【MOOC】北京理工大学Python网络爬虫与信息提取慕课答案-综合挑出了一些很难评的慕课测验题
1 Requests库中的get()方法最常用,下面哪个说法正确?
A. 网络爬虫主要进行信息获取,所以,get()方法最常用。
B. get()方法是其它方法的基础,所以最常用。
√C. 服务器因为安全原因对其他方法进行限制,所以,get()方法最常用。
D. HTTP协议中GET方法应用最广泛,所以,get()方法最常用。
C正确,get()方法最常用的原因在于服务器端对push()、post()、patch()等数据推送的限制,试想,如果允许大家向服务器提交数据,将带来无穷无尽的安全隐患。因此,通过get()获取数据,服务器作为数据提供方而不是接收方,更为安全。
A错,因为post也可以获取信息;
B错,因为request()才是基础;
D错,不好评价。
2 Requests库中,以下代表从服务器返回HTTP协议内容部分猜测获得编码方式的属性是:
A. .headers
B. .text
C. .encoding
√D. .apparent_encoding
通过内容分析编码用
.apparent_encoding,一般作为备选编码方式。
3 Requests库中,以下代表从服务器返回HTTP协议头所推荐编码方式的属性是:
A. .headers
B. .text
√C. .encoding
D. .apparent_encoding
从响应头分析编码用
.encoding就行。
4 获得soup对象中,能够获得a标签全部属性的代码是:
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo, "html.parser")
A. soup.a.attrs[0]
B. soup.a.attrs[]
C. soup.a[0].attrs
√D. soup.a.attrs
a标签是HTML预定义标签,通过soup.a可以直接获取。
【我选错了选成C了。很难评,原来有这种用法 】
5 Beautiful Soup库不可加载的解析器是:
A. html5lib
B. html.parser
C. lxml
√D. re
就是BeautifulSoup(demo, “html.parser”)第二个参数的可选项。
6 下面哪个不是信息提取的思路?
A. 结合部分格式解析和搜索的方式提取所需要的信息。
B. 无视格式,直接搜索找到所需提取的信息。
C. 按照信息格式完全解析,解析后找到所需提取的信息。
√D. 通过自然语言处理方式找到所需提取的信息。
B确实是条思路,D是不太靠谱的,因为html是标签语言,离自然语言有一段距离。
7 为什么Beautiful Soup库叫这个名字?
A. Python Software Foundation要求开发者叫这个名字
√B. 原因不详,第三方库起名原因多种多样,没必要深究
C. 之前有类似的库叫类似的名字
D. 开发者喜欢煲汤
Python计算生态采用"集市"模式,命名权归贡献者。
【笑,我毫不犹豫选D 】
网上查了其他资料,确实各种说法都有,有说是来源于童话故事的,有说网页标签本身乱得像一锅汤一样,这个库是用来让汤变成靓汤的。
8 关于Beautiful Soup库说法错误的是:
A. Beautiful Soup库是解析、遍历、维护标签树的功能库
B. Beautiful Soup库能够对HTML和XML等格式进行解析
√C. Beautiful Soup库可常用于生成标签树
D. Beautiful Soup库也叫bs4库
Beautiful Soup库不能够生成标签树,只能解析、遍历和维护。
【笑,我以为生成标签树=生成标签树对象,没想到它意思是生成一个新的网页标签树 】
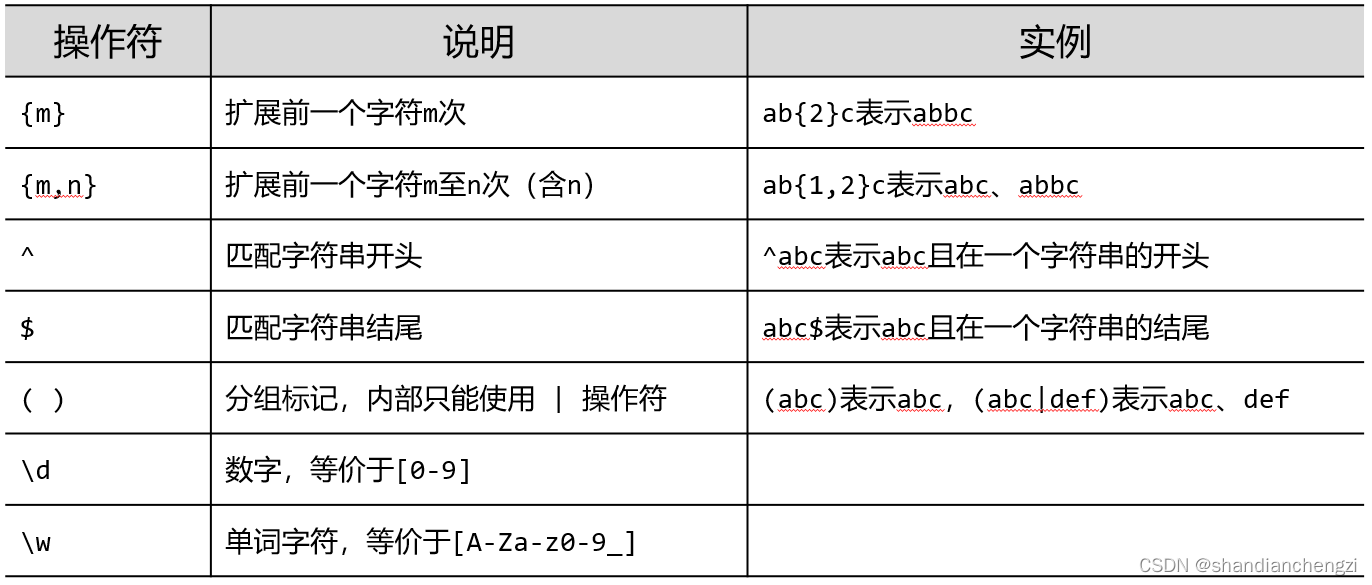
9 正则表达式:\d{3}-\d{8}|\d{4}-\d{7}能匹配哪个?
