层 channel 数量由该层 filter 的个数决定。
3)增加了非线性。下一层每一个 channel 的 feature map 中任意一点都是上一层同一位置所有 channel 的非线性组合(因为有非线性激活函数)。
4)channel 间信息的交互。
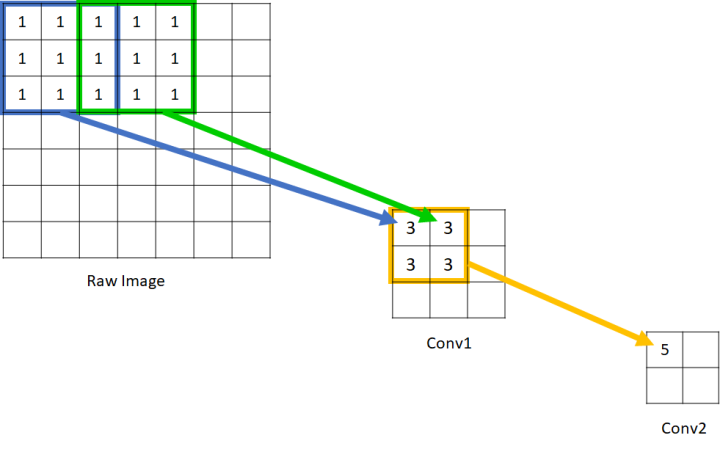
Q3:什么是感受野(Receptive field)?
A3:感受野是指卷积神经网络每一层特征图(feature map)上的神经元在原始图像上映射的区域大小。
图 2 中,原始图像上的像素点只能看到本身,故可以认为其感受野为 1×1;conv1 中神经元能看到原始图像的 3×3,故其感受野为 3×3;而 conv2 中神经元能看到原始图像 5×5 的区域,故其感受野为 5×5。
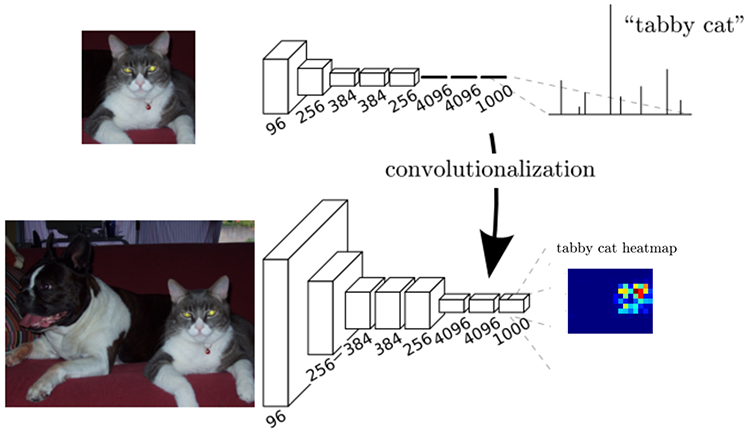
Q4:对含有全连接层的 CNN,输入图像的大小必须固定?
A4:以图 1 中展示的 AlexNet 为例,如果 CNN 的输入层大小改变,那么 AlexNet 全连接层的输入层(由卷积层拉伸而得的)神经元个数是会改变的,或者说拉伸前 feature map 的大小变了,后面的全连接操作也没法做了(全连接层参数的个数都改变了)。
完全卷积网络(Fully Convolutional Network,FCN)的输入图像可以为任意大小,当然输出结果的大小和输入图像大小相关。FCN 的做法就是把全连接层换成了卷积层,参数个数没变。如图 3 把 AlexNet 最后三层全连接层变为卷积层,就得到一个 FCN。
Q5:什么是 Global Average Pooling(GAP)?
