Python爬虫知识点二
一。request库
import json
import requests from io import BytesIO
#显示各种函数相当于api
# print(dir(requests)) url = 'http://www.baidu.com'
r = requests.get(url)
print(r.text)
print(r.status_code)
print(r.encoding)
结果:

# 传递参数:不如http://aaa.com?pageId=1&type=content
params = {'k1':'v1', 'k2':'v2'}
r = requests.get('http://httpbin.org/get', params)
print(r.url)
结果:

# 二进制数据
# r = requests.get('http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg')
# image = Image.open(BytesIO(r.content))
# image.save('meinv.jpg')
# json处理
r = requests.get('https://github.com/timeline.json')
print(type(r.json))
print(r.text)
结果:

# 原始数据处理
# 流式数据写入
r = requests.get('http://i-2.shouji56.com/2015/2/11/23dab5c5-336d-4686-9713-ec44d21958e3.jpg', stream = True)
with open('meinv2.jpg', 'wb+') as f:
for chunk in r.iter_content(1024):
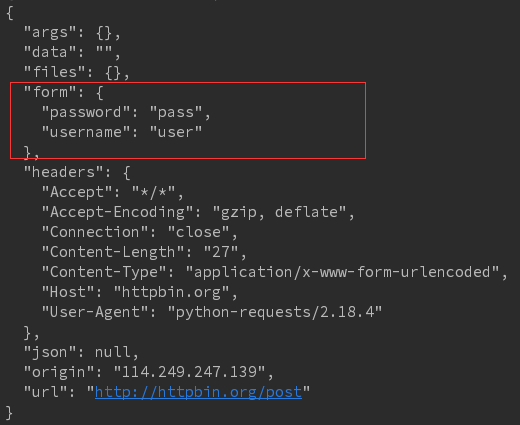
f.write(chunk) # 提交表单 form = {'username':'user', 'password':'pass'}
r = requests.post('http://httpbin.org/post', data = form)
print(r.text)
结果:参数以表单形式提交,所以参数放在form参数中
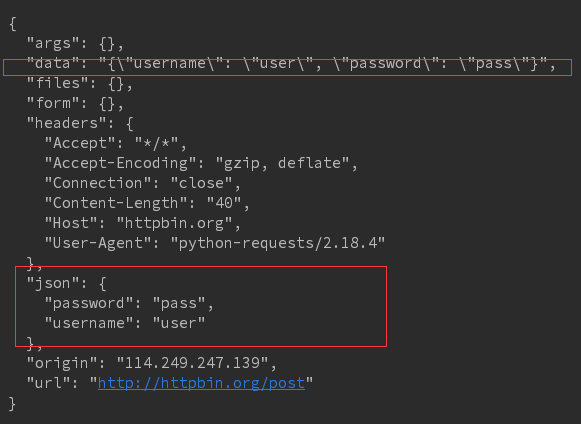
r = requests.post('http://httpbin.org/post', data = json.dumps(form))
print(r.text)
结果:参数不是以form表单提交的,所以放在json字段中
# cookie url = 'http://www.baidu.com'
r = requests.get(url)
cookies = r.cookies
#cookie实际上是一个字典
for k, v in cookies.get_dict().items():
print(k, v)
结果:cookie实际上是一个键值对

cookies = {'c1':'v1', 'c2': 'v2'}
r = requests.get('http://httpbin.org/cookies', cookies = cookies)
print(r.text)
结果:

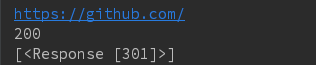
# 重定向和重定向历史
r = requests.head('http://github.com', allow_redirects = True)
print(r.url)
print(r.status_code)
print(r.history)
结果:通过301定向
# # 代理
#
# proxies = {'http': ',,,', 'https': '...'}
# r = requests.get('...', proxies = proxies)
二。BeautifulSoup库
html:举例如下
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
解析代码如下:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('test.html'))
#使html文本更加结构化
# print(soup.prettify())
# Tag
print(type(soup.title))
结果:bs4的一个类

print(soup.title.name)
print(soup.title)
结果如下:

