大数据之路Week08_day03 (Hive的动态分区和分桶)
一、动态分区
先来说说我对动态分区的理解与一些感受吧。
由于我们通过hive去查询数据的时候,实际还是查询HDFS上的数据,一旦一个目录下有很多文件呢?而我们去查找的数据也没有那么多,全盘扫描就会浪费很多时间和资源。
为了避免全盘扫描和提高查询效率,引入了分区的概念。
分区的展现形式,就是在HDFS上的多级目录展现。
分区又分为静态分区和动态分区,静态分区是我们在创建表的时候去手动创建分区,然后将文件load上去。
这样就会显得很麻烦,当我们数据量特别大而且是同一类型数据的时候,手动就会显得很麻烦,也很容易出错。
于是我们有了动态分区,使用 insert 去插入数据
在去使用动态分区的时候,我们首先需要开启动态分区。
开启动态分区支持
hive>set hive.exec.dynamic.partition=true; (一定要开启!!!!!)
设置严格动态分区
hive>set hive.exec.dynamic.partition.mode=nostrict;
设置最大可以分多少区
hive>set hive.exec.max.dynamic.partitions.pernode=1000;
当然,这里需要注意的一点就是,适当的分区可以提高我们的查询效率,但是过多的去分区,效果则会相反,因为分区多了,多级目录就会加深,去查询的时候就会将时间浪费在这个递归查询上面,反而会降低查询效率。
一般创建动态分区的时候,先将所有数据放在一个目录下,然后通过insert into ... select ... from ... 的方式将数据加载过去,自动创建
举例:(说那么多,不如实际操作记忆深刻)
首先我们先准备数据
1,小虎1,12,man,lol-book-moive,beijing:shangxuetang-shanghai:pudong
2,小虎2,13,boy,lol-book-moive,beijing:shangxuetang-shanghai:pudong
3,小虎3,13,man,lol-book-moive,beijing:shangxuetang-shanghai:pudong
4,小虎4,12,boy,lol-book-moive,beijing:shangxuetang-shanghai:pudong
5,小虎5,13,man,lol-book-moive,beijing:shangxuetang-shanghai:pudong
6,小虎6,13,boy,lol-book-moive,beijing:shangxuetang-shanghai:pudong
7,小虎7,13,man,lol-book-moive,beijing:shangxuetang-shanghai:pudong
8,小虎8,12,boy,lol-book-moive,beijing:shangxuetang-shanghai:pudong
