Flink内存解释
一、JobManager内存
JobManager 是 Flink 集群的控制单元。 它由三种不同的组件组成:ResourceManager、Dispatcher 和每个正在运行作业的 JobMaster。
配置 JobManager 内存最简单的方法就是进程的配置总内存。 本地执行模式下不需要为 JobManager 进行内存配置,配置参数将不会生效。

| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存 |
| 堆外内存 | jobmanager.memory.off-heap.size | JobManager 的堆外内存(直接内存或本地内存) |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace |
| JVM 开销 | jobmanager.memory.jvm-overhead.min jobmanager.memory.jvm-overhead.max jobmanager.memory.jvm-overhead.fraction |
用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分 |
注:如果已经明确设置了 JVM 堆内存,建议不要再设置进程总内存或 Flink 总内存,否则可能会造成内存配置冲突。
二、配置 TaskManager 内存
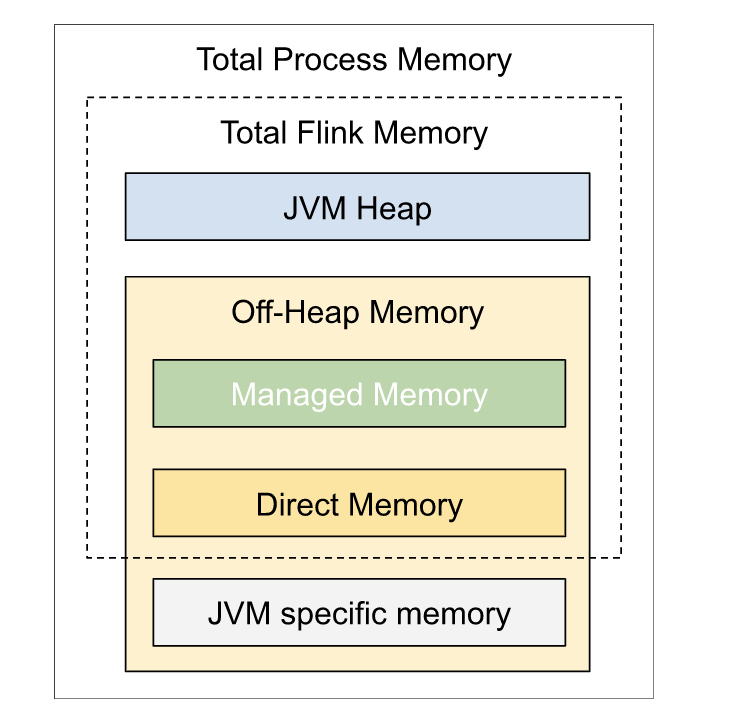
Flink JVM 进程的进程总内存(Total Process Memory)*包含了
(1)Flink 应用使用的内存(Flink 总内存)
JVM 堆内存(Heap Memory)
托管内存(Managed Memory)
其他直接内存(Direct Memory)
本地内存(Native Memory)
(2)运行 Flink 的 JVM 使用的内存
Flink内存解释的更多相关文章
- Flink内存溢出
Flink内存模型 此图是基于flink1.12版本. 一个taskmanager给了6g内存,可以有很清楚的看到各个部分占用的内存,还是实时变化的. 名词解释 组件 配置项 描述 Framework ...
- 一文带你彻底了解大数据处理引擎Flink内存管理
摘要: Flink是jvm之上的大数据处理引擎. Flink是jvm之上的大数据处理引擎,jvm存在java对象存储密度低.full gc时消耗性能,gc存在stw的问题,同时omm时会影响稳定性.同 ...
- flink内存模型详解与案例
任务提交时的一些yarn设置(通用客户端模式) 指定并行度 -p 5 \ 指定yarn队列 -Dyarn.appl ...
- Flink内存管理源代码解读之基础数据结构
概述 在分布式实时计算领域,怎样让框架/引擎足够高效地在内存中存取.处理海量数据是一个非常棘手的问题.在应对这一问题上Flink无疑是做得非常杰出的,Flink的自主内存管理设计或许比它自身的知名度更 ...