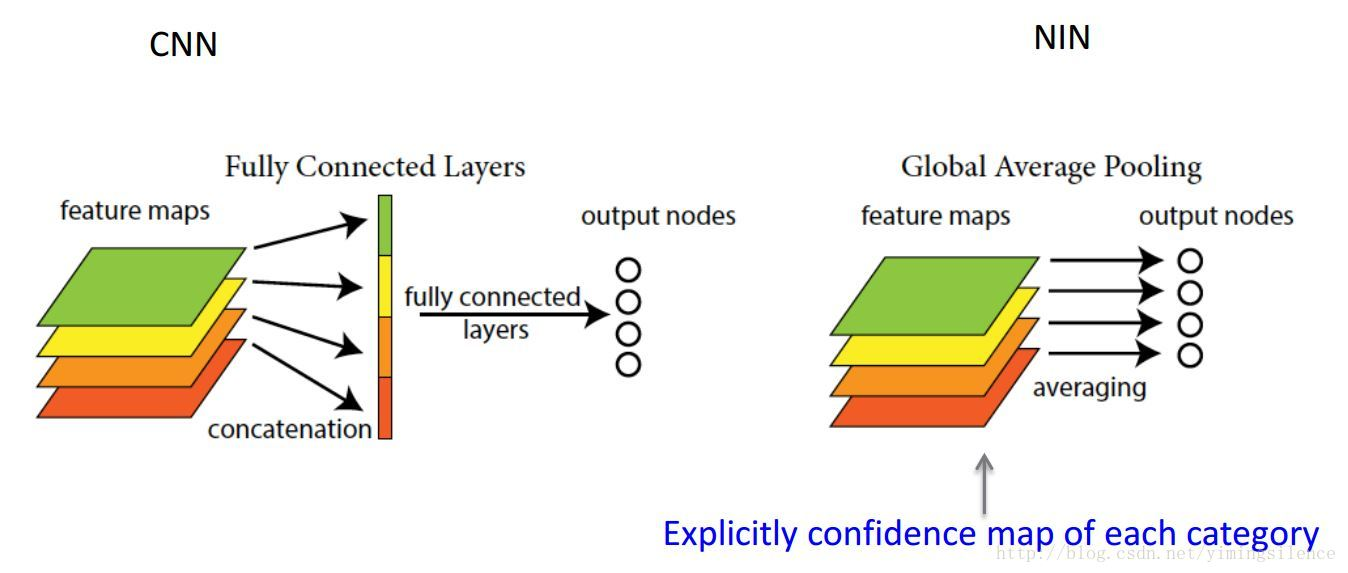
A5:Global Average pooling(GAP)和 (local)average pooling 其实就是一个东西,只是 pooling 时对 feature map 作用的区域有区别:global 意味着对 feature map 的整个区域,即对一个 feature map 的整个区域求均值最后得到一个值;而 local 则意味着 feature map 中的一小块区域,如 2×2、3×3 等。

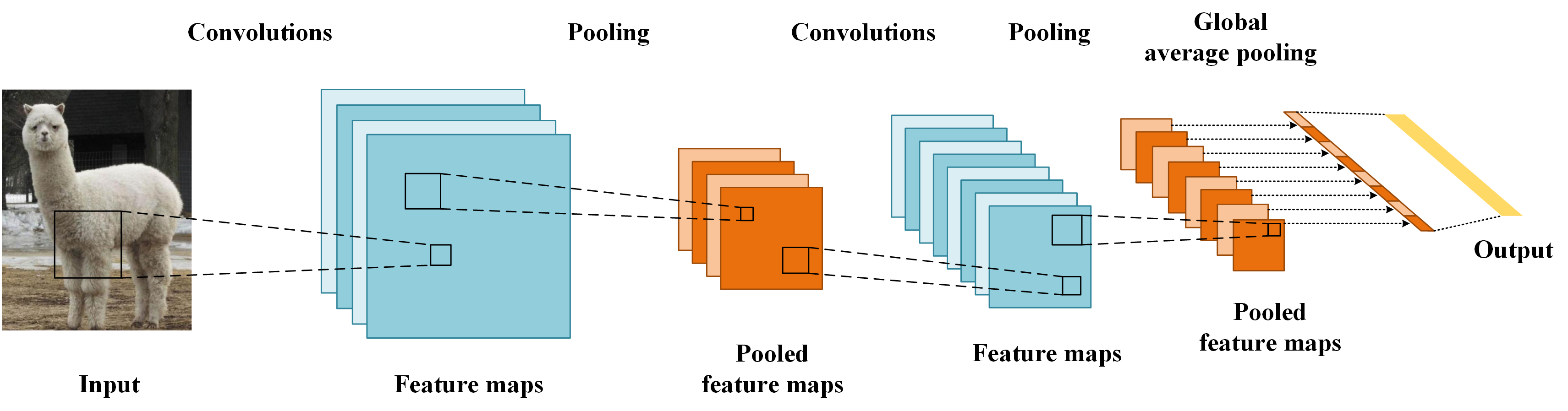
那么 GAP 有没有什么好处呢?由于没有了全连接层,输入就不用固定大小了,因此可支持任意大小的输入;此外,引入GAP更充分的利用了空间信息,且没有了全连接层的各种参数,鲁棒性强,也不容易产生过拟合;还有很重要的一点是,在最后的 mlpconv层(也就是最后一层卷积层)强制生成了和目标类别数量一致的特征图,经过GAP以后再通过softmax层得到结果,这样做就给每个特征图赋予了很明确的意义,也就是categories confidence maps。参见博客 凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM) -- 宾狗
Q6:什么是 depthwise separable convolution?Depthwise convolution 和 pointwise convolution 分别又是什么?
