大模型向量数据库去重的N种实现方案!
简单来说,“向量”Vector 是大模型(LLM)在搜索时使用的一种“技术手段”,通过向量比对,大模型能找出问题的相关答案,并且进行智能回答。
向量简介
Vector 是向量或矢量的意思,向量是数学里的概念,而矢量是物理里的概念,但二者描述的是同一件事。
定义:向量是用于表示具有大小和方向的量。
向量可以在不同的维度空间中定义,最常见的是二维和三维空间中的向量,但理论上也可以有更高维的向量。例如,在二维平面上的一个向量可以写作 (x,y),这里 x 和 y 分别表示该向量沿两个坐标轴方向上的分量;而在三维空间里,则会有一个额外的 z 坐标,即 (x,y,z)。
例如,有以下 4 种狗,我们要在大模型中如何表示它们呢:

我们就可以使用向量来表示,如下图所示:
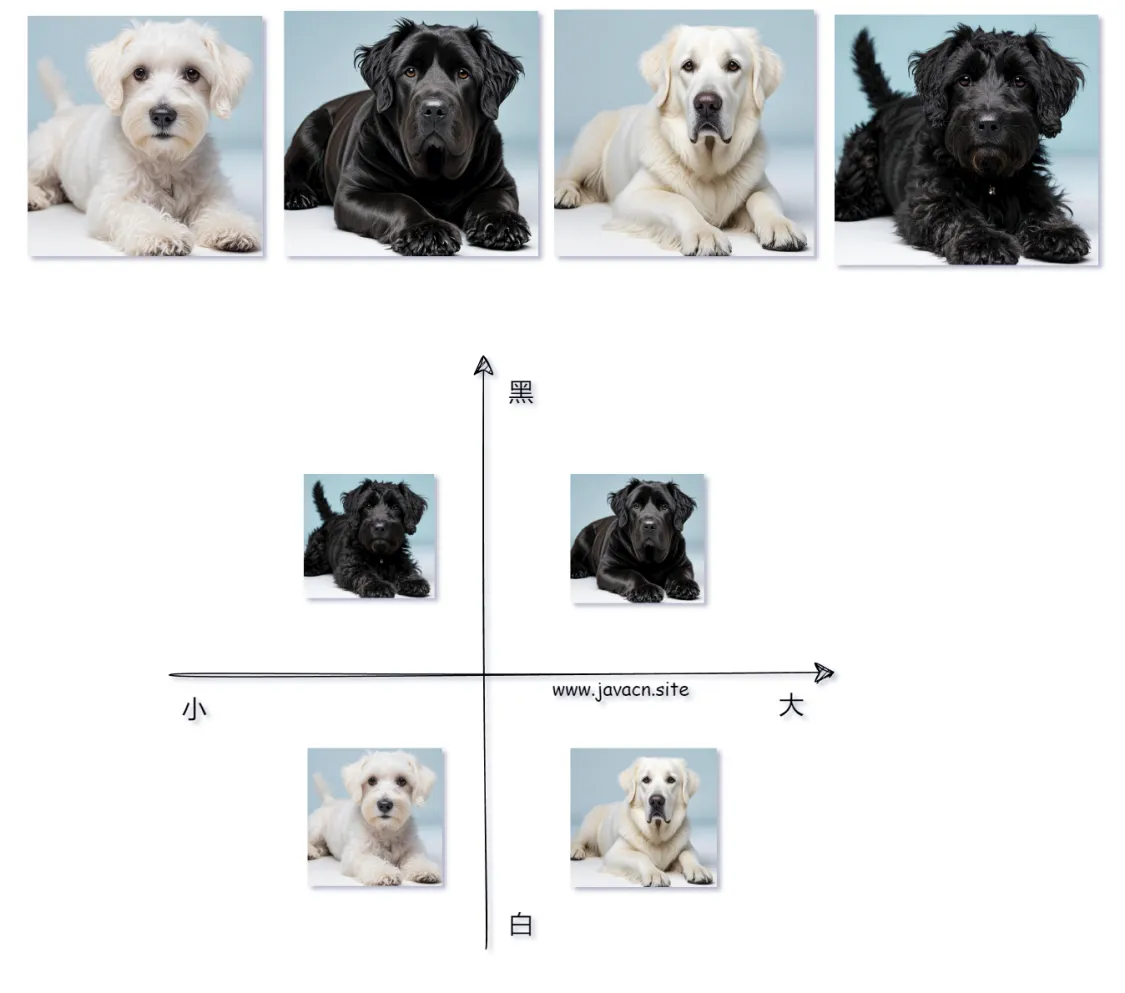
向量关系图:
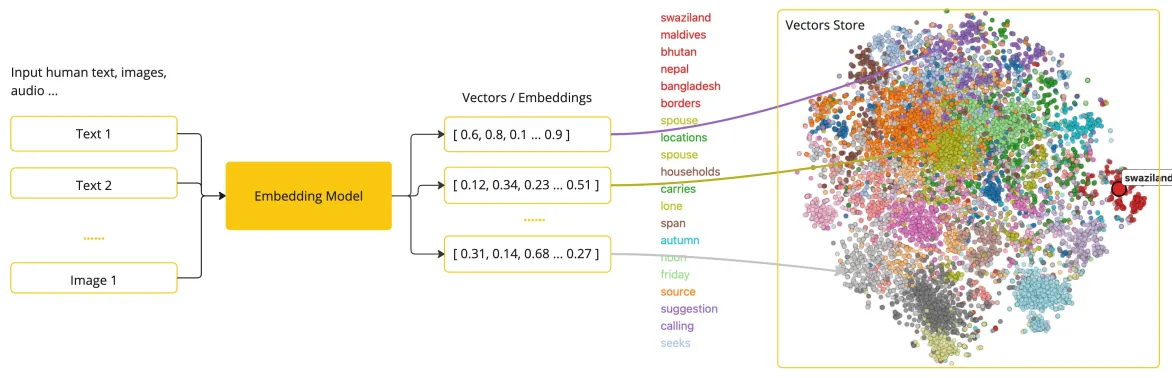
向量数据库
定义:向量数据库是一种专门用于存储、管理和检索向量数据(即高维数值数组)的数据库系统。其核心功能是通过高效的索引结构和相似性计算算法,支持大规模向量数据的快速查询与分析。
向量数据库以向量为基本存储单元,这些向量通常由文本、图像、音频等非结构化数据通过深度学习模型(如 Embedding 技术)转换而来,每个向量代表对象在多维空间中的特征。例如,一段文本可转化为 512 维的浮点数向量,用于表示其语义信息。
向量数据库维度越高,查询精准度也越高,查询效果也越好。
常用向量数据库
Java 领域常用的向量数据库有:
- Redis Stack:原有 Redis 服务升级之后就可以用来存储向量数据。
- Elastic Search
- Milvus:一款开源的高性能向量数据库,专为存储、索引和检索大规模向量数据而设计。它可以实现万亿级向量的毫秒级相似性搜索。
向量数据去重
向量数据库去重通常是在添加时进行判断,它主要实现方式有以下几种:
- 基于向量相似度去重。
- 基于 Redis 唯一键去重。
- 使用 Redis SetNX 去重。
- 基于 Redis Set 数据结构去重。
具体实现如下。
1.基于向量相似度去重
原理:在插入前计算新向量与已有向量的余弦相似度,若超过阈值(如 0.95)则视为重复。
EmbeddingSearchRequest request = EmbeddingSearchRequest.builder()
.queryEmbedding(newEmbedding)
.maxResults(1)
.minScore(0.95) // 相似度阈值
.build();
List<EmbeddingMatch<TextSegment>> matches = embeddingStore.search(request);
if (matches.isEmpty()) {
embeddingStore.add(newEmbedding, textSegment);
}
优点:语义级去重,适合文本内容相似但表述不同的场景。
缺点:存在线程安全问题,多任务同时执行,可能导致插入重复数据。
2.基于 Redis 唯一键去重
原理:使用文本内容的哈希值(如 MD5)作为 Redis Key 的一部分,确保唯一性。
