spark 2.x在windows环境使用idea本地调试启动了kerberos认证的hive
1 概述
开发调试spark程序时,因为要访问开启kerberos认证的hive/hbase/hdfs等组件,每次调试都需要打jar包,上传到服务器执行特别影响工作效率,所以调研了下如何在windows环境用idea直接跑spark任务的方法,本文旨在记录配置本地调试环境中遇到的问题及解决方案。
2 环境
Jdk 1.8.0
Spark 2.1.0
Scala 2.11.8
Hadoop 2.6.0-cdh5.12.1
Hive 1.1.0-cdh5.12.1
环境搭建略,直接看本地调试spark程序遇到的问题。
注意:若要访问远端hadoop集群服务,需将hosts配置到windows本地。
3 测试代码
测试主类,功能spark sql读取开启Kerberos认证的远端hive数据
import org.apache.spark.sql.SparkSession
object SparkTest{
def main(args: Array[String]): Unit = {
//kerberos认证
initKerberos()
val spark = SparkSession.builder().master("local[2]").appName("SparkTest")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show()
spark.sql("use testdb")
spark.sql("show tables").show()
val sql = "select * from infodata.sq_dim_balance where dt=20180625 limit 10"
spark.sql(sql).show()
spark.stop()
}
def initKerberos(): Unit ={
//kerberos权限认证
val path = RiskControlUtil.getClass.getClassLoader.getResource("").getPath
val principal = PropertiesUtil.getProperty("kerberos.principal")
val keytab = PropertiesUtil.getProperty("kerberos.keytab")
val conf = new Configuration
System.setProperty("java.security.krb5.conf", path + "krb5.conf")
conf.addResource(new Path(path + "hbase-site.xml"))
conf.addResource(new Path(path + "hdfs-site.xml"))
conf.addResource(new Path(path + "hive-site.xml"))
conf.set("hadoop.security.authentication", "Kerberos")
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem")
UserGroupInformation.setConfiguration(conf)
UserGroupInformation.loginUserFromKeytab(principal, path + keytab)
println("login user: "+UserGroupInformation.getLoginUser())
}
}
4 问题及解决方案
4.1 问题1
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
winutils.exe是在Windows系统上需要的hadoop调试环境工具,里面包含一些在Windows系统下调试hadoop、spark所需要的基本的工具类
出现上面的问题,可能是因为windows环境下缺少winutils.exe文件或者版本不兼容的原因。
解决办法:
(1)下载winutils,注意需要与hadoop的版本相对应。
hadoop2.6版本可以在这里下载https://github.com/amihalik/hadoop-common-2.6.0-bin
由于配置的测试集群是hadoop2.6,所以我在这里下载的是2.6.0版本的。下载后,将其解压,包括:hadoop.dll和winutils.exe
(2)配置环境变量
①增加系统变量HADOOP_HOME,值是下载的zip包解压的目录,我这里解压后将其重命名为hadoop-common-2.6.0
②在系统变量path里增加%HADOOP_HOME%\bin
③重启电脑,使环境变量配置生效,上述问题即可解决。
添加系统变量HADOOP_HOME
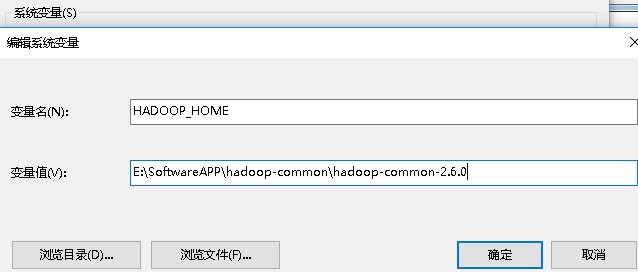
编辑系统变量Path,添加%HADOOP_HOME%\bin;

4.2 问题2
如果hadoop集群开启了kerberos认证,本地调试也需要进行认证,否则会报权限错误;
将权限相关配置文件放入工程的resource目录,如下所示
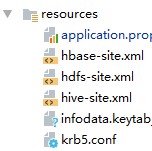
认证代码如下:
def initKerberos(): Unit ={
//kerberos权限认证
val path = RiskControlUtil.getClass.getClassLoader.getResource("").getPath
val principal = PropertiesUtil.getProperty("kerberos.principal")
val keytab = PropertiesUtil.getProperty("kerberos.keytab")
val conf = new Configuration
System.setProperty("java.security.krb5.conf", path + "krb5.conf")
conf.addResource(new Path(path + "hbase-site.xml"))
conf.addResource(new Path(path + "hdfs-site.xml"))
conf.addResource(new Path(path + "hive-site.xml"))
conf.set("hadoop.security.authentication", "Kerberos")
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem")
UserGroupInformation.setConfiguration(conf)
UserGroupInformation.loginUserFromKeytab(principal, path + keytab)
println("login user: "+UserGroupInformation.getLoginUser())
}
4.3 问题3
Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