A. 010-1234567
√B. 010-12345678
C. 01012345678
D. 0521-12345678
注意
|是“或者”,表示任选一个。
10 re库可以使用如下方式表示正则表达式:r’[1-9]\d{5}',其中r是什么意思?
√A. 原生字符串标记
B. 开始位置标记
C. 正则表达式标记
D. 强制标记
这题很容易手滑选C,不过如果有代码经验的话,就会知道加个r是为了让转义字符
\不再是转义的含义,便于直接作为正则表达式输入到re的方法中。
11 正则表达式:^-?\d+$的含义是什么?
A. 一个带有负号的数字字符串
B. 由26个字母组成的字符串
√C. 一个整数形式的字符串
D. 由26个字母和数字组成的字符串
这题可坑了,问号
?是0次或1次扩展,点.才是任一字符,但先看到A就很容易选错。

12 Beautiful Soup库与re库之间关系,描述正确的是:
A. re库能实现HTML解析,功能上与Beautiful Soup库类似
B. Beautiful Soup库中可以加载re库
√C. 这两个库没有关系
D. re库中可以加载Beautiful Soup库
ABD错,所以C对。
【要知道,根据马原,事物是普遍联系的,这个C说实在的也是错的,这很难评。随便举个关系:bs4库解析出来的标签树的字符串内容,可以被re库正则匹配进一步筛选解析。】
【MOOC】北京理工大学Python网络爬虫与信息提取慕课答案-综合挑出了一些很难评的慕课测验题的更多相关文章
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 过程. 5.写一篇不少于100 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- PYTHON网络爬虫与信息提取[信息的组织与提取](单元五)
1 三种信息类型的简介 xml : extensible markup language 与html非常相似 现有html后有xml xml是html发展来的 扩展 通用 json 类型 javas ...
- Python网络爬虫与信息提取[request库的应用](单元一)
---恢复内容开始--- 注:学习中国大学mooc 嵩天课程 的学习笔记 request的七个主要方法 request.request() 构造一个请求用以支撑其他基本方法 request.get(u ...
- Python网络爬虫与信息提取(二)—— BeautifulSoup
BeautifulSoup官方介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. 官方 ...
随机推荐
- Flink批处理-简单案例-01
一.简单案例 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http ...
- “未能加载工具箱项xxx,将从工具箱中将其删除”提示出现原因及解决方案
https://www.thinbug.com/q/27289366 https://social.msdn.microsoft.com/Forums/vstudio/en-US/77e10b58-4 ...
- CF1693F题解
备注 发表时间:2023-06-17 21:51 前言 yny 学长来 cdqz 讲课,写一篇讲课的题的题解纪念一下. 题意 给你一个 01 序列,有以下操作: 选择一段区间 设 \(cnt_0,cn ...
- CUDA与Cython之BatchGather
技术背景 在前面一篇文章中,我们介绍过Cython+CUDA框架下实现一个简单的Gather算子的方法.这里演示Gather算子的升级版本实现--BatchGather算子.不过这里只是加了一个Bat ...
- mac、windows 配置python国内镜像源
前言 我们在使用python pip安装第三方库时,经常会发生超时报错,这是可以指定临近的镜像源快速更新. mac中 在用户目录下建立一个".pip"目录,到目录里新建一个文件&q ...
- Chrome设置header请求响应头 Chrome ModHeader插件,添加/修改/删除HTTP请求标头和响应标头
ModHeader,是一款可以添加/修改/删除请求标头和响应标头的浏览器插件. ModHeader插件功能 首先,ModHeader插件支持添加/修改/删除请求标头和响应标头,并可以启用基于URL / ...
- HIVE将长整数转字符串的错误
有一个超长字符串,比如:441066000000001005712973,原来存放在HIVE里表A 是用DECIMAL(24)类型.现在要与另外一个用string类型保存这个字段的表B关联,老是失败. ...
- VS Code Runner 插件配置
VS Code Runner 插件配置 Code Runner插件是一个小而美的插件,可以很方便的运行一些简单的代码文件. 本篇博文记录一些相关的环境配置. 设置C++编译标准 这里可以设置默认的C+ ...
- Two-Stream Convolutional Networks for Action Recognition in Videos论文精读
Two-Stream Convolutional Networks for Action Recognition in Videos论文精读 大家好,今天我要讲的论文是一篇视频理解领域的开山之作,这是 ...
- TCP协议详细介绍
TCP报文格式: 字段介绍: 源/目的端口:用来标识主机上的程序 序号(seq):4个byte,指当前tcp报文段中第一个字节的序号(tcp报文中每个字节都有一个编号) 确认号(ack):4个byte ...