String textHash = DigestUtils.md5Hex(textSegment.text());
String redisKey = "embedding:" + textHash;
if (!redisTemplate.hasKey(redisKey)) {
embeddingStore.add(newEmbedding, textSegment);
redisTemplate.opsForValue().set(redisKey, "1");
}
优点:性能高,适合完全相同的文本内容。
缺点:存在线程安全问题,多任务同时执行,可能导致插入重复数据。
3.使用 Redis SetNX 去重
原理:使用 Redis 的 SETNX(set if not exists)命令,避免非原子性问题,它是先判断才插入,如果已经存在就不再插入了。
具体实现代码如下:
// 生成文本的唯一哈希(如 MD5)
String textHash = DigestUtils.md5Hex(textSegment.text());
String redisKey = "vector:" + textHash;
// 判断是否存在
Boolean isSet = redisTemplate.opsForValue()
.setIfAbsent(redisKey, "1");
if (Boolean.TRUE.equals(isSet)) {
// 键不存在,保存向量数据
embeddingStore.add(embedding, textSegment);
} else {
// 键已存在,跳过或报错
throw new RuntimeException("重复数据");
}
优点:性能高,不存在线程安全问题。
4.基于 Redis Set 数据结构去重
原理:Set 去重,将向量 ID 或文本哈希存入 Redis Set,插入前检查是否存在。
// 生成文本的唯一哈希(如 MD5)
String textHash = DigestUtils.md5Hex(textSegment.text());
if (redisTemplate.opsForSet().add("unique_embeddings", textHash) == 1) {
embeddingStore.add(newEmbedding, textSegment);
}
优点:简单高效,不存在线程安全问题。
缺点:需维护额外的 Set 数据结构。
小结
向量数据库去重一定是生产环境要做的事,它的解决方案也有很多,通常我们会选择一种高效、且没有线程安全的解决方案,例如 Redis SetNX 或 Set 数据结构来解决。
本文已收录到我的技术小站 www.javacn.site,其中包含的内容有:Spring AI、LangChain4j、MCP、Function Call、RAG、向量数据库、Prompt、多模态、向量数据库、嵌入模型等内容。
大模型向量数据库去重的N种实现方案!的更多相关文章
- Django 模型和数据库 总结
模型和数据库 模型 首先我们在创建一个model的时候,这个类都是继承自 django.db.models.Model, 各种Model Field类型 AutoField,自动增长的IntegerF ...