网上说目前错误的解决办法还没有解决,采用一种临时的方式来解决,解决的办法是:通过下载你的CDH的版本的源码(http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.12.1-src.tar.gz),
在对应的文件下,hadoop2.6.0-cdh5.12.1-src\hadoop-common-project\hadoop- common\src\main\java\org\apache\hadoop\io\nativeio下NativeIO.java 复制到对应的Eclipse的project(复制的过程中需要注意一点,就是在当前的工程下创建相同的包路径,这里的包路径org.apache.hadoop.io.nativeio再将对应NativeIO.java文件复制到对应的包路径下即可。)
Windows的唯一方法用于检查当前进程的请求,在给定的路径的访问权限,所以我们先给以能进行访问,我们自己先修改源代码,return true 时允许访问。修改NativeIO.java文件中的557行的代码,如下所示:
源代码如下:
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return access0(path, desiredAccess.accessRight());
}
修改后的代码如下:
public static boolean access(String path, AccessRight desiredAccess)
throws IOException {
return true;
//return access0(path, desiredAccess.accessRight());
}
再次执行,这个错误修复。
4.4 问题4
Caused by: java.io.FileNotFoundException: File /tmp/hive does not exist
这个错误是说临时目录/tmp/hive需要有全部权限,即777权限,创建/tmp/hive 目录,用winutils.exe对目录赋权,如下
C:\>D:\spark_hadoop\hadoop-common\hadoop-common-2.6.0\bin\winutils.exe chmod -R 777 D:\tmp\hive
C:\>D:\spark_hadoop\hadoop-common\hadoop-common-2.6.0\bin\winutils.exe chmod -R 777 \tmp\hive
4.5 问题5
Exception in thread "main" java.lang.NoSuchFieldError: METASTORE_CLIENT_SOCKET_LIFETIME
OR
Exception in thread "main" java.lang.IllegalArgumentException: Unable to instantiate SparkSession with Hive support because Hive classes are not found
原因是spark sql 读取hive元数据需要的字段METASTORE_CLIENT_SOCKET_LIFETIME hive1.2.0开始才有,而我们引用的cdh版本的hive为1.1.0-cdh5.12.1,没有该字段,故报错。
Spark SQL when configured with a Hive version lower than 1.2.0 throws a java.lang.NoSuchFieldError for the field METASTORE_CLIENT_SOCKET_LIFETIME because this field was introduced in Hive 1.2.0 so its not possible to use Hive metastore version lower than 1.2.0 with Spark. The details of the Hive changes can be found here: https://issues.apache.org/jira/browse/HIVE-9508
解决方法,引入第三方依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.1.0</version>
</dependency>
4.6 问题6
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvider,org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory
解决方法,将window idea引入的hive-site.xml进行如下修改
<!--<property>-->
<!--<name>hive.security.authorization.manager</name>-->
<!--<value>org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvider,org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>-->
<!--</property>-->
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.DefaultHiveAuthorizationProvider</value>
</property>
5 总结
总结重要的几点就是:
(1) 配置HADOOP_HOME,内带winutils.exe 和 hadoop.dll 工具;
(2) 引入hive-site.xml等配置文件,开发kerberos认证逻辑;
(3) 本地重写NativeIO.java类;
(4) 给临时目录/tmp/hive赋予777权限;
(5) 引入第三方依赖spark-hive_2.11,要与spark版本对应;
(6) 本地hive-site.xml将hive.security.authorization.manager改为默认manager
最后提醒一点,本地调试只是问了开发阶段提高效率,避免每次修改都要打包提交到服务器运行,但调试完,还是要打包到服务器环境运行测试,没问题才能上线。
至此,spark本地调试程序配置完成,以后就可以愉快地在本地调试spark on hadoop程序了。
6 参考
https://abgoswam.wordpress.com/2016/09/16/getting-started-with-spark-on-windows-10-part-2/
spark 2.x在windows环境使用idea本地调试启动了kerberos认证的hive的更多相关文章
- MemCache在Windows环境下的搭建及启动
MemCache在Windows环境下的搭建及启动 一.memcache服务器端的安装 1.下载memcached的安装包,memcached_en32or64.zip,下载链接:http://pan ...
- windows 环境下通过运行快速启动程序
在windows环境下,我们可以使用一些系统内置的快捷键来快速启动我们想要的应用程序,我这里举例几个我经常使用的,比如: 快捷键 功能说明 services.msc 查看系统服务 gpedit.ms ...
