『Python底层原理』--Python字典的实现机制
在Python中,字典(dict)是一种极为强大且常用的内置数据结构,它以键值对的形式存储数据,并提供了高效的查找、插入和删除操作。
接下来,我们将深入探究 Python 字典背后的实现机制,特别是其与哈希表的关系,以及在 CPython 中的具体实现。
1. 哈希表
字典用于存储 Python 中的键值对,为我们提供了快速访问和存储数据的方法。
哈希表(Hash Table)则是实现字典功能的核心技术之一。
本质上,哈希表是基于哈希函数的数据结构,通过将键映射到特定索引位置,实现快速数据访问。
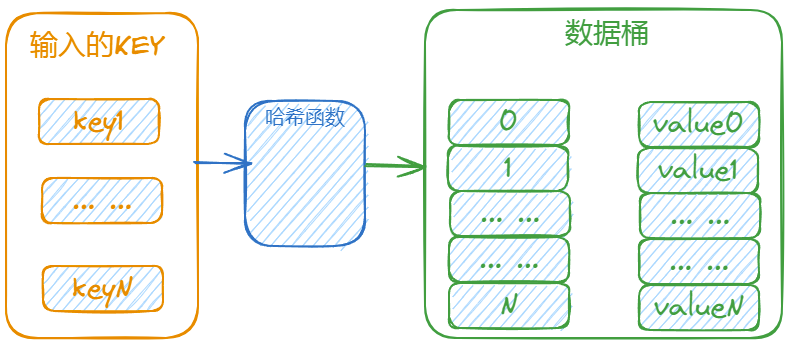
Python 字典正是利用哈希表这一特性,把键值对存储在哈希表中,让我们能通过键迅速获取对应的值。
2. 实现原理
在Python中,字典通过哈希表实现其功能。
具体来说,字典的键被传递给一个哈希函数,该函数计算出一个哈希值。
然后,这个哈希值被用来确定键值对在内存中的存储位置。
当需要查找某个键对应的值时,字典会再次计算该键的哈希值,并直接定位到存储位置,从而快速返回对应的值。
2.1. 存储方式
Python字典的存储方式基于一个动态数组,其中每个元素是一个键值对的引用。
这个数组的大小会根据字典的负载因子(Load Factor)动态调整。
负载因子是字典中存储的键值对数量与哈希表大小的比值,当负载因子超过一定阈值(如0.66)时,哈希表会扩容,以避免过多的哈希冲突,从而保持高效的查找性能。
2.2. 哈希冲突
哈希冲突是哈希表中不可避免的问题。
在Python字典中,哈希冲突通过“开放寻址法”解决。
当两个键的哈希值映射到同一个存储位置时,字典会寻找下一个空闲的位置来存储冲突的键值对。
这种方法称为“线性探测”,如果连续的位置都被占用,字典会继续寻找,直到找到一个空闲位置。
这种策略虽然简单,但在某些情况下可能会导致性能下降,尤其是在哈希表接近满载时。
2.3. 字典性能
字典的性能主要取决于哈希函数的质量和哈希表的负载因子。
在理想情况下,字典的查找、插入和删除操作的平均时间复杂度为O(1)。
然而,在最坏情况下(如大量哈希冲突),时间复杂度可能会退化到O(n)。
为了避免这种情况,Python字典会动态调整哈希表的大小,以保持较低的负载因子。
3. CPython中的字典实现
在CPython的源代码中,字典的实现位于Objects/dictobject.c文件中。
这个文件包含了字典的所有核心操作,如初始化、查找、插入和删除等。
比如字典创建的代码:
static PyObject *
dict_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
assert(type != NULL);
assert(type->tp_alloc != NULL);
// dict subclasses must implement the GC protocol
assert(_PyType_IS_GC(type));
PyObject *self = type->tp_alloc(type, 0);
if (self == NULL) {
return NULL;
}
PyDictObject *d = (PyDictObject *)self;
d->ma_used = 0;
d->_ma_watcher_tag = 0;
dictkeys_incref(Py_EMPTY_KEYS);
d->ma_keys = Py_EMPTY_KEYS;
d->ma_values = NULL;
ASSERT_CONSISTENT(d);
if (!_PyObject_GC_IS_TRACKED(d)) {
_PyObject_GC_TRACK(d);
}
return self;
}
字典对象由PyDictObject结构体定义(Include/cpython/dictobject.h):
typedef struct {
PyObject_HEAD
// 省略...