9,小虎9,12,man,lol-book-moive,beijing:shangxuetang-shanghai:pudong
创建一个普通的表
create table stu_dy1_1
(
id int,
name string,
age int,
gender string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
将数据load到这个表中
load data local 'Linux本地文件目录' into table stu_dy1_1;
然后创建动态分区表
create table stu_dy1_2
(
id int,
name string,
likes array<string>,
address map<string,string>
)partitioned by(age int,gender string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
最后使用inset的方式将stu_dy1_1上的数据加载过来
from放在前面或者后面都可以
from stu_dy1_1
insert into stu_dy1_2 partition(age,gender)
select id,name,likes,address,age,gender 或者 insert into stu_dy1_2 partition(age,gender)
select id,name,likes,address,age,gender from stu_dy1_1
去HDFS上查看
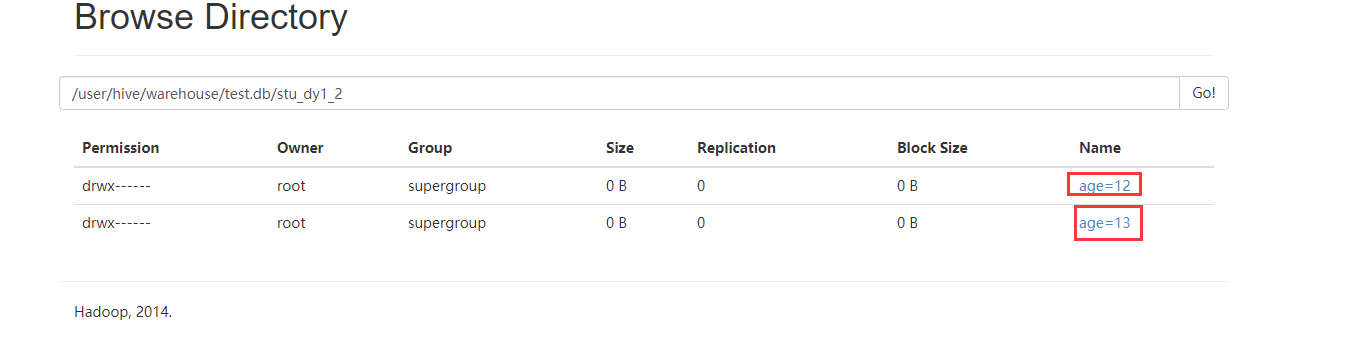
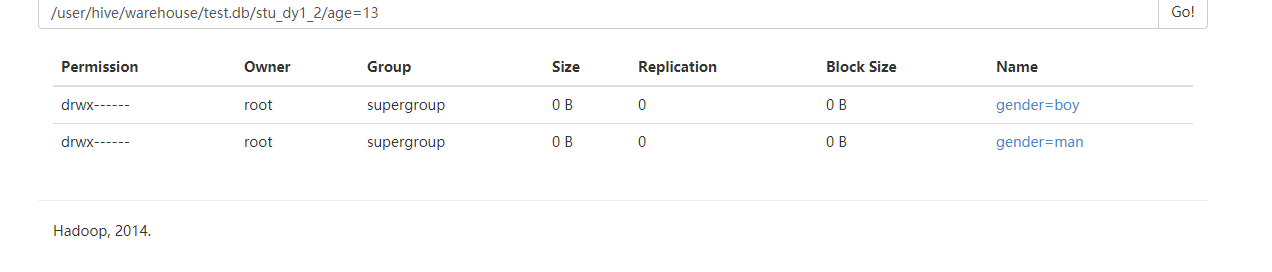
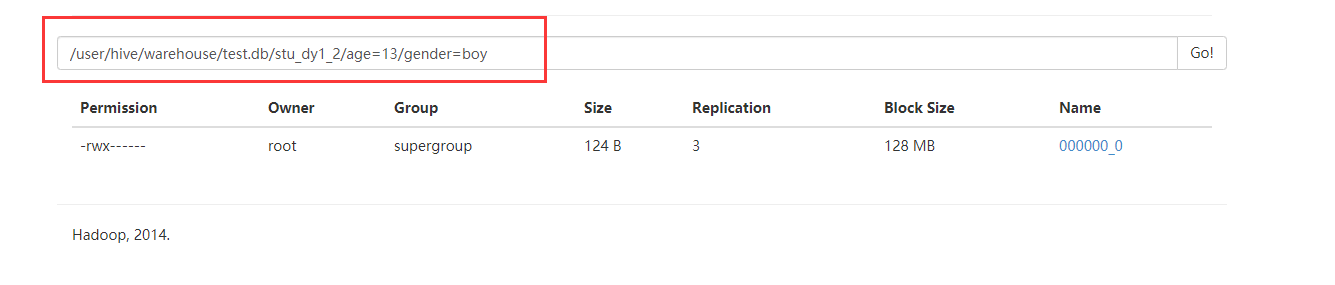
二、分桶
首先,分区和分桶是两个不同的概念,很多资料上说需要先分区在分桶,其实不然,分区是对数据进行划分,而分桶是对文件进行划分。
当我们的分区之后,最后的文件还是很大怎么办,就引入了分桶的概念。
将这个比较大的文件再分成若干个小文件进行存储,我们再去查询的时候,在这个小范围的文件中查询就会快很多。
对于hive中的每一张表、分区都可以进一步的进行分桶。
当然,分桶不是说将文件随机进行切分存储,而是有规律的进行存储。在看完下面的例子后进行解释,现在干巴巴的解释也不太好理解。它是由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
创建顺序和分区一样,创建的方式不一样。
举例:
首先我们依然需要开启分桶的支持:
set hive.enforce.bucketing=true; (依然十分重要,不然无法进行分桶操作!!!!)