- Apache Flink - 内存管理
JVM: JAVA本身提供了垃圾回收机制来实现内存管理 现今的GC(如Java和.NET)使用分代收集(generation collection),依照对象存活时间的长短使用不同的垃圾收集算法,以达 ...
- linux的top下buffer与cache的区别、free命令内存解释
buffer: 缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据 的区域.通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据 时,速度快的设备的操作进程不发 ...
- Flink架构,源码及debug
序 工作中用Flink做批量和流式处理有段时间了,感觉只看Flink文档是对Flink ProgramRuntime的细节描述不是很多, 程序员还是看代码最简单和有效.所以想写点东西,记录一下,如果能 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- Java单个对象内存布局.md
我们在如何获取一个Java对象所占内存大小的文章中写了一个获取Java对象所占内存大小的工具类(ObjectSizeFetcher),那么接下来,我们使用这个工具类来看一下Java中各种类型的对象所占 ...
随机推荐
- Golang之工作区workspace
快速开始 创建工作区 写一个最简单的基础项目实际演练一下 Go workspace. 首先,创建 workspace 工作区. $: mkdir workspace $: cd workspace $ ...
- pikachu平台暴力破解详解
声明:文章只是起演示作用,所有涉及的网站和内容,仅供大家学习交流,如有任何违法行为,均和本人无关,切勿触碰法律底线. 文章来自个人csdn博客,感兴趣的可以关注一下,https://blog.csdn ...
- javascript的一些API接口的使用
1.blob http URL 在编辑器中,有的情况下插入图片,会讲图片转成 blob:http://localhost/*** 的这种形式.这种形式的URL实际数据是存放在浏览器的内存中. 这种情况 ...
- 原创单总线传输协议b2s (附全部verilog源码)
一.b2s协议背景介绍 本单总线传输协议为精橙FPGA团队原创,含传送端(transmitter)和接收端(receiver)两部分,基于verilog语言,仅使用单个I/O口进行多位数据的传输,传输 ...
- 教你自创工作流,赋予AI助理个性化推荐超能力
之前,我们已经完成了工作流的基本流程和整体框架设计,接下来的任务就是进入实际操作和实现阶段.如果有同学对工作流的整体结构还不够熟悉,可以先参考一下这篇文章,帮助你更好地理解和掌握工作流的各个部分: 本 ...
- 为了改一行代码,我花了10多天时间,让性能提升了40多倍---Pascal架构GPU在vllm下的模型推理优化
ChatGPT生成的文章摘要 这篇博客记录了作者在家中使用Pascal显卡运行大型模型时遇到的挑战和解决方案.随着本地大型模型性能的提升,作者选择使用vllm库进行推理.然而,作者遇到了多个技术难题, ...
- redis设置密码和开启远程访问
改密码 默认redis安装后,密码是默认的,通过查看安装目录的config文件,可以查到:requirepass 这个设置,默认是啥就是啥. 需要修改密码的话,把这个注释拿掉,将requirepass ...
- R数据分析:网状meta分析的理解与实操
meta分析之前有给大家写过,但是meta分析只能比较两个方法.经常是被用来证明在现有研究中显示矛盾结果的干预方法到底有没有效的时候使用,通过证据综合得到某种干预到底有没有用的结论.但是如果我要证明好 ...
- 拦截烂SQL,解读GaussDB(DWS)查询过滤器过滤规则原理
本文分享自华为云社区<GaussDB(DWS)查询过滤器过滤规则原理与使用介绍>,作者: 清道夫. 1. 前言 适用版本:[9.1.0.100(及以上)] 查询过滤器在9.1.0.100之 ...
- 抛出 NoClassDefFoundError: javax/validation/constraints/Size 问题的解决方法
Error:java: java.lang.NoClassDefFoundError: javax/validation/constraints/Size 问题很明显,找不到相关类.我们可以在 pom ...