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is split:
keys are stored in ma_keys and values are stored in ma_values */
PyDictValues *ma_values;
} PyDictObject;
其中,PyDictKeysObject是一个存储键值对的数组。
// 位于文件:Include/cpython/dictobject.h
typedef struct _dictkeysobject PyDictKeysObject;
// 位于文件:Include/internal/pycore_dict.h
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
// 省略...
};
在CPython中,字典的实现采用了紧凑的内存布局,以减少内存浪费。
每个键值对都被存储在一个结构体中,而这些结构体则被存储在一个动态数组中。
当需要扩容时,字典会重新分配一个更大的数组,并将所有键值对重新哈希到新的数组中。
这种实现方式虽然在扩容时会带来一定的性能开销,但通过合理的负载因子控制,可以有效避免频繁的扩容操作。
4. 字典的应用场景
Python字典作为一种高效的数据结构,在实际开发中有着广泛的应用。
下面列举一些从实际项目中摘取的一些使用字典的代码片段。
4.1. 存储配置信息
字典是存储配置信息的理想选择,因为它允许通过键快速访问对应的值。
比如,在一个Web应用程序中,我们经常使用字典来存储数据库配置、API密钥或其他运行时参数:
config = {
"database": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "password"
},
"api_keys": {
"google_maps": "YOUR_GOOGLE_MAPS_API_KEY",
"weather": "YOUR_WEATHER_API_KEY"
}
}
# 访问配置
db_host = config["database"]["host"]
api_key = config["api_keys"]["google_maps"]
这种方式不仅清晰易懂,还便于后续的修改和扩展。
4.2. 缓存数据
字典的高效查找特性使其非常适合用作缓存机制。通过将计算结果存储在字典中,可以避免重复计算,从而显著提高程序的性能。
例如,以下代码展示了如何使用字典缓存斐波那契数列的计算结果:
cache = {}
def fibonacci(n):
if n in cache:
return cache[n]
if n <= 1:
return n
cache[n] = fibonacci(n - 1) + fibonacci(n - 2)
return cache[n]
# 使用缓存
print(fibonacci(30)) # 计算速度快,且避免了重复计算
在上述代码中,cache字典存储了已经计算过的斐波那契数,从而避免了重复计算,显著提高了程序的运行效率。
4.3. 对象属性存储
在某些场景下,字典可以用来模拟对象的属性存储,特别是当需要动态添加或删除属性时。
例如,可以使用字典来实现一个简单的动态对象:
class DynamicObject:
def __init__(self):
self.__dict__ = {}
def __getattr__(self, name):
return self.__dict__.get(name)
def __setattr__(self, name, value):
self.__dict__[name] = value
# 使用动态对象
obj = DynamicObject()
obj.name = "Alice"
obj.age = 25
print(obj.name) # 输出: Alice
print(obj.age) # 输出: 25
这种方式允许在运行时动态地添加和访问属性,提供了极大的灵活性。
4.4. 计数器
字典可以用来统计元素的出现次数,例如在文本处理中统计单词的频率。
以下代码展示了如何使用字典实现一个简单的单词计数器:
text = "hello world hello Python world"
word_count = {}
for word in text.split():
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
print(word_count) # 输出: {'hello': 2, 'world': 2, 'Python': 1}
通过字典的键值对结构,可以轻松地统计每个单词的出现次数,并且查找和更新操作都非常高效。
4.5. 状态管理
在复杂的应用程序中,字典可以用来管理状态信息。