A6:Depthwise separable convolution 将一个标准的卷积操作(如 LeNet、AlexNet 等网络中的卷积)分为两个部分,分别是 depthwise convolution 和 pointwise convolution。Separable convolution 的参数数量少于标准卷积。
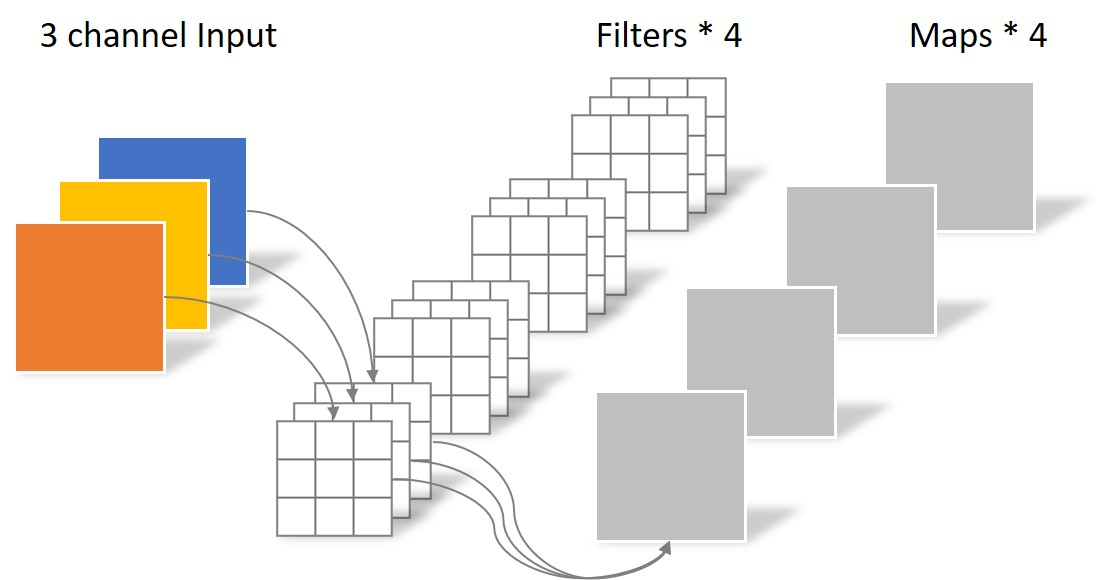
Depthwise convolution 中 filter 的个数和输入数据的 channel 数一致,且每个 filter 的大小为 W×H×1(W 和 H 分别为输入层 feature map 的宽、高),每一个 filter 只和输入数据对应的一个 channel 做 convolution。Depthwise convolution 在每一个 channel 上独立地执行 spatial convolution,channel 之间没有交互,只利用了 feature map 上的空间信息。
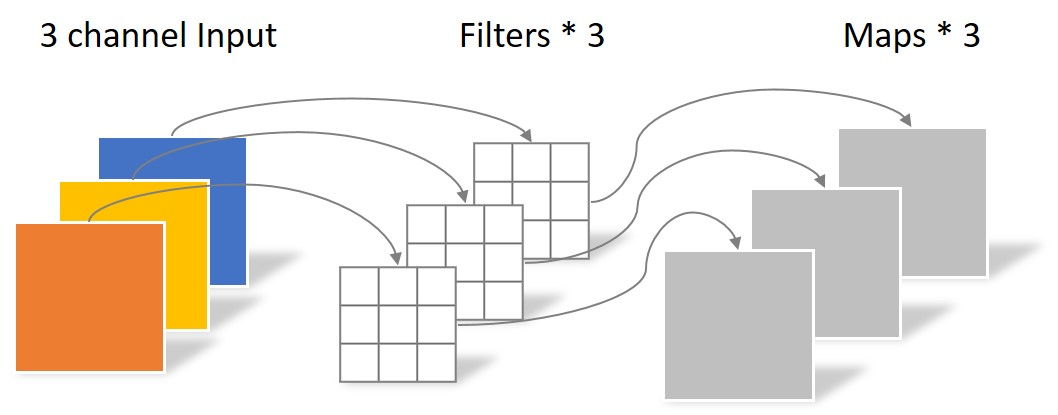
Pointwise convolution 中 filter 的个数任意,filter 的个数决定了输出层 channel 的数目,其每个 filter 大小为 1×1×C(C 为输入层的 channel 数)。Pointwise convolution 将 depthwise convolution 生成的 feature channels 投影到新的 channel space,这一步输入层 channel 之间的信息进行了交互。