数据准备:(id,name,age)
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88
创建一个普通的表
create table psn31
(
id int,
name string,
age int
)
row format delimited
fields terminated by ','
将数据load到这张表中
load data local '文件在Linux上的绝对路径' into table psn31;
创建分桶表
create table psn_bucket
(
id int,
name string,
age int
)
clustered by(age) into 4 buckets
row format delimited
fields terminated by ','
将数据insert到表psn_bucket中(注意:这里和分区表插入数据有所区别,分区表需要select 和指定分区,而分桶则不需要)
insert into psn_bucket select id,name,age from psn31;
去HDFS上查看数据
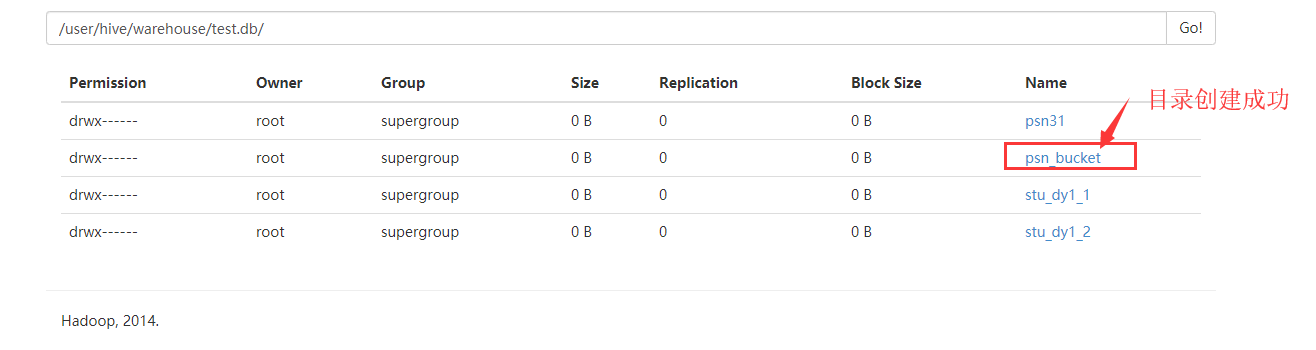