例如,在一个游戏开发场景中,可以使用字典来存储玩家的状态:
player_state = {
"health": 100,
"score": 0,
"inventory": ["sword", "shield", "potion"]
}
# 更新玩家状态
player_state["health"] -= 10
player_state["score"] += 50
player_state["inventory"].append("magic wand")
print(player_state)
# 输出: {'health': 90, 'score': 50, 'inventory': ['sword', 'shield', 'potion', 'magic wand']}
这种方式使得状态管理清晰且易于维护。
4.6. 数据映射
字典可以用来实现数据映射,例如将用户ID映射到用户信息。
以下代码展示了如何使用字典存储和访问用户信息:
users = {
1: {"name": "Alice", "email": "alice@example.com"},
2: {"name": "Bob", "email": "bob@example.com"},
3: {"name": "Charlie", "email": "charlie@example.com"}
}
# 访问用户信息
user_id = 2
user_info = users.get(user_id)
print(user_info) # 输出: {'name': 'Bob', 'email': 'bob@example.com'}
通过字典的键值对结构,可以快速地根据用户ID获取用户信息,而无需遍历整个数据集。
4.7. 配置路由
在Web开发中,字典可以用来配置路由,将URL路径映射到对应的处理函数。
以下是一个简单的路由配置示例:
routes = {
"/home": home_page,
"/about": about_page,
"/contact": contact_page
}
def home_page():
return "Welcome to the Home Page!"
def about_page():
return "About Us"
def contact_page():
return "Contact Information"
# 处理请求
def handle_request(path):
handler = routes.get(path)
if handler:
return handler()
else:
return "404 Not Found"
print(handle_request("/home")) # 输出: Welcome to the Home Page!
通过字典的映射关系,可以快速地根据路径找到对应的处理函数,从而实现高效的路由管理。
5. 总结
总之,Python 字典凭借高效的存储和检索特性,成为 Python 编程不可或缺的数据结构。
深入了解 Python 字典,能让我们更好地利用这一强大的数据结构,编写出更高效、简洁的 Python 代码。
无论是小型脚本,还是大型项目开发,字典都将发挥重要作用。
『Python底层原理』--Python字典的实现机制的更多相关文章
- 操作系统底层原理与Python中socket解读
目录 操作系统底层原理 网络通信原理 网络基础架构 局域网与交换机/网络常见术语 OSI七层协议 TCP/IP五层模型讲解 Python中Socket模块解读 TCP协议和UDP协议 操作系统底层原理 ...
- 『无为则无心』Python日志 — 64、Python日志模块logging介绍
目录 1.日志的作用 2.为什么需要写日志 3.Python中的日志处理 (1)logging模块介绍 (2)logging模块的四大组件 (3)logging日志级别 1.日志的作用 从事与软件相关 ...
- 『无为则无心』Python函数 — 34、lambda表达式
目录 1.lambda的应用场景 2.lambda语法 3.快速入门 4.示例:计算a + b 5.lambda的参数形式 6.lambda的应用 lambda表达式的主要作用就是化简代码. 匿名函数 ...
- 『无为则无心』Python基础 — 3、搭建Python开发环境
目录 1.Python开发环境介绍 2.Python解释器的分类 3.下载Python解释器 4.安装Python解释器 5.Python解释器验证 1.Python开发环境介绍 所谓"工欲 ...
- 『无为则无心』Python基础 — 4、Python代码常用调试工具
目录 1.Python的交互模式 2.IDLE工具使用说明 3.Sublime3工具的安装与配置 (1)Sublime3的安装 (2)Sublime3的配置 4.使用Sublime编写并调试Pytho ...