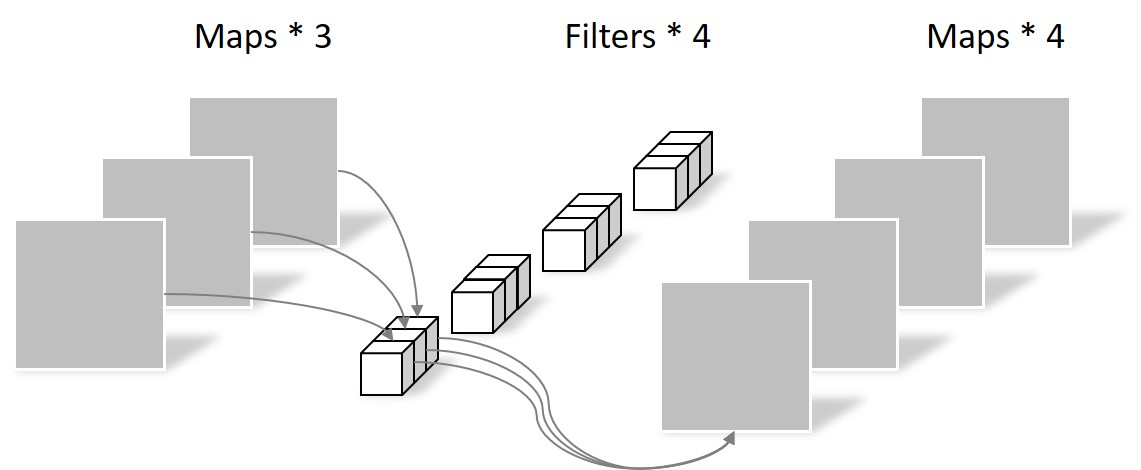
将图 8 中展示的 depthwise convolution 和图 9 的 pointwise convolution 拼接起来,就是一个 depthwise separable convolution。
References
语义分割中的深度学习方法全解:从FCN、SegNet到各代DeepLab -- 量子学园
一文读懂卷积神经网络中的1x1卷积核 -- Amusi
深度神经网络中的感受野(Receptive Field) -- 蓝荣祎
FCN的学习及理解(Fully Convolutional Networks for Semantic Segmentation)-- 凹酱deep
关于 global average pooling -- 默一鸣
凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM) -- 宾狗
卷积神经网络中的Separable Convolution -- 尹国冰
“卷积神经网络(Convolutional Neural Network,CNN)”之问的更多相关文章
- 卷积神经网络(Convolutional Neural Network, CNN)简析
目录 1 神经网络 2 卷积神经网络 2.1 局部感知 2.2 参数共享 2.3 多卷积核 2.4 Down-pooling 2.5 多层卷积 3 ImageNet-2010网络结构 4 DeepID ...
