掌握Spark机器学习库-09.3-kmeans算法实现分类
数据集
iris.data
数据集概览
代码
package org.apache.spark.examples.hust.hml.examplesforml
import org.apache.spark.ml.clustering.{KMeans, LDA}
import org.apache.spark.SparkConf
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.SparkSession
import scala.util.Random
object kmeans1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("iris")
val spark = SparkSession.builder().config(conf).getOrCreate()
val file = spark.read.format("csv").load("D:\\9-1kmeans\\iris.data")
file.show()
import spark.implicits._
val random = new Random()
val data = file.map(row => {
val label = row.getString(4) match {
case "Iris-setosa" => 0
case "Iris-versicolor" => 1
case "Iris-virginica" => 2
}
(row.getString(0).toDouble,
row.getString(1).toDouble,
row.getString(2).toDouble,
row.getString(3).toDouble,
label,
random.nextDouble())
}).toDF("_c0", "_c1", "_c2", "_c3", "label", "rand").sort("rand")
val assembler = new VectorAssembler()
.setInputCols(Array("_c0", "_c1", "_c2", "_c3"))
.setOutputCol("features")
val dataset = assembler.transform(data)
val Array(train, test) = dataset.randomSplit(Array(0.8, 0.2))
train.show()
val kmeans = new KMeans().setFeaturesCol("features").setK(3).setMaxIter(20)
val model = kmeans.fit(train)
model.transform(train).show()
}
}
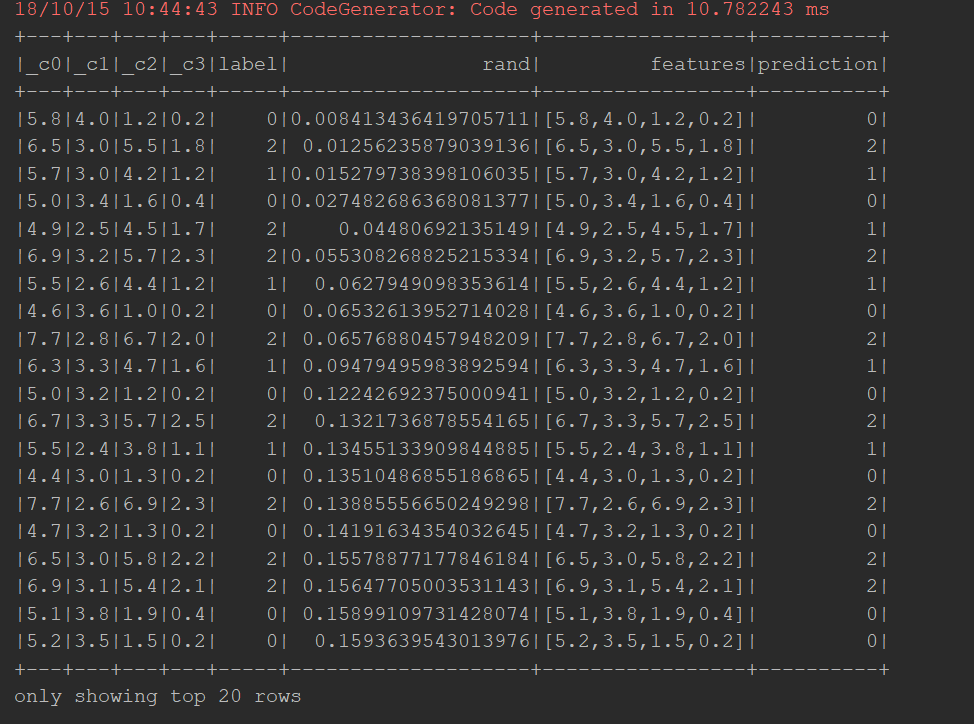
输出结果
掌握Spark机器学习库-09.3-kmeans算法实现分类的更多相关文章
- 掌握Spark机器学习库-09.6-LDA算法
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-07-线性回归算法概述
1)简介 自变量,因变量,线性关系,相关系数,一元线性关系,多元线性关系(平面,超平面) 2)使用线性回归算法的前提 3)应用例子 沸点与气压 浮力与表面积
- 掌握Spark机器学习库-08.7-决策树算法实现分类
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.Spark ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- UCI机器学习库和一些相关算法(转载)
UCI机器学习库和一些相关算法 各种机器学习任务的顶级结果(论文)汇总 https://github.com//RedditSota/state-of-the-art-result-for-machi ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- 掌握Spark机器学习库-07.14-保序回归算法实现房价预测
数据集 house.csv 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-08.2-朴素贝叶斯算法
数据集 iris.data 数据集概览 代码 import org.apache.spark.SparkConf import org.apache.spark.ml.classification.{ ...
- 掌握Spark机器学习库-07-回归算法原理
1)机器学习模型理解 统计学习,神经网络 2)预测结果的衡量 代价函数(cost function).损失函数(loss function) 3)线性回归是监督学习
随机推荐
- Servlet学习总结,为理解SpringMVC底层做准备
Servlet 一句话概括 :处理web浏览器,其他HTTP客户端与服务器上数据库或其他应用交互的中间层 Servlet 生命周期 : 1.类加载, 2.实例化并调用init()方法初始化该 Serv ...
- Codeforces Round #412 (rated, Div. 2, base on VK Cup 2017 Round 3) E. Prairie Partition 二分+贪心
E. Prairie Partition It can be shown that any positive integer x can be uniquely represented as x = ...
- 可以声明接口,但不可以new接口
接口是一种特殊的抽象类,它包含常量和方法的声明,但没有方法的实现:可以把接口看成是一种特殊的抽象类: 接口实质上是一种规范,它关心的是"做什么",不关心"怎样做" ...
- Linux 下的编辑/编译器
linux 首先有两个重量级的文本编辑器:vim 和 emacs 此外有如下三种比较好的开放环境: 1.Anjuta Anjuta DevStudio 的官方地址:http://anjuta.sour ...
- 基于字符的打印机 图形化打印机 PostScript解释器
60行*80字符/行=4800字节 300点/英寸(300DPI) 8*10英寸/页打印区域 光栅图像处理器 RIP PostScript程序--- > PostScript解释器 --& ...
- 设置一个DIV块固定在屏幕中央(两种方法)
设置一个DIV块固定在屏幕中央(两种方法) 方法一: 对一个div进行以下设置即可实现居中. <style> #a{ position: fixed; top: 0px; left: 0p ...
- (13)javaWeb中HttpServletRequest详解
关于HTTP请求和响应,可以参考 HTTP协议 系列文章 导学,请求概述: a,GET和POST请求报文格式: b,常见的请求头 在servlet中,相应的doGet方法和doSet方法中的reque ...
- 珠海鼎芯(D-Chip)IMX6读取CPU的UID的方法【转】
本文转载自:http://blog.csdn.net/williamdedong/article/details/52712084 在使用IMX6板子的时候,有时会想着是否可以把板子搞一个唯一标识呢, ...
- spring-boot快速搭建解析
创建方式: 1.在File菜单里面选择 New > Project,然后选择Spring Initializr: 2.使用maven直接构建,添加依赖. 1 2 3 4 pom.xml:Mave ...
- 【HDU 1561】 The More,The better
[题目链接] 点击打开链接 [算法] 树形背包 注意是一棵森林 [代码] #include<bits/stdc++.h> using namespace std; #define MAXN ...