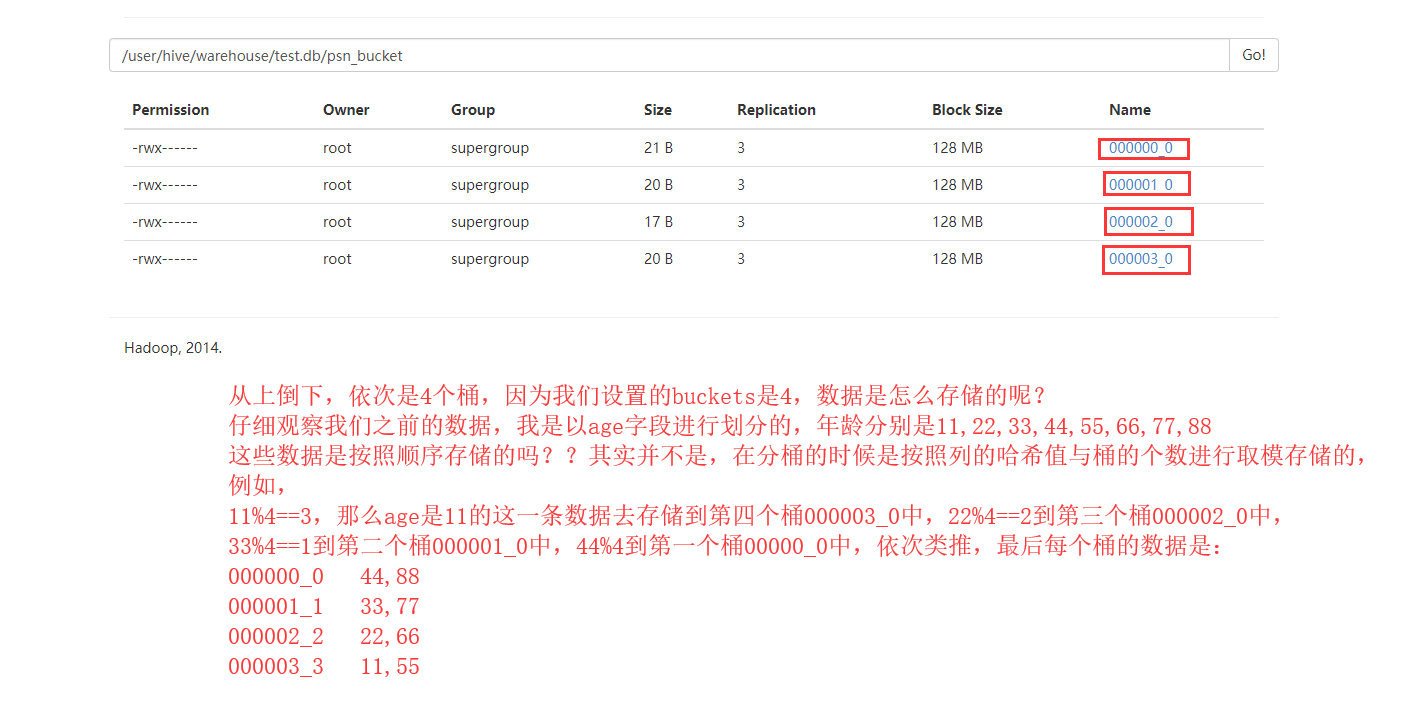
查询数据
我们在linux中使用Hadoop的命令查看一下(与我们猜想的顺序一致)
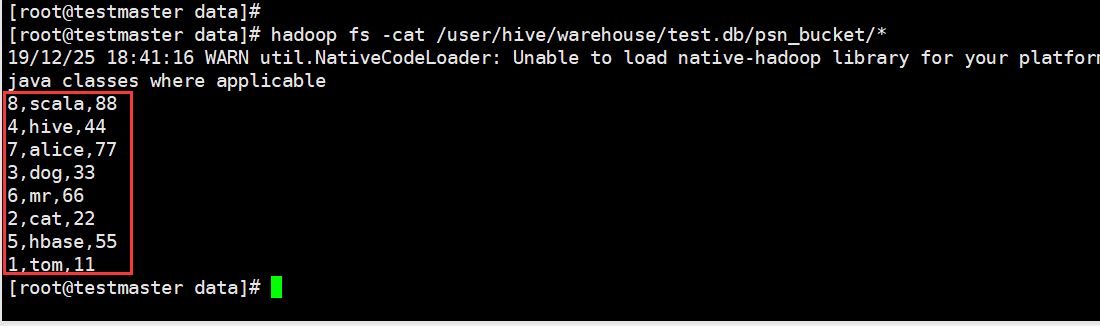
这里设置的桶的个数是4 数据按照 年龄%4 进行放桶(文件)
11%4 == 3 -----> 000003_0
22%4 == 2 -----> 000002_0
33%4 == 1 -----> 000001_0
44%4 == 0 -----> 000000_0
...以此类推
在HIve进行查询
select * from psn_bucket tablesample(bucket 2 out of 2);
随机取值(设置因子,桶的个数/因子)
这里就是取2号桶和4号桶,取2个
select * from psn_bucket tablesample(bucket 2 out of 4);
随机取值(设置因子,桶的个数/因子)
这里就是取2号桶,取一个
select * from psn_bucket tablesample(bucket 2 out of 8);
随机取值(设置倍数,倍数/桶的个数)
这里就是取2号桶 1/2个数据
取出来是一条数据
而我们一般取因子!!!