# String print(type(soup.title.string))
print(soup.title.string)
结果如下:只显示标签里面内容

# Comment print(type(soup.a.string))
print(soup.a.string)
结果:显示注释中的内容,所以有时需要判断获取到的内容是不是注释

#
# '''
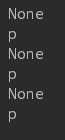
for item in soup.body.contents:
print(item.name) 结果:body下面有三个item
# CSS查询
print(soup.select('.sister'))
结果:样式选择器返回带有某个样式的所有内容 结果为一个list

print(soup.select('#link1'))
结果:ID选择器,选择ID等于link1的内容

print(soup.select('head > title'))
结果:

a_s = soup.select('a')
for a in a_s:
print(a)
结果:标签选择器,选择所有a标签的

持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Python爬虫知识点二的更多相关文章
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- python爬虫知识点详解
python爬虫知识点总结(一)库的安装 python爬虫知识点总结(二)爬虫的基本原理 python爬虫知识点总结(三)urllib库详解 python爬虫知识点总结(四)Requests库的基本使 ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
随机推荐
- 关于 AspNet Core 的配置文件 与VS2017 安装
下面链接 是VS2017 安装EXE 我现在装过了就不去截图演示了,有哪位不理解的可以@我. 链接:https://pan.baidu.com/s/1hsjGuJq 密码:ug59 1.今天我给大家带 ...
- 更便捷的css处理方式-postcss
更便捷的css处理方式-PostCSS 一般来说介绍一个东西都是要从是什么,怎么用的顺序来讲.我感觉这样很容易让大家失去兴趣,先看一下postcss能做点什么,有兴趣的话再往下看,否则可能没有耐心看下 ...
- C++彩色数据流动界面
一个数据流动界面 #include <windows.h> #include <time.h> #include <cstdio> #include <str ...
- 动手开发一个名为“微天气”的微信小程序(上)
引言:在智能手机软件的装机量中,天气预报类的APP排在比較靠前的位置.说明用户对天气的关注度非常高.由于人们不管是工作还是度假旅游等各种活动都须要依据自然天气来安排.跟着本文开发一个"微天气 ...
- 2016.3.17__CSS3动画__第十一天
CSS3动画 假设您认为这篇文章还不错,能够去H5专题介绍中查看很多其它相关文章. 通过 CSS3,我们能够创建动画,这能够在很多网页中取代动绘图片.Flash 动画以及 JavaScript. 今日 ...
- iOS 获取导航栏和状态栏的高度
CGRect rect = [[UIApplication sharedApplication] statusBarFrame]; 状态栏的高度: float status height = rec ...
- 快速序列化组件MessagePack介绍
简介 MessagePack for C#(MessagePack-CSharp)是用于C#的极速MessagePack序列化程序,比MsgPack-Cli快10倍,与其他所有C#序列化程序相比,具有 ...
- 一 、Spring Boot 学习之项目搭建
一.简介 spring 官方网站本身使用Spring 框架开发,随着功能以及业务逻辑的日益复杂,应用伴随着大量的XML配置文件以及复杂的Bean依赖关系. 随着Spring 3.0的发布,Spring ...
- (转)解决jdk1.8中发送邮件失败(handshake_failure)问题
解决jdk1.8中发送邮件失败(handshake_failure)问题 作者 zhisheng_tian 2016.08.12 22:44* 字数 1573 阅读 2818评论 6喜欢 9 暑假在家 ...
- windows 下使用VMware Workstation Pro 工具,ubuntu创建虚拟机
本文记录windows 下使用VMware Workstation Pro 工具,ubuntu创建虚拟机 的步骤 第一步 [文件] --- [新建虚拟机] 第二步 弹出的新建虚拟机向导对话框 标准 ...