- Windows环境下,本地Oracle创建dblink连接远程mysql
前言 我的情况是,本地安装了oracle(安装完成后带有SQL Developer,不需要再安装instantclient),创建dblink去连接远程的mysql.有些朋友可能是 本地使用PL\SQ ...
- 在windows环境下实现开机延迟启动tomcat
如果说我们的服务器断电了 开机之后还需要手动开下服务 还需要远程连接上 然后一个一个开启 是不是很麻烦 我们可以写一个bat脚本 然后设置开机5分钟之后启动tomcat 首先配置环境变量: ...
- 【原创】K8S环境下研发如何本地调试?kt-connect使用详解
K8S环境下研发如何本地调试?kt-connect使用详解 背景 注:背景有点啰嗦,讲讲一路走来研发本地调试的变化,嫌烦的可以直接跳过,不影响阅读. 2019年 我在的公司当时是个什么情况,只有两个J ...
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
http://blog.csdn.net/xiefu5hh/article/details/51707529 Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例[附 ...
- Windows环境下在IDEA编辑器中spark开发安装步骤
以下是windows环境下安装spark的过程: 1.安装JDK(version:1.8.0.152) 2.安装scala(version:2.11/2.12) 3.安装spark(version:s ...
- Windows环境部署并调试pyspark(一)
准备: windows环境说明:Python2.7 + pipspark版本:spark-1.6.1-bin-hadoop2.6 step1: 下载并解压tar包到自定义的路径.(下载链接 https ...
- spark JAVA 开发环境搭建及远程调试
spark JAVA 开发环境搭建及远程调试 以后要在项目中使用Spark 用户昵称文本做一下聚类分析,找出一些违规的昵称信息.以前折腾过Hadoop,于是看了下Spark官网的文档以及 github ...
随机推荐
- leveldb原理和使用
LevelDB是一个基于本地文件的存储引擎,非分布式存储引擎,原理基于BigTable(LSM文件树),无索引机制,存储条目为Key-value.适用于保存数据缓存.日志存储.高速缓存等应用,主要是避 ...
- protobuf反射详解
本文主要介绍protobuf里的反射功能,使用的pb版本为2.6.1,同时为了简洁,对repeated/extension字段的处理方法没有说明. 最初是起源于这样一个问题: 给定一个pb对象,如何自 ...
- c语言学习笔记(8)——函数
学完c语言的函数可以理解面向过程的语言 函数是c语言的重点 一.为什么需要函数? 1.避免了重复性操作 2.有利于程序的模块化(每一个功能可以用不同函数去实现) 二.什么叫做函数? 逻辑上:能够完成特 ...
- 分布式高级(十三)Docker Container之间的数据共享
sudo docker run -it -v /usr/lib:/usr/lib/dbdata --name dbcontainer-192.168.1.184 ubuntu:14.04 sudo d ...
- DDD实战10 在项目中使用JWT的token
在使用过程中报过一个错误:The algorithm: 'HS256' requires the SecurityKey.KeySize to be greater than '128' bits 是 ...
- AWS核心服务概览
1.Amazon Web Service 应该可以说,Amazon Web Service目前是云计算领域的领头羊,其业务规模.开发水平和盈利能力在业界内都是首屈一指的.从本科毕业离开学校就一直做Ja ...
- 在实现视频播放器的步骤client(三)风行网络电影列表
(三) 今日热门电影实现这个功能.主要从server获取数据.然后显示在屏幕上.虽然说是从这个server获取电影信息数据,但,不实际的http相关知识,我们直接sdk包(56网络提供api),你将能 ...
- C# 操作XML文档 使用XmlDocument类方法
W3C制定了XML DOM标准.很多编程语言中多提供了支持W3C XML DOM标准的API.我在之前的文章中介绍过如何使用Javascript对XML文档进行加载与查询.在本文中,我来介绍一下.Ne ...
- WPF支持OneWay,TwoWay,OneTime,Default和OneWayToSource
原文:WPF支持OneWay,TwoWay,OneTime,Default和OneWayToSource 无论是目标属性还是源属性,只要发生了更改,TwoWay 就会更新目标属性或源属性. OneWa ...
- 投资人的能量往往大多远远不仅于此,他能站在不同的角度和高度看问题(要早点拿投资,要舍得让出股份)——最好不要让 Leader 一边做技术、一边做管理,人的能力是有限的,精力也是有限的
摘要:在创业三年时间里作为联合创始人,虽然拿着大家均等的股份,我始终是没有什么话语权的,但是,这也给了我从旁观者的角度看清整个局面的机会.创业公司的成败绝大程度取决于技术大牛和公司 Leader, ...