大数据之路Week08_day03 (Hive的动态分区和分桶)的更多相关文章
- Hive动态分区和分桶(八)
Hive动态分区和分桶 1.Hive动态分区 1.hive的动态分区介绍 hive的静态分区需要用户在插入数据的时候必须手动指定hive的分区字段值,但是这样的话会导致用户的操作复杂度提高,而且在 ...
- HIVE—索引、分区和分桶的区别
一.索引 简介 Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapRed ...
- 【HIVE】(2)分区表、二级分区、动态分区、分桶、抽样
分区表: 建表语句中添加:partitioned by (col1 string, col2 string) create table emp_pt(id int, name string, job ...
- Hive 表操作(HIVE的数据存储、数据库、表、分区、分桶)
1.Hive的数据存储 Hive的数据存储基于Hadoop HDFS Hive没有专门的数据存储格式 存储结构主要包括:数据库.文件.表.试图 Hive默认可以直接加载文本文件(TextFile),还 ...
- Hive里的分区、分桶、视图和索引再谈
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Hive(六)【分区表、分桶表】
目录 一.分区表 1.本质 2.创建分区表 3.加载数据到分区表 4.查看分区 5.增加分区 6.删除分区 7.二级分区 8.分区表和元数据对应得三种方式 9.动态分区 二.分桶表 1.创建分桶表 2 ...
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
随机推荐
- 面试官:DNS解析都整不明白,敢说你懂网络?我:嘤嘤嘤!
一.写在开头 在OSI七层协议模型中应用层是距离我们最近,且日后开发使用到最多的一层,在上一篇博文中我们已经学习了应用层中的HTTP协议,在本文中我们再一起来学一下DNS.啥?DNS不是很了解?那还不 ...
- Windows的树形目录结构
一.文件.文件夹(目录).逻辑盘.路径的概念 · 文件:是操作系统用来存储和管理信息的基本单位.每个文件都有一个名称,叫文件名.文件名通常由基本文件名和扩展名两部分组成,其中基本文件名用于说明文件 ...
- 【数据库】【MySQL】创建数据库、数据表、修改数据表字段的一些基本操作
这是一份作业,仅此而已. 代码仅供参考. # 创建数据库yggl_mllt9920 CREATE DATABASE yggl_mllt9920; # 选择数据库 USE yggl_mllt9920; ...
- 转载 Python 存储与读取HDF5文件
HDF5 简介 HDF(Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件.HDF 最早由美国国家超级计算应用中心 NCSA 开发,目前在非盈 ...
- Vue中this.$store.dispatch() 与 this.$store.commit()的区别
两者的区别 (1)this.$store.commit() commit: 同步操作 this.$store.commit('方法名',值)[存储] this.$store.state.方法名[取值] ...
- Spring+MyBatis企业应用实战(第二版)2018-电子书+源码+SQL脚本
Spring+MyBatis企业应用实战(第二版)2018学习资料: 电子书: 链接:https://pan.baidu.com/s/1yAdlA5F_HuZMbO4who5jVw 提取码:58yz ...
- (六).NET6.0通用读取配置文件功能
1.新增Microsoft.Extensions.Configuration包 在启动项目下,设置appsettings.json属性为始终复制 2.新建一个文件夹Common,用于存放工具类项目.并 ...
- Solution Set -「LGR-126」洛咕咕的 NOIP 模拟赛
机房在三楼, 不在五楼. 三楼确实有阶梯教室. 三楼向外望是一楼大厅屋顶所以看上去不高. 十一点前必须离开科技楼是因为爱因斯坦要锁大门. 我不会被自己写的东西清空 san 值. ...
- Kotlin:【泛型】
- ARM单片机知识点
1.STM32编译信息 代码占用FLASH 大小为:Code + RO-data, 7420字节(5054+2366),所用的RAM 大小为:RW-data + ZI-data, 8576(372+8 ...