- 深度学习FPGA实现基础知识10(Deep Learning(深度学习)卷积神经网络(Convolutional Neural Network,CNN))
需求说明:深度学习FPGA实现知识储备 来自:http://blog.csdn.net/stdcoutzyx/article/details/41596663 说明:图文并茂,言简意赅. 自今年七月份 ...
- 卷积神经网络Convolutional Neural Networks
Convolutional Neural Networks NOTE: This tutorial is intended for advanced users of TensorFlow and a ...
- Convolutional neural network (CNN) - Pytorch版
import torch import torch.nn as nn import torchvision import torchvision.transforms as transforms # ...
- 斯坦福大学卷积神经网络教程UFLDL Tutorial - Convolutional Neural Network
Convolutional Neural Network Overview A Convolutional Neural Network (CNN) is comprised of one or mo ...
- 卷积神经网络(Convolutional Neural Network,CNN)
全连接神经网络(Fully connected neural network)处理图像最大的问题在于全连接层的参数太多.参数增多除了导致计算速度减慢,还很容易导致过拟合问题.所以需要一个更合理的神经网 ...
- 【转载】 卷积神经网络(Convolutional Neural Network,CNN)
作者:wuliytTaotao 出处:https://www.cnblogs.com/wuliytTaotao/ 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可,欢迎 ...
- 【RS】Automatic recommendation technology for learning resources with convolutional neural network - 基于卷积神经网络的学习资源自动推荐技术
[论文标题]Automatic recommendation technology for learning resources with convolutional neural network ( ...
- 卷积神经网络(Convolutional Neural Networks)CNN
申明:本文非笔者原创,原文转载自:http://www.36dsj.com/archives/24006 自今年七月份以来,一直在实验室负责卷积神经网络(Convolutional Neural ...
- 树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
树卷积神经网络Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning 2018-04-17 08:32:39 看_这是一 ...
随机推荐
- mysql经典面试题
数据库优化:这个优化法则归纳为5个层次:1. 减少数据访问(减少磁盘访问)2. 返回更少数据(减少网络传输或磁盘访问)3. 减少交互次数(减少网络传输)4. 减少服务器CPU开销(减少CPU及内存开销 ...
- lintcode 链表求和
题目要求 你有两个用链表代表的整数,其中每个节点包含一个数字.数字存储按照在原来整数中相反的顺序,使得第一个数字位于链表的开头.写出一个函数将两个整数相加,用链表形式返回和. 样例 给出两个链表 3- ...
- HTML知识点总结
HTML知识点总结 一.需要熟悉的基本快捷键 ctrl+c 复制 ctrl+v 粘贴 ctrl+x 剪切 ctrl+tab ...
- 44.1khz 16位比特双声道一分钟的音乐文件占多少硬盘空间?
2*2*44.1*1000*60=10584000字节=10M2个声道*(16比特/8比特)字节*采样率(每秒采样44.1*1000次)*一分钟有60秒16比特是精度,描述振幅的,16比特等于2个字节 ...
- IDEA修改编辑背景图片
1.打开File -> Setting -> Plugs -> 搜索BackgroundImage. 然后安装.如图 2.按快捷键ctrl+shift+A,搜索set backgro ...
- UnicodeDecodeError: 'utf-8' codec can't decode byte 0xef in position 99: invalid continuation byte
Traceback (most recent call last): File "/Users/c2apple/PycharmProjects/easyToPython/fileMethod ...
- java 保留字段volatile、transient、native、synchronized
1.volatile Java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程.当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享 ...
- SSM-SpringMVC-31:SpringMVC中利用hibernate-validator做后台校验
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 校验有三种:前台页面校验(例如js和h5),后台校验,数据库校验 但是一般能不用数据库校验就不用数据库校验,因 ...
- SSM-MyBatis-05:Mybatis中别名,sql片段和模糊查询加getMapper
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 简单概述一下本讲 别名,sql片段简单写一下,模糊查询多写一点 一.别名 <typeAliases> ...
- Sign http
http接口请求参数签名工具类的实现和测试代码 http://blog.csdn.net/5iasp/article/details/52539901 http://www.what21.com/pr ...