- 『无为则无心』Python面向对象 — 46、类和对象
目录 1.理解类和对象 2.类 3.对象 4.Python中的对象 5.类和对象的定义 (1)定义类 (2)创建对象 (3)练习 6.拓展:isinstance() 函数 1.理解类和对象 (1)类和 ...
- 『无为则无心』Python序列 — 21、Python字典及其常用操作
目录 1.字典的应用场景 2.字典的概念 3.创建字典的语法 4.字典常见操作 (1)字典的增加操作 (2)字典的删除操作 (3)字典的修改 (4)字典的查找 (5)copy()复制 1.字典的应用场 ...
- python底层原理
有同学问到了一个问题,python中存储变量是通过内存地址来存储,那么python又是如何去判断内存中的地址是什么数据类型的呢.经过查找,找到这篇文章: 原博客地址:http://www.cnblog ...
- Python 底层原理知识
1.Python是如何进行内存管理的? 答:从三个方面来说,一对象的引用计数机制,二垃圾回收机制,三内存池机制 一.对象的引用计数机制 Python内部使用引用计数,来保持追踪内存中的对象,所有对象都 ...
- 『无为则无心』Python基础 — 2、编译型语言和解释型语言的区别
目录 1.什么是计算机语言 2.高级语言中的编译型语言和解释型语言 (1)编译型语言 (2)解释型语言 (3)编译型语言和解释型语言执行流程 3.知识扩展: 4.关于Python 1.什么是计算机语言 ...
随机推荐
- sed 指定行后或行前插入
sed 功能非常强大,这里主要列出一些工作中常用到的举例,以后再追加 示例文本 example.cfg Config = { a = 1, b = 1024, c = { ErrLevel = 4, ...
- 抛出 NoClassDefFoundError: javax/validation/constraints/Size 问题的解决方法
Error:java: java.lang.NoClassDefFoundError: javax/validation/constraints/Size 问题很明显,找不到相关类.我们可以在 pom ...
- 龙哥量化:MACD指标的金叉死叉,这样使用更准确(图解)
如果您需要代写技术指标公式, 请联系我. 龙哥QQ:591438821 龙哥微信:Long622889 本文的策略过于简单,你可以加一些更复杂的限制条件 1.水上金叉,可看涨; 2.水上死叉,是洗盘; ...
- Qt数据库应用11-通用数据生成器
一.前言 有两种应用场景需要用到数据生成器,一种是需要测试数据库性能,比如在100万条和1000万条记录的时候对比查询或更新语句执行耗时,一种是随机模拟生成一堆数据,用来测试程序的性能,看下程序中到了 ...
- [转]C++中strcpy()函数和strcpy_s()函数的使用及注意事项
原文链接:C++中strcpy()函数和strcpy_s()函数的使用及注意事项
- 🎉 夜莺监控突破一万 star,这是汗水,也是鞭策
夜莺监控项目在上周突破了一万 star,算是一个小小的里程碑.在开源领域,通常把 star 数量看作项目的繁荣指标,star 数量越多,说明愿意关注你的人越多.这个数字的背后,是一群人对你的鼓励.认可 ...
- 重温Go语法笔记 | 容器
容器 数组的声明 // 初始化声明 q := [...]int{1,2,3} // 仅声明 var a [3]int 切片 切片的概念 对数组连续片段的引用 // 根据数组生成切片 var a = [ ...
- TestProject 使用汇总
1. 截图 from addons.screenshot_utils import ScreenshotUtils step_output = driver.addons().execute( Scr ...
- 基于Windows环境的Kafka搭建与.NET实战开发案例
前言:基于Windows环境下的Kafka搭建(scal+zookeeper+Kafka+可视化工具).以及使用.NET6.0进行简单的生产者与消费者的演示 一.环境部署 Kafka是使用Java语言 ...
- VBA 解析 json
Sub Macro1() Debug.Print "999" Dim FilePath, strData FilePath = "C:\Git\Test\JenProje ...