- 【ASP.NET Core】EF Core 模型与数据库的创建
大家好,欢迎收看由土星卫视直播的大型综艺节目——老周吹逼逼. 今天咱们吹一下 EF Core 有关的话题.先说说模型和数据库是怎么建起来的,说装逼一点,就是我们常说的 “code first”.就是你 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- MySQL数据库去重 SQL解决
MySQL数据库去重的方法 数据库最近有很多重复的数据,数据量还有点大,本想着用代码解决,后来发现用SQL就能解决,这里记录一下 看这条SQL DELETE consum_record FROM ...
- 玩转Django2.0---Django笔记建站基础六(模型与数据库)
第六章 模型与数据库 Django对各种数据库提供了很好的支持,包括:PostgreSQL.MySQL.SQLite和Oracle,而且为这些数据库提供了统一的调用API,这些API统称为ORM框架. ...
- Django中的模型(操作数据库)
目录 Django配置连接数据库 在Django中操作数据库 原生SQL语句操作数据库 ORM模型操作数据库 增删改查 后台管理 使用后台管理数据库 模型是数据唯一而且准确的信息来源.它包含您正在储存 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- 两个文件去重的N种姿势
最近利用shell帮公司优化挖掘关键词的流程,用shell替代了多个环节的操作,极大提高了工作效率. shell在文本处理上确有极大优势,比如多文本合并.去重等,但是最近遇到了一个难搞的问题,即两个大 ...
随机推荐
- Python内存管理机制和垃圾回收机制的简单理解
一.内存管理机制 1.由c开发出来的cpython 2.include / objests 3.需要下载python源码包 4.Pyobject:float PyVarObject: 5.在pytho ...
- 具体数学第六章习题选做(genshining)
11.对于 \(n\ge 0\),求以下式子的封闭形式. \[\sum_k(-1)^k{n\brack k} \] 由于 \[\sum{n\brack k}x^k=x^{\overline n} \] ...
- Iceberg 待学习链接
1.Iceberg事务特性解读 https://blog.csdn.net/naisongwen/article/details/123343566 2.FLink全链路时延-测量方式 https:/ ...
- IDEA 打开多个文件显示在多行Tab上
1.左上角选择Preferences 2.搜索Editor Tabs,右侧取消勾选Show tabs in one row
- nginx 简单实践:正向代理、反向代理【nginx 实践系列之二】
〇.前言 本文为 nginx 简单实践系列文章之二,主要简单实践了两个内容:正向代理.反向代理,仅供参考. 关于 Nginx 基础,以及安装和配置详解,可以参考博主过往文章: https://www. ...
- SQLServer--NOLOCK
介绍 NOLOCK从字面意思可以看出就是没有锁,表示这段sql不去考虑目前table的transaction lock,就是说加上NOLOCK后不受锁的限制读取数据,包括已修改未提交的数据,概念上类似 ...
- [国家集训队] happiness 题解
发现可以做如下建图: 对于前两组输入,从 \(s\) 向所有代表学生的点连一条边,容量为其学习文科的喜悦值:从所有代表学生的点向 \(t\) 连一条边,容量为其学习理科的最大值. 对于后四组输入,建两 ...
- SpringBoot+Mybatis-Plus使用多数据源
常见的使用Mybatis-Plus配置多数据源方式有两种:一种是通过java config的方式手动配置两个数据源,另一种方式便是使用 dynamic-datasource-spring-boot-s ...
- 最优化方法之AdaGrad、RMSProp、Adam
结论: 1.简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同 2.效果是:在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯 ...
- rgba颜色转换为十六进制
RGBA颜色转HEX 转换步骤: 先将r.g.b分别转换为十六进制,比如 r.g.b分别为 255,则转换后得到的为 FF.FF.FF 将a 乘以 255,然后获得的积的整数部分转换为十六